XFeiF
commented
3 years ago
XFeiF
commented
3 years ago Highlight:
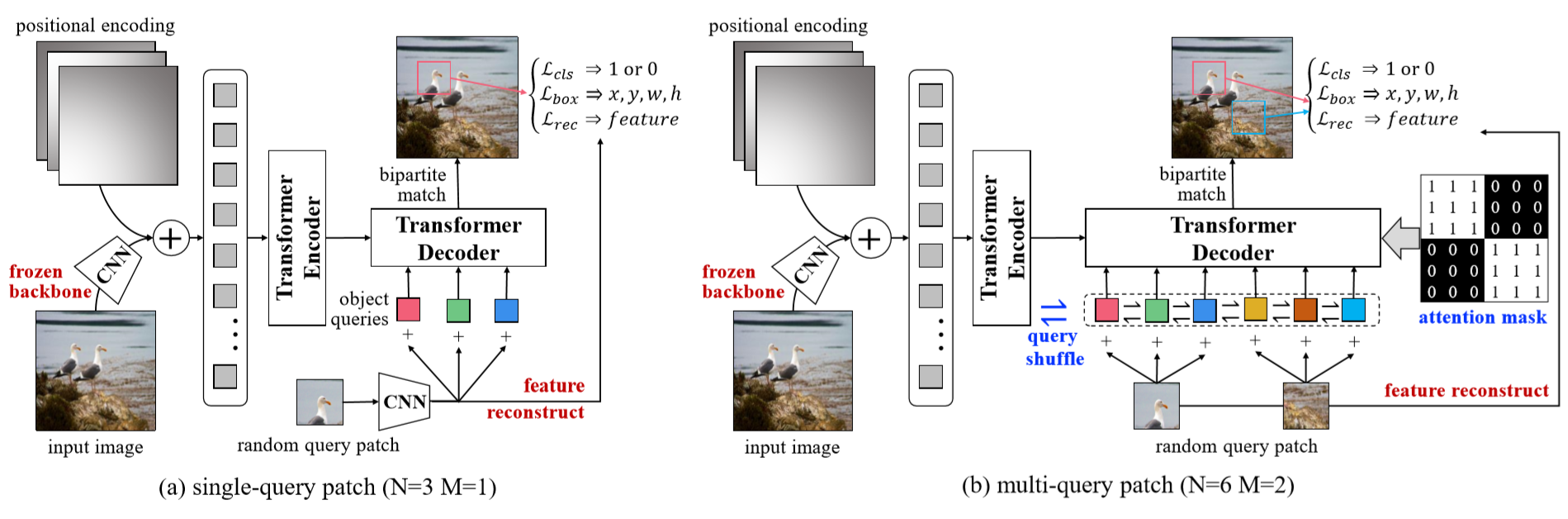
The proposed UP-DETR framework aims to Unsupervisedly Pre-train the transformers of DETR. The main tasks of object detection are object classification and localization. However, the DETR transformer focuses on spatial localization learning. So the problem comes that how to maintain the image classification ability. Based on this finding, the authors make the following contributions:
- Multi-task learning: they introduce frozen pre-training backbone and patch feature reconstruction to preserve the feature discrimination of transformers. (I think this part acts like a penalization term to help the transformer keep the important discriminative information extracted by the pre-trained backbone.)
- Multi-query localization: object query shuffle + attention mask, while the former part is the most important. The intuition is: for general object detection, there are multiple object instances in each image. Besides, single-query patch may result in convergence difficulty when the number of object queries is large.
The entire framework:
- A frozen CNN backbone is used to extract a visual representation with the feature map f of an input image.
- The feature map is added with positional encodings and passed to the multi-layer transformer encoder in DETR.
- For the random cropped query patch, the CNN backbone with global average pooling extracts the patch feature p, which is flattened and supplemented with object queries q before passing it into a transformer decoder.
- Query feature q of patch p in the image feature k.
The loss function is formed by three parts:
- The classification loss of matching the query or not.
- The regression loss of bounding-box.
- The reconstruction loss of (discriminative image) feature preservation.
Paper
Code-pytorch
Authors:
Zhigang Dai, Bolun Cai, Yugeng Lin, Junying Chen
The Chinese explanation from the author Zhigang Dai in Zhihu.
The framework of the proposed UP-DETR.