 XifengGuo
commented
6 years ago
XifengGuo
commented
6 years ago @vandana-rajan We use model.fit(X,Y) to train a one-in-one-out model and model.fit([X1,X2], [Y1,Y2]) to train two-in-two-out model. The Capsnet model two-in-two-out, so the inputs=[X1,X2]=[x_train, y_train] and the outputs (also the targets)=[Y1,Y2]=[y_train,x_train].
Please refer to https://keras.io/getting-started/functional-api-guide/#multi-input-and-multi-output-models for more details.
 vandana-rajan
vandana-rajan JoyJulianGomes
JoyJulianGomes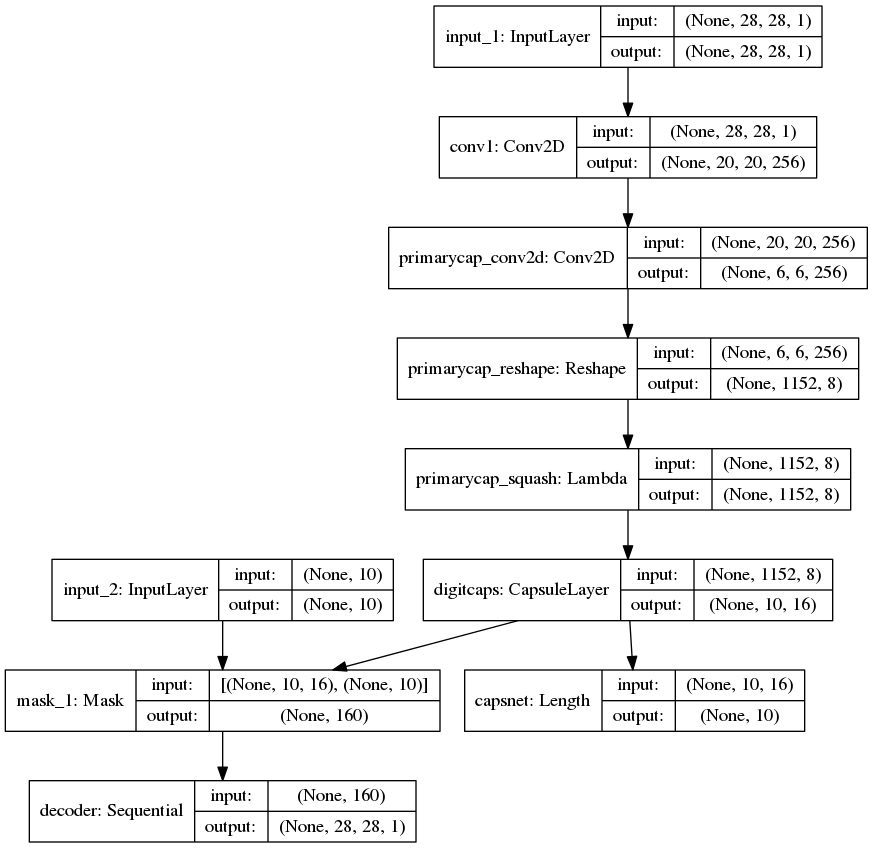 you can see there are two inputs input_1 and input_2 and two outputs decoder_sequential and capsnet, hence two-in-two-out model
you can see there are two inputs input_1 and input_2 and two outputs decoder_sequential and capsnet, hence two-in-two-out model
In the 'train' function, why is data given as [x,y],[y,x]? For example,
I am new to Keras framework. Please help me understand why data is given like this.