 kelvinqin
commented
2 years ago
kelvinqin
commented
2 years ago Dear Gong Yuan, I have a typo in my previous post, "I can reach 92% accuracy easily on the same dataset." here 92% is the accuracy on whole 30s clips. (My AST model by transfer-learning from imagenet + audioset pretrained model, I got 90% on clip leveal)
Best regards, Kelvin
 YuanGongND
YuanGongND I will draw result on 10s soon, thanks so much,
Kelvin,
I will draw result on 10s soon, thanks so much,
Kelvin,


 1244547821
1244547821
Hi Dear Gong Yuan, Thanks for your excellent work, I learnt a lot.
After understanding your code (partially), I test it on GTZAN using my own training framework (Just copy your ast_model.py)
GTZAN has 2000 music clips with roughly 30s duration per clip. My approach is to chop each clip into 2s segments to construct my data-set for training and testing (chop 70% clips to construct training set, remaining 30% clips as testing)
I tested both imagenet pretrained and imagenet + audioset pretraing model, accuracy looks comparable, but both reach a troublesome situation --- testing loss keep increasing while training loss decreasing. Looks like it is a typical overfitting.
Not sure if you have met the same situation when work on either ESC-50 or SpeechCommand? Let me paste my loss curves and accuracy here. 1> testing loss vs. training loss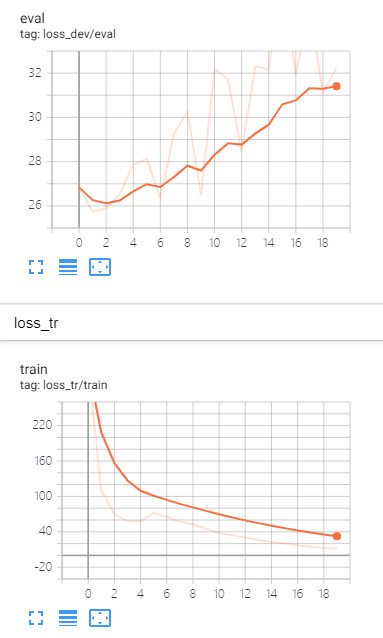
2> testing accuracy: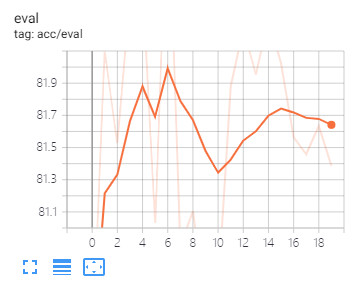
This accuracy looks competitive but not SOTA, because in another CNN approach, I can reach 92% accuracy easily on the same dataset.
My dataloader is very similar with yours, torchaudio to extract fbank in 128 dim, spec_augmentation, (0,0.5) normalization, etc.
I am using all same configuration as you suggested, batch size 48, lr (1e-04 or 1e-05), etc.
I don't worry its accuracy but more worry how can I make testing loss decreasing.
Thanks! Kelvin