 WongKinYiu
commented
2 years ago
WongKinYiu
commented
2 years ago Could you provide your training/deploy cfg.
Open mickey-cool opened 2 years ago
WongKinYiu
commented
2 years ago Could you provide your training/deploy cfg.
 mickey-cool
commented
2 years ago
mickey-cool
commented
2 years ago Training cfg is ./cfg/train/yolov7-tiny.yaml, deploy cfg is ./cfg/deploy/yolov7-tiny-silu.yaml
WongKinYiu
commented
2 years ago They use different activation function, please use ./cfg/deploy/yolov7-tiny.yaml for deploy ./cfg/train/yolov7-tiny.yaml trained model.
mickey-cool
commented
2 years ago They use different activation function, please use ./cfg/deploy/yolov7-tiny.yaml for deploy ./cfg/train/yolov7-tiny.yaml trained model.
I tried ./cfg/deploy/yolov7-tiny.yaml , but I got very similar result : tons of boxes
 LingCoderSonoscape
commented
1 year ago
LingCoderSonoscape
commented
1 year ago They use different activation function, please use ./cfg/deploy/yolov7-tiny.yaml for deploy ./cfg/train/yolov7-tiny.yaml trained model.
I tried ./cfg/deploy/yolov7-tiny.yaml , but I got very similar result : tons of boxes
Hi, have you solved the problem? I met the same phenomenon when I reparameterized my custom yolov7-w6 model. Tons of boxes appeared.
 s2244521
commented
12 months ago
s2244521
commented
12 months ago I met the same problem too😥
 ArjanJawahier
commented
10 months ago
ArjanJawahier
commented
10 months ago If you don't strip the optimizer using utils/general.py strip_optimizer, the reparameterized model will have different outputs. So if you're training a Yolov7 model and you want to reparameterize before the end of the training, you should run strip_optimizer first.
After reparametrization of yolov7-tiny, more bboxes came out, and confidence boosted, any idea? Before:
After: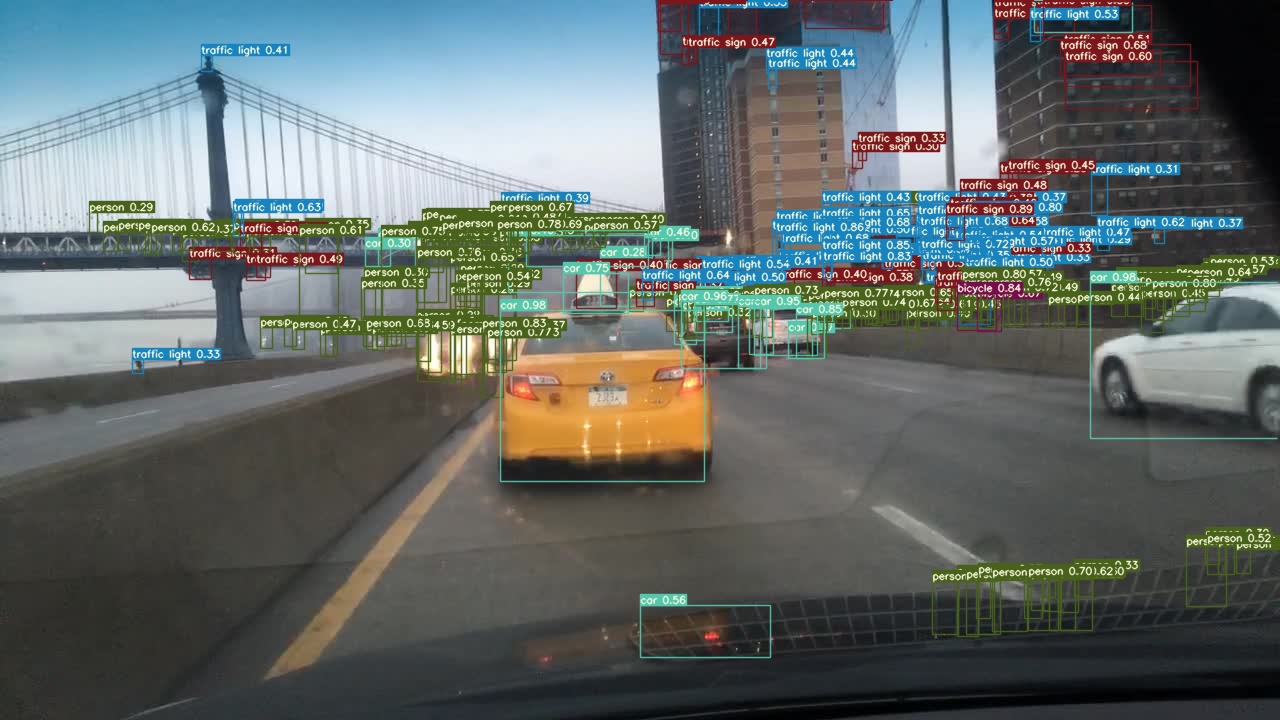
my reparemeterization code:
`# import from copy import deepcopy from models.yolo import Model import torch from utils.torch_utils import select_device, is_parallel import yaml
device = select_device('0', batch_size=1)
model trained by cfg/training/*.yaml
ckpt = torch.load('/media/coconut/codes/yolov7/runs/train/yolov7-tiny-custom/weights/best.pt', map_location=device)
reparameterized model in cfg/deploy/*.yaml
model = Model('/media/coconut/codes/yolov7/cfg/deploy/yolov7-tiny-silu.yaml', ch=3, nc=10).to(device)
with open('/media/coconut/codes/yolov7/cfg/deploy/yolov7-tiny-silu.yaml') as f: yml = yaml.load(f, Loader=yaml.SafeLoader) anchors = len(yml['anchors'][0]) // 2
copy intersect weights
state_dict = ckpt['model'].float().state_dict() exclude = [] intersect_state_dict = {k: v for k, v in state_dict.items() if k in model.state_dict() and not any(x in k for x in exclude) and v.shape == model.state_dict()[k].shape} model.load_state_dict(intersect_state_dict, strict=False) model.names = ckpt['model'].names model.nc = ckpt['model'].nc
reparametrized YOLOR
for i in range((model.nc+5)anchors): model.state_dict()['model.77.m.0.weight'].data[i, :, :, :] = state_dict['model.77.im.0.implicit'].data[:, i, : :].squeeze() model.state_dict()['model.77.m.1.weight'].data[i, :, :, :] = state_dict['model.77.im.1.implicit'].data[:, i, : :].squeeze() model.state_dict()['model.77.m.2.weight'].data[i, :, :, :] = state_dict['model.77.im.2.implicit'].data[:, i, : :].squeeze() model.state_dict()['model.77.m.0.bias'].data += state_dict['model.77.m.0.weight'].mul(state_dict['model.77.ia.0.implicit']).sum(1).squeeze() model.state_dict()['model.77.m.1.bias'].data += state_dict['model.77.m.1.weight'].mul(state_dict['model.77.ia.1.implicit']).sum(1).squeeze() model.state_dict()['model.77.m.2.bias'].data += state_dict['model.77.m.2.weight'].mul(state_dict['model.77.ia.2.implicit']).sum(1).squeeze() model.state_dict()['model.77.m.0.bias'].data = state_dict['model.77.im.0.implicit'].data.squeeze() model.state_dict()['model.77.m.1.bias'].data = state_dict['model.77.im.1.implicit'].data.squeeze() model.state_dict()['model.77.m.2.bias'].data *= state_dict['model.77.im.2.implicit'].data.squeeze()
model to be saved
ckpt = {'model': deepcopy(model.module if is_parallel(model) else model).half(), 'optimizer': None, 'training_results': None, 'epoch': -1}
save reparameterized model
torch.save(ckpt, 'cfg/deploy/yolov7tiny_re.pt')`