 ZhengZhenyu
commented
6 years ago
ZhengZhenyu
commented
6 years ago 普通用户能否看到错误堆栈?普通用户和管理员用户在查看错误任务的event详情时得到的结果相同吗?
Open Yikun opened 6 years ago
ZhengZhenyu
commented
6 years ago 普通用户能否看到错误堆栈?普通用户和管理员用户在查看错误任务的event详情时得到的结果相同吗?
ZhengZhenyu
commented
6 years ago 为什么两个更新动作的顺序是相反的?
 Yikun
commented
6 years ago
Yikun
commented
6 years ago @zhengzhenyu
普通用户能否看到错误堆栈?普通用户和管理员用户在查看错误任务的event详情时得到的结果相同吗?
不能,在2.51版本增加了限制,参考代码nova/api/openstack/compute/instance_actions.py#L142-L155,普通用户是无法看到traceback的。
为什么两个更新动作的顺序是相反的?
因为action和event并没有在SQLAlchemy注册relationship,即在UOW(Unit of Work)机制中,没有依赖能够保证他们的顺序,所以,更新顺序是不稳定的。
在SQLAlchemy里面,这些需要更新的对象也是通过无序的set来暂存的,有依赖的话,通过UOW来保证顺序,没有依赖,自然看到的是不稳定顺序。具体逻辑在这里:https://github.com/zzzeek/sqlalchemy/blob/b60461fb95bc78da16c5eb2948e1aff170b78bbc/lib/sqlalchemy/orm/unitofwork.py#L369-L391
 zh-f
commented
6 years ago
zh-f
commented
6 years ago N天之前看到了这篇文章,TL;DR,今天再次点进来发现干货满满呐。手动点赞!Bravo!
Yikun
commented
6 years ago @zh-f : ) 写完后才发现涉及的点太多了,以后尽量分开写。
 BZbyr
commented
6 years ago
BZbyr
commented
6 years ago 你好,想问一下,文中的图都是如何做的呀
本篇文章可以看做是一个问题定位、分析、学习过程的记录,介绍了OpenStack Nova一个死锁问题的分析和解决的过程,你将从本文了解到SQLAlchemy的session中的语序排序机制、OpenStack的死锁重试机制及改进点以及一些调试的手段。
0. 背景
在Nova对虚拟机进行一些操作的时候,比如创建、停止虚拟机之类的操作的时候,会将这些事件记录在instance_actions表里面记录操作的时间、操作类型以及一些操作事件详情。
例如,我们可以通过instnace-action-list来查看虚拟机的操作,并可以通过对应的req id来查操作中的事件详情,如果是失败的话,还可以从事件详情中,看到对应的错误栈信息。
在instance_action的表里面,记录着action的更新时间,比如event结束了,我们也期望能够action里面能记录update的时间,但是目前并没有进行刷新。
这个patch想做的事儿也比较简单,如上图所示,就是在event进行记录(比如开始和结束)的时候,也对action的更新时间也做刷新。也就是说,我们在写instance_event_action表后,也需要写instance_action表去记录下刷新时间。大致代码的关键逻辑如下所示(省略了一些无关的代码细节):
1. 起因
在修复Nova的这个事件时间刷新问题(bug/507473)的时候,CI会概率性地挂一些用例,先开始以为是CI不稳定,workflow+1之后,最终的门禁检查一直过不了。Matt recheck了几次都是失败的,然后问:
这才引起了我的注意,我找了下归档的日志发现:
第一反应是,我去!死锁了?简单的一个update怎么会死锁?确认了下where条件比较单一,并不是因为条件排序不稳定引起的死锁;也确认了下action数据库的索引,也比较简单,也不会有死锁问题。然后,就看业务代码,代码逻辑也很简单,一个事务里面包含了4件事,2个查询,2个刷新。不科学啊!
2. 发现
遇到这种活久见的问题,最好的办法就是把每一句SQL都dump出来,因为不是裸写SQL,鬼知道SQLAlchemy中间的ORM那层为我们做了什么。
OpenStack的oslo.db为我们提供了一个配置项:
把他设置成100就可以dump出执行的每一句SQL了,这个方法在我们进行调试的时候很方便。然后,进行复现,结果让我震惊了(问号脸???代码是一样的,生成SQL的顺序却是不一致的):
完整的SQL dump我贴在了paste/628609,可以分析出来,就是产生死锁的根本原因:在一个事务中,更新2个表的相反行。并发执行2个这样的事务,一个事务拿着action表的行锁,一个事务拿着action_event表的行锁,它们都互相等着对方释放,最终产生了死锁,如下图所示。
从MySQL官方DOC里,给的建议How to Minimize and Handle Deadlocks中,我们也看到了类似的建议:
核心意思就是说,我们在一个transaction中更新多个表的时候,或者说在一个表中更新不同行的时候,一定要保证每一次调用的顺序是一致的。最终,临时解决这个问题的方式也比较简单,就是在这个函数上加一个死锁重试装饰器,即在发生死锁的时候进行重试,CI终于全绿了。
3. 进一步分析
问题解决就结束了吗?不,2个疑问一直在心中徘徊:
3.1 oslo.db的死锁重试机制
这个问题的场景和上研的时候,在通信中搞的“退避算法”很类似(HINOC中信道接纳的时候,多个节点并行接纳时,如果发生冲突,需要退避重试),都是冲突避免,通信中是避免信道冲突,而这里则是避免数据库的死锁。
我们从oslo_db/api.py可以看到他的实现,原理比较简单,就是隔几秒(2的retry数次方秒),如果调用成功,就终止重试。伪代码大概如下:
虽然看着隔了一些时间,但是,这种指数递增的机制对于死锁这种问题没有什么卵用,大家一起等,然后再一起调,还是会再次产生死锁。对于这个问题,我提交了一个Patch对其进行优化,具体内容可以参考 #71 《oslo.db中的死锁重试机制优化》的详细分析。
3.2 SQLAlchemy Session中的排序机制
上文已经提到,造成死锁的根本原因实际上是在一个事务中,更新2个表的时候的顺序不一致。在并发调用的时候,产生了死锁。Python的代码是按顺序更新的(先更新event内容,再更新action),但是为什么SQLAlchemy产生的SQL是乱序的呢?
通过阅读SQLAlchemy的源码,最终找到了答案。先说结论:Session中的操作顺序,由UnitOfWork机制决定最终的调用顺序,如果没有依赖关系,最终执行顺序是不稳定的。
3.2.1. SQLAlchemy的缓存刷新机制
SQLAlchemy在进行数据刷新的时候,会有一个flush的过程(实现见lib/sqlalchemy/orm/session.py#def flush,这个过程会将所有的object的变化,刷新到数据库中。例如,会将插入、修改、删除,转换为INSERT、UPDATE、DELETE等操作。而刷新执行的顺序,是通过Session的"UNIT of Worker"依赖机制保证的。
我们可以从有SQLalchemy作者写的一篇关于其架构的文章《SQLAlchemy》中看到一些关于Session相关的数据结构:
Session维护着如上图所示的结构,在每次刷新的时候,会将object的变动刷新到数据库中。如作者所说说,flush这个函数可能是 SQLAlchemy最复杂的函数。
3.2.2. SQLAlchemy的UNIT of WORK机制
我们先看看来自作者的介绍:
UOW的工作主要是将session维护的new、dirty、deleted的集合清掉并落入数据库中。主要挑战就是决定正确的持久化步骤和顺序。我们看到了关键的地方,排序!
从这篇文章中,我们了解到,其实对于UOW来说,共有两级排序: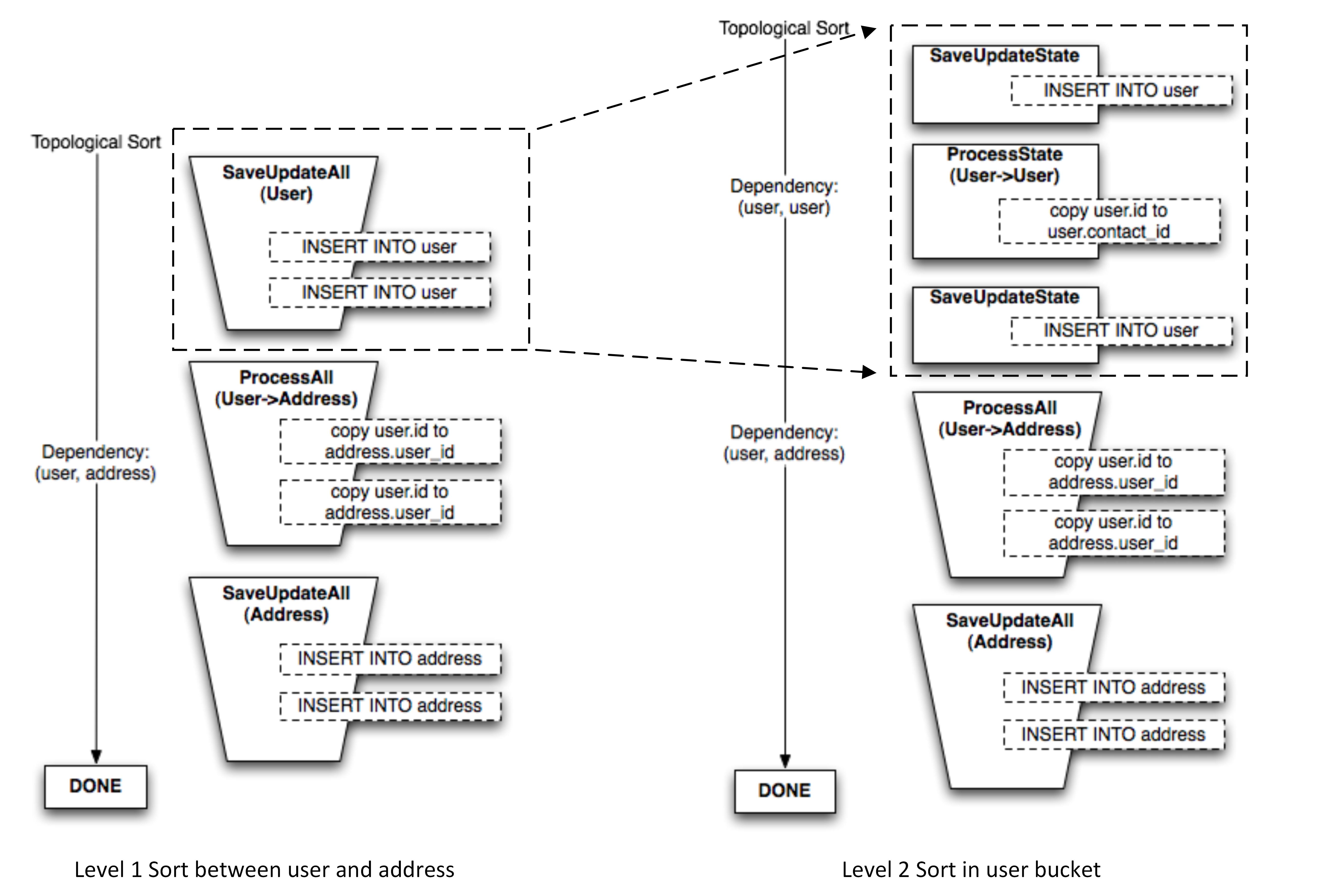 1) 第一级排序,是针对于多个表(class)之前的排序,依赖信息从表之间的关系获取,例如文章中所举的User和Address的例子,需要在user插入后,有了主键,然后再去更新。
2)第二季排序,是针对于一个表(class)之中操作的排序,例如文章中所举的,前一个插入的user依赖后一个user。
1) 第一级排序,是针对于多个表(class)之前的排序,依赖信息从表之间的关系获取,例如文章中所举的User和Address的例子,需要在user插入后,有了主键,然后再去更新。
2)第二季排序,是针对于一个表(class)之中操作的排序,例如文章中所举的,前一个插入的user依赖后一个user。
然而,无论是哪个排序,如果表和表之间在SQLAlchemy定义模型的时候,并没有指定其顺序,那么便没有依赖关系,也便意味着,顺序是不稳定的。
在我们出现的问题中,action和action_event在model定义的代码中,并未指定action和event之前的关系,因此,SQLAlchemy分析依赖的时候,只是将这两个表当做独立的2个表。
3.2.3. 实战一把
为了证明我们的分析,我们在SQLAlchemy打印一些日志来记录依赖关系和最终执行的结果,代码见lib/sqlalchemy/ormunitofwork.py,取消掉这些注释即可。
上面共4行信息,我们需要的是dependencies信息和sort信息,从依赖信息我们可以看到,我们进行的这个事务仅有2组依赖,分别是action和event_action的缓存入库先于缓存清空,而action和event_action之间是没有依赖关系的。所以,最终生成的sort列表,其实是无法保证稳定性的。
所以,才会出现我们本文所出的问题,一会先刷新action,一会先刷新action_event。然而,对于这种问题并不是无解,我们只需要在这两个表里加入relationship,使他们有依赖就可以了。如果确实没有什么关联,那我们就需要思考把更新拆分到更小的事务中了,就像MySQL官网说的那样:Keep transactions small and short in duration to make them less prone to collision。
4. 总结。
TL;DR。写完这篇文章发现,有点太长了,不想细看的看看总结吧,哈哈。
参考