 XFeiF
commented
4 years ago
XFeiF
commented
4 years ago 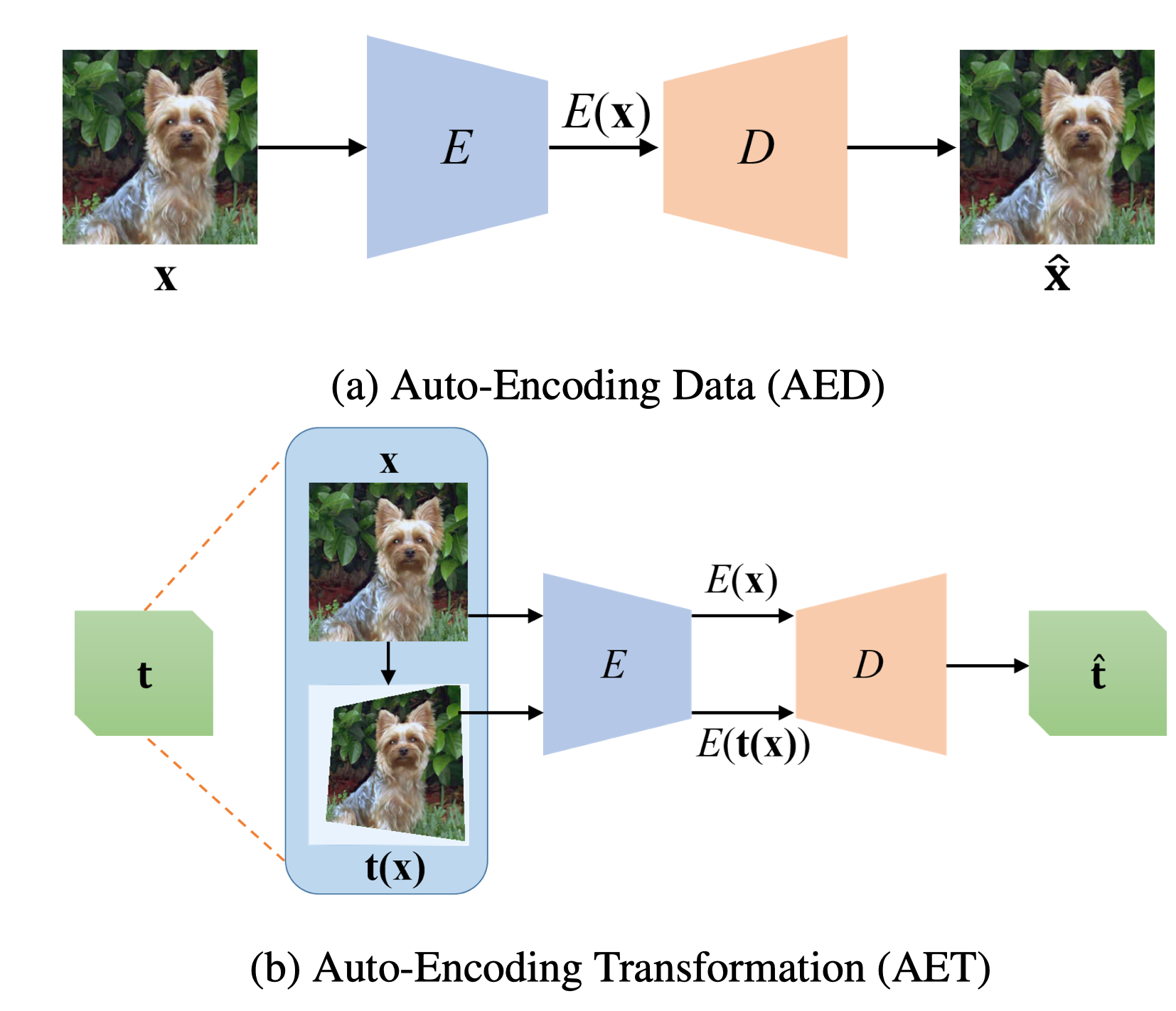
AET attempts to estimate the input transformation rather than the data at the output end. This forces the encoder network E to extract the features that contain the sufficient information about visual structures to decode the input transformation.
paper && code
Main idea:
As long as the unsupervised features successfully encode the essential information about the visual structures of original and transformed images, the transformation can be well predicted.
Highlight
The authors present a novel paradigm of unsupervised representation learning by Auto-Encoding Transformation(AET) in contract to the conventional Auto-Encoding Data(AED).
This AET paradigm allows us to instantiate a large varity of transformations, from parameterized, to non-parameterized and GAN-induced ones.
AET sets new SoTA performances being greatly closer to the upper bounds by their fully supervised counterparts on CIFAR-10, ImageNet and Places dataset.
AED is based on the idea of reconstrcting input data at the output end. It means a good feature representation should contain sufficient information to reconstruct the input data.
AET focuses on exploring dynamics of feature representations under different transformations, thereby revealing not only static visual structures but also how they would change by applying different transformations.
AET is kind of summary and sublimation of previous AED methods.