 Wunder2dream
commented
4 years ago
Wunder2dream
commented
4 years ago -
Reinforcement learning vs. supervised learning
Supervised learning is learning from a training set of labeled examples provided by a knowledgable external supervisor. Each example is a description of a situation together with a specification—the label—of the correct action the system should take in that situation, which is often to identify a category to which the situation belongs.
Reinforcement learning: In interactive problems it is often impractical to obtain examples of desired behavior that are both correct and representative of all the situations in which the agent has to act. In RL, an agent must be able to learn from its own experience.
-
RL vs. unsupervised learning
Unsupervised learning: is typically about finding structure hidden in collections of unlabeled data. The terms supervised learning and unsupervised learning would seem to exhaustively classify machine learning paradigms.
RL: Uncovering structure in an agent's experience can certainly be useful in reinforcement learning, but by itself does not address the reinforcement learning problem of maximizing a reward signal.
 git-thor
git-thor
 The backup diagrams of n-step methods. These methods form a spectrum ranging from one-step TD methods to Monte Carlo methods.
The backup diagrams of n-step methods. These methods form a spectrum ranging from one-step TD methods to Monte Carlo methods.



 Notes:
If t + n >= T (if the n-step return extends to or beyond termination), then all the missing terms are taken as zero, and the n-step return defined to be equal to the ordinary full return
Notes:
If t + n >= T (if the n-step return extends to or beyond termination), then all the missing terms are taken as zero, and the n-step return defined to be equal to the ordinary full return 



 我们使用n -step TD方法来估计一个随机行走问题的值.
通过grid search得到不同学习步长 alpha 和step n 对应的误差。可以看到当 n 取到中间值时,误差最小,再一次说明无论是MC还是TD(0),这种处于极端情况的方法,效果都不太好。
我们使用n -step TD方法来估计一个随机行走问题的值.
通过grid search得到不同学习步长 alpha 和step n 对应的误差。可以看到当 n 取到中间值时,误差最小,再一次说明无论是MC还是TD(0),这种处于极端情况的方法,效果都不太好。






 同Sarsa和expected Sarsa的区别一样,我们只是将更新目标的最后一项换成期望值
如果s是terminal,它的期望是0
同Sarsa和expected Sarsa的区别一样,我们只是将更新目标的最后一项换成期望值
如果s是terminal,它的期望是0 In order to use the data from b we must take into account the difference between the two policies, using their relative probability of taking the actions that were taken
the value function is,
In order to use the data from b we must take into account the difference between the two policies, using their relative probability of taking the actions that were taken
the value function is,





 Hanging off to the sides of each state are the actions that were not selected. (For the last state, all the actions are considered to have not (yet) been selected.) Because we have no sample data for the unselected actions, we bootstrap and use the estimates of their values in forming the target for the update.
In the tree-backup update, the target includes all these things plus the estimated values of the dangling action nodes hanging off the sides, at all levels. This is why it is called a treebackup
update; it is an update from the entire tree of estimated action values.
Hanging off to the sides of each state are the actions that were not selected. (For the last state, all the actions are considered to have not (yet) been selected.) Because we have no sample data for the unselected actions, we bootstrap and use the estimates of their values in forming the target for the update.
In the tree-backup update, the target includes all these things plus the estimated values of the dangling action nodes hanging off the sides, at all levels. This is why it is called a treebackup
update; it is an update from the entire tree of estimated action values.





What to Learn in Model-Free RL
some basic concepts
(In other words) it directly learns a policy which gives you decisions about which action to take in some state.
There are few approaches for solving these kind of problems
Monte-Carlo Policy Evaluation
There are two diferent types of MC Policy Evaluation
Monte-Carlo Control
Exploration/Exploitation trade off
How can they learn about the optimal policy while behaving according to an exploratory policy? 1)The on-policy approach in the preceding section is actually a compromise—it learns action values not for the optimal policy, but for a near-optimal policy that still explores. 2)The off-policy learning: Use two policies, one that is learned about and that becomes the optimal policy(target policy), and one that is more exploratory and is used to generate behavior(behavior policy)
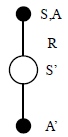
Sarsa( state-action-reward-state-action): On-policy TD Control Sarsa is an on-policy TD control method. In the previous section we considered transitions from state to state and learned the values of states. Now we consider transitions from state–action pair to state–action pair, and learn the values of state–action pairs. here the TD error
here the TD error
 The backup diagram for Sarsa is as shown as below,
The backup diagram for Sarsa is as shown as below,
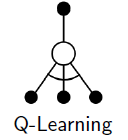
Q-Learning: Off- policy TD Control An off-policy TD control algorithm, defined by the target policy(learned action-value function) directly aproximates , independent of the behaviour policy.
The backup diagramm for Q-learning is
the target policy(learned action-value function) directly aproximates , independent of the behaviour policy.
The backup diagramm for Q-learning is
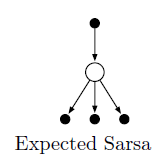
Expected Sarsa Similar to Q-learning Instead of using the maximum over next state–action pairs it uses the expected value, taking into account, The backup diagramm for Q-learning is
The backup diagramm for Q-learning is
Frage: How can we understand the exploration start in MC control? How can we understand bootstrap in RL ? Is Backup the same as bootstrap?