 dbishop
commented
4 years ago
dbishop
commented
4 years ago Re: the do_context_push=False hack I did, e.g.:
span_ctx = api.ezipkin_client_span(
api.default_service_name(), span_name=self._method,
binary_annotations={'http.uri': self.path},
do_context_push=False, # <==== XXX HACK
)I think PR #145 lays the groundwork for us being able to create an eventlet-aware version of code that works right in our use-case without that nasty do_context_push=False hack.
 drolando
drolando
Hi! I will explain the general situation, how we want the Trace's data in Zipkin to look, then detail the horrible hacks we had to do in order to achieve what we wanted. Finally, I'll ask for advice; is there a better technique to get what we want? Should we want something different?
When instrumenting an eventlet WSGI application (OpenStack Swift), I ran across a funny problem. (I'll be only addressing Python 2.7 here, but Swift and any tracing solution also need to support Py3)
We have a proxy-server that fires off multiple concurrent client requests to backend servers. At a low enough level each one is using eventlet-greened stdlib
httplib.HTTPConnection,httplib.HTTPResponse, etc. To catch the beginning of outbound HTTP requests, we monkey-patchhttplib.HTTPConnection.endheaders()like so:We catch the point where the remote service has delivered response headers by monkey-patching
httplib.HTTPResponse.begin()like so:Finally, the client span for each request is closed via a monkey-patched
httplib.HTTPResponse.closethat looks like this:As an example, here's what a trace that I like looks like in the Zipkin Lens UI for the GET of an erasure-coded object that requires data from 4 different backend storage servers: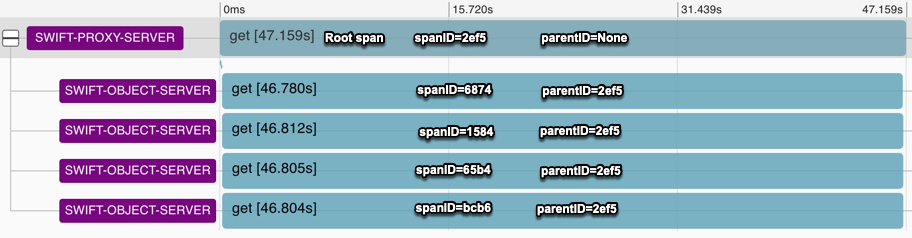
Here's detail of the first subrequest (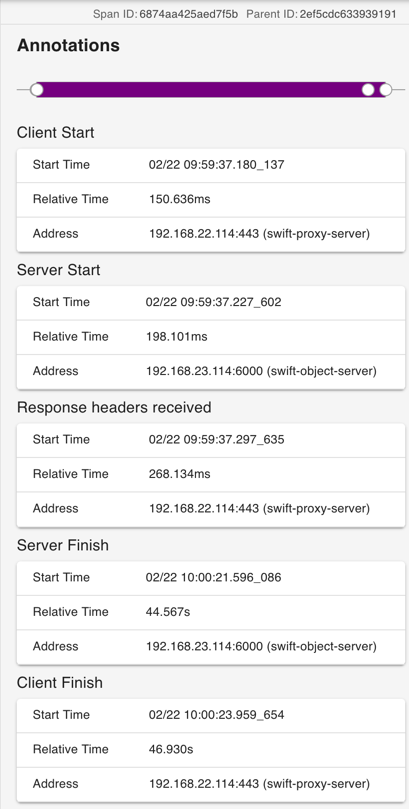
SpanID=6874) with all the Annotations as I expect them. A wrapping Client Start/Client Finish with local_endpoint sayingswift-proxy-server, a Server Start/Server Finish with local_endpoint sayingswift-object-server. And a "Response headers received" annotation logged on theswift-proxy-server. Tags (not shown) for the whole span (SpanID=6874) includeServer Address = IP:PORT (swift-object-server), aclient.pid = [proxy-server PID], aworker.pid = [swift-object-server PID], andClient Address = IP:PORT (swift-proxy-server):Finally, here's the JSON for the whole erasure-coded object GET trace to just cover all the details for which screenshots would be too unwieldy: 5e516c09f4985b19706ef268aee15ed1.json.txt
Okay, so that's how I want these subrequests to get tracked and look like. Thanks for reading this far! For reference, below, the
apimodule you will see is from aswift_zipkinpackage, and contains an opinionated set of subclasses ofzipkin_spanand helper functions. The quoted code below has been edited for brevity.Now the problem is the horrible hacks I had to go through to get the data above to look how I want. Here's what we actually had to do in the monkey-patched
httplib.HTTPConnection.endheaders(),httplib.HTTPResponse.begin()andhttplib.HTTPResponse.close()functions.endheaders()
When it's time for the monkey-patched HTTPRespone.begin() and close() methods to operate on their correct
span_ctxinstance, they retrieve it like this:So there's two problems we had to overcome (the solution to the first created a third problem).
First, if you fire of concurrent spans like this:
then the 2nd span will have a ParentID of
span_ctx1instead of the parent ofspan_ctx1. In other words,span_ctx1andspan_ctx2should be sibling leaves in the span tree and have the same ParentID. In the first screenshot, above, you can see all the SWIFT-OBJECT-SERVER spans sharing the ParentID of the root span.So we "solved" that by allowing
which keeps each created span context object's zipkin_attrs from getting pushed onto the tracer's
self._context_stack. That's howspan_ctx2ends up as a child of the same span thatspan_ctx1is a child of. However, this creates a problem of how to getspan_ctx1andspan_ctx2later. There can be arbitrarily many of these concurrent spans and the order of their creation and later accessing is different, so something like a stack is inadequate to store them. We "solved" that problem by storing the created span context objects in a process-global dictionary keyed by socket file descriptor.The second problem is that the
create_http_headers_for_this_span()API finds the zipkin_attrs on the tracer's stack, and because we suppress the pushing of those attrs onto the stack, they're not there. So we had to cook up a fake Stack, push the right attrs onto it, and hand that stack intocreate_http_headers_for_this_span(). Gross.Maybe this implies PR #142 isn't done and a
create_http_headers_for_this_span()function should just be a method onzipkin_span.Finally... help? Is this really the right thing to be doing? We're getting the results we want, as far as I can tell, but the mechanisms to get there do feel pretty gross. Am I missing something?