 XFeiF
commented
3 years ago
XFeiF
commented
3 years ago 这篇文章将Video Playback Rate Perception(PRP,也就是视频播放“速度”)作为信号,首先通过feature encoder获取特征,接着分别通过:
- 判别式感知模型(Discriminative perception model,fc)对不同temporal resolution (speed/playback rate) 的视频进行分类,倾向于感知低时间分辨率和长期表征。
- 生成式感知模型 (Generative perception model, decoder) 充当解码器,通过引入运动注意力机制专注于理解高时间分辨率和短期表征。通过这个模块,PRP从高播放速度的视频中重构低播放速度的视频。即,生成中间缺失的帧,需要注意的是这里并不是全部生成,而是以重构率$r$生成。 二者结合使得PRP可以同时兼顾 long-short term representation 的学习。
时间分辨率(temporal resolution)的高低对应播放速度的快慢。时间分辨率低,播放速度慢;时间分辨率高,播放速度快。
长期表征表示global的特征,短期表征表示local (frame-level) 的特征。判别式感知模型从整体特征出发对 playback rate 进行分别,所以是长期表征。生成式感知模型通过重点重构attention map的区域,关注如何将中间缺少的帧勾勒出来,因此是短期表征。
 .
.
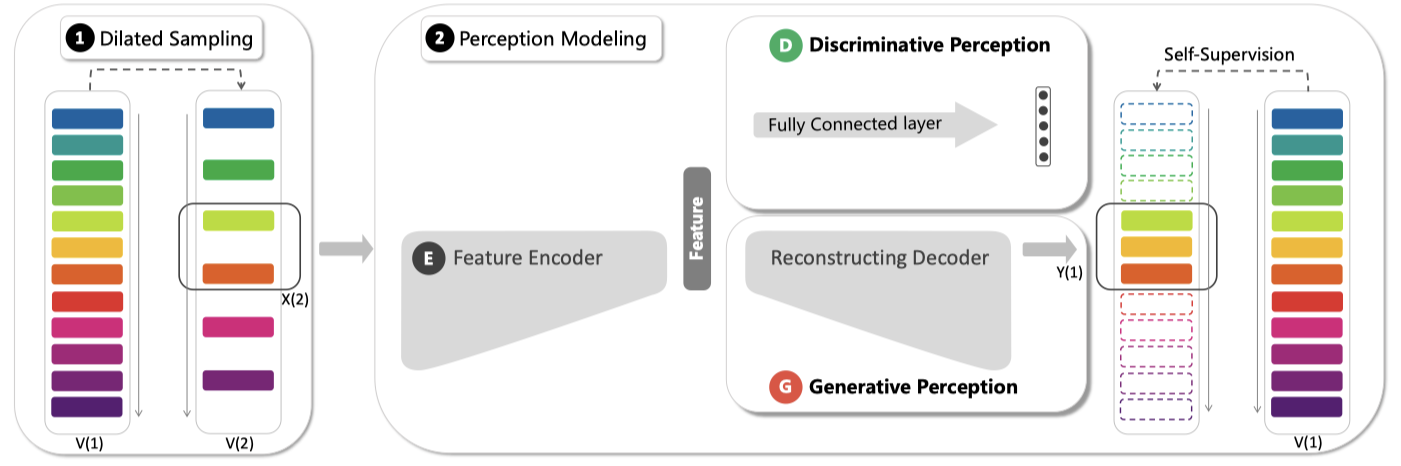
上图是PRP的流程示意图。主要包含Dilated sampling空洞采样,和感知建模两部分。
- 空洞采样通过每隔 $s$ 个帧采样一帧的方式得到playback rate是 $s$ 的序列,之后从该序列中连续采样 $l$ 帧构成输入。图中第一部分以 $s=2, l=2$ 得到输入 $X$。
- 感知建模则由上文所说的判别式感知模型和生成式感知模型组成。二者共享Feature Encoder。
- 监督信号由两部分组成。首先是playback rate $s$,其次是生成模型损失函数中需要的ground truth $Y$。$Y$也可以从原始video中采样得到。
下图是PRP的模型结构图。文章在三种不同的backbone network ( C3D, R3D, R(2+1)D )上进行实验。可以看到它的loss由两部分组成,DP (Discriminative Perception) Loss, GP(Generative Perception) Loss。
 .
.
- DP Loss:简单的cross-entropy loss。
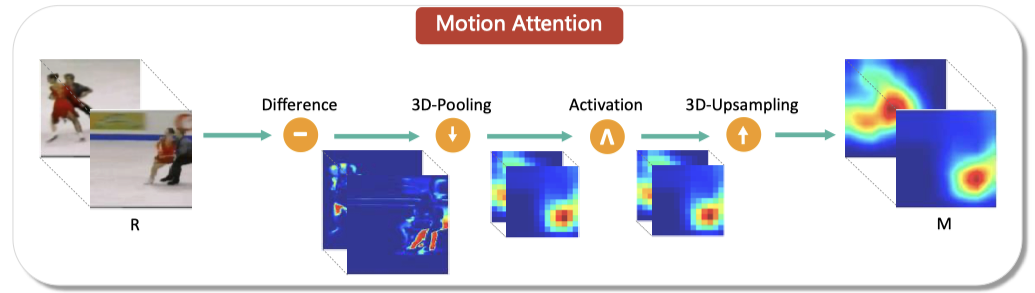
- GP Loss: 一般MSE用于reconstruction的loss。本文为了强调motion信息,构建了使用motion attention 正则化的MSE(m-MSE)loss。motion attention不依赖于神经网络,只从输入的RGB图像中获得,其构建方式如下:
 .
.
- Difference: 网络输入的clip作为输入,计算相邻帧像素之间的差的平方。
- 3D-Pooling:由于difference map容易被噪音和缺失的静态前景信息影响,用一个3D的spatial-temporal filter使它保持前景信息一致性,并抑制 spatial-temporal 的噪音。
- Activation:一个activation function用于将difference map上的像素误差映射到$[\lambda_1, \lambda_2], 0\leq \lambda_1 \leq 1, 1 \leq \lambda_2$。
- 3D-Unsampling:将motion attention map 放缩到输入图像大小。 计算时,将motion attention map作为MSE的权重。
- 最终的loss = 0.1DP_loss + GP_loss.
实验在UCF101和HMDB51数据集上测试action classification和video retrieval的性能。
Ablation Study得出速度$s \in {1,2,4,8}$中最好,重构率$r=2$。
最终性能上,UCF101 (C3D 69.1%, R3D 66.5%, R(2+1)D 72.1%)。
总的来说,这篇文章阐述“速度”的角度、说法与前面的文章差别较大,它用“Video playback rate"来代替速度一词。从创新角度来看,主要是multi-task(discriminative + generative),以及motion attention map的实现。
Paper
Code
Authors:
Yuan Yao, Chang Liu, Dezhao Luo, Yu Zhou, Qixiang Ye