 XFeiF
commented
3 years ago
XFeiF
commented
3 years ago 这篇文章单纯就是只依赖Contrastive Learning,但是它深度挖掘了在视频自监督学习中“好”的数据增强方法。
首先,为了挖掘spatiotemporal的特征,作者设计了Temporal Augmentation和Temporal consistent spatial augmentation这两种增强方式。前者专注于采样技巧,如何构造来自同一video的两个不同clip作为正样本对十分重要。后者对则提出一个和前文(Pace Prediction@ECCV2020)不同的观点,他们认为需要做group spatial augmentation,而不是可能会破坏监督信息的frame-level的。
实验性能,利用K400作为pretrain的性能也达到了2020年最好的 (应该是吧)。
 .
.
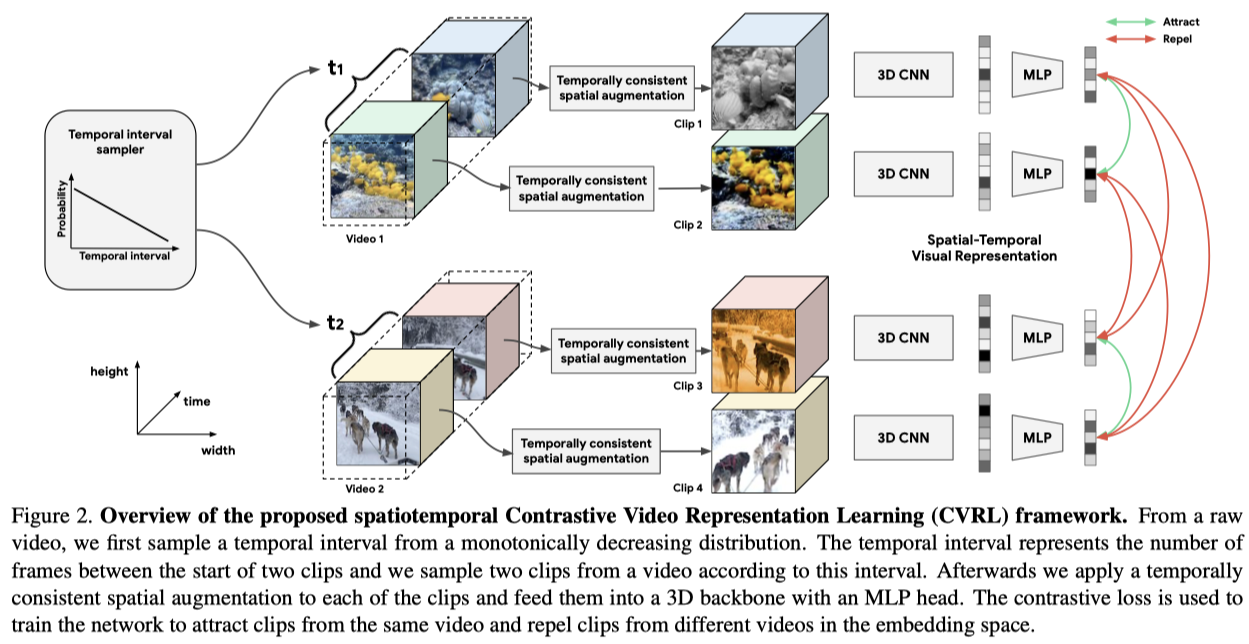
模型的整体框架如上。
首先是一个 temporal interval sampler,它的基本思想是:来自同一个video的两个clip如果在时序上间隔较大,那么它们就会更独立(不同 -> 对比损失难以拉近其特征)。如果能够以较小的概率采样到大时序间隔的clip,对比损失就可以关注到时序上较近的clip,使得它们的特征更近,且在大时间间隔的clip上只引入较少的惩罚。具体实现中,作者通过对两个clip的起始帧的时间间隔 $t$ 建模。实验中作者构造了多个采样函数发现,概率随着间隔 $t$ 的增大而减小时性能较好。
接着是一个时序一致的 spatial augmentation,其实就是group augmentation,对一个clip里的每一帧都采取同样的变换。
之后先接一个3D CNN作为backbone提取特征,该特征再经过一个projection head,用最后得到的特征向量构造对比损失。
Positive pairs:同一video不同clip不同的spatial augmentation;
Negative pairs:不属于同一video的所有clip对。
实验方面:
- Linear evaluation:fix backbone,MLP用了3个隐藏层,使用R3D-50作为backbone,分别在Kinetics-400/600上取得66.1%,70.4%的Top1准确率。
- semi-supervised learning:分别在1%和10%的有label的数据上进行,这时的性能下界是只用带标签数据训练的supervised方法(3.2, 39.6),和两个baseline相比,该方法性能高出很多(+31.9, +18.5)。但是半监督很少用来测试,目前只见到这篇文章有用到。
- action classification: R3D-50, K400上预训练,fine-tune所有层,在UCF,HMDB训练,top1 acc性能别分92.2, 66.7。
- action detection:在AVA数据集上与baseline和supervised 方法比较。
- ablation study: 时序间隔采样分布函数;时间与空间数据增强方式;projection head隐藏层数量;batch size;pretrain epoch数量(在K400上,800最佳,和200比提高了2.3)。
总的来说,这篇文章思路清晰(同时也可能被抨击novelty不够),实现简单,但是细节很多,耗费算力也很大,在K400/K600 预训练800个epoch就难住了太多实验室了。可以用这篇文章的方法在低配置条件下得到一个不错的baseline。(代码未开源。)
Paper
No official code available now~
Authors: Rui Qian, Tianjian Meng, Boqing Gong, Ming-Hsuan Yang, Huisheng Wang, Serge Belongie, Yin Cui