XFeiF
commented
3 years ago
XFeiF
commented
3 years ago TEN QUESTIONS
1. What is the problem addressed in the paper?
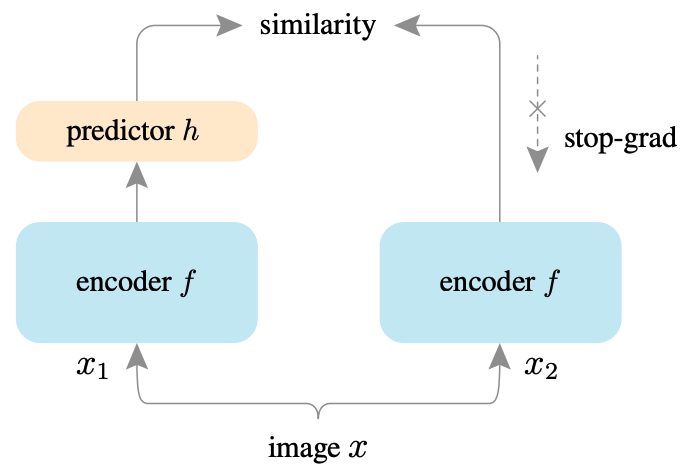
The proposed SimSiam does not need:(i) negative sample pairs, (ii) large batches, (iii) momentum encoders, while can learn meaningful representations. It uses a stop-gradient operation to prevent the siamese network from collapsing to a constant solution. The SimSiam method achieves competitive results on ImageNet and downstream tasks.
As shown in the architecture above, two augmented views of one image are processed by the same encoder network f (a backbone plus a projection MLP). Then a prediction MLP h is applied on one side, and a stop-gradient operation is applied on the other side. The model maximizes the similarity between both sides. It uses neither negative pairs nor a momentum encoder.
2. Is this a new problem? It is not a new problem (preventing collapsing). But it motivates us to rethink the roles of Siamese architectures for unsupervised representation learning. Negative pairs may not be necessary. The stop-gradient operation is pretty ridiculous that it is as powerful as the SwAV clustering or BYOL moving target. SimSiam challenges the cole role of Siamese architectures in SimCLR, SwAV and BYOL.
3. What is the scientific hypothesis that the paper is trying to verify? The simple siamese network is another different solution for self-supervised representation learning. It does not need (i) negative sample pairs, (ii) large batches, (iii) momentum encoders.
4. What are the key related works and who are the key people working on this topic?
Key related works: self-supervised representation learning, MoCo, SimCLR, BYOL, SwAV
Key people: the authors(Xinlei Chen, Kaiming He), Hinton etc.
5. What is the key to the proposed solution in the paper? The prediction head h and the stop-gradient operation are keys to the proposed method.
6. How are the experiments designed?
The ablation study includes: (a)Stop-gradient, (b) Predictor, (c) Batch Size, (d)Batch Normalization, (e)Similarity Function, (f)Symmetrization, (g)Output dimension.
The comparison study includes: (i)Comparison with SoTA methods on classification and transferring learning, (ii)Comparison with different architectures (SimCLR, SwAV, BYOL).
7. What datasets are built/used for the quantitative evaluation? Is the code open-sourced?
ImageNet-1k, CoCo object detection.
Code will be available soon.
8. Is the scientific hypothesis well supported by evidence in the experiments?
The predictor h and stop-gradient are fully studied in the ablation study and their hypothesis part. They are keys to the SimSiam arch.
The combination with SimCLR implies that SimSiam(the stop-gradient and predictor h) is independent of methods like SimCLR since there is not boost or decay in accuracy.
9. What are the contributions of the paper? It motivates us to rethink the roles of Siamese architectures for unsupervised representation learning. Negative pairs may not be necessary. The stop-gradient operation is pretty ridiculous that it is as powerful as the SwAV clustering or BYOL moving target. SimSiam challenges the cole role of Siamese architectures in SimCLR, SwAV and BYOL.
10. What should/could be done next?
What's your opinion?
Paper