此篇是记录开始学习Deep learning的笔记。
所用的资料是:Deep Learning with Python
所用的视频是:【深度学习】《python深度学习》教程
To do machine learning,we need three things:
Input data points.
Example of the expected output.
A way to measure whether the algorithm is doing a good job--The measurement is used as a feedback signal to adjust the way the algorithm works. This adjustment step is what can learning.
How deep learning works
每个输入都找一个weight(权重)和截距项
得到的Y和标准答案的Y比较,差距就是用loss function衡量
Loss sore当做一种回馈,经过Optimizer(优化器),做最适化的方法重新调成Weights。
The mathematical building blocks of neural networks
The problem we are trying to solve here is to classify grayscale images of handwritten digits (28 pixels by 28 pixels), into their 10 categories (0 to 9). The dataset we will use is the MNIST dataset, a classic dataset in the machine learning community, which has been around for almost as long as the field itself and has been very intensively studied. It's a set of 60,000 training images, plus 10,000 test images, assembled by the National Institute of Standards and Technology (the NIST in MNIST) in the 1980s. You can think of "solving" MNIST as the "Hello World" of deep learning -- it's what you do to verify that your algorithms are working as expected. As you become a machine learning practitioner, you will see MNIST come up over and over again, in scientific papers, blog posts, and so on.
The MNIST dataset comes pre-loaded in Keras, in the form of a set of four Numpy arrays:
from keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
from keras import models
from keras import layers
##在keras 写神经网络的方式有两种,一种是 Sequential 的方式(一层一层依序的叠下去),一种是 API 方式。
network = models.Sequential()
network.add(layers.Dense(512, activation='relu', input_shape=(28 * 28,)))
network.add(layers.Dense(10, activation='softmax'))
Before training, we will preprocess our data by reshaping it into the shape that the network expects, and scaling it so that all values are in the [0, 1] interval.Previously, our training images for instance were stored in an array of shape (60000, 28, 28) of type uint8 with values in the [0, 255] interval. We transform it into a float32 array of shape (60000, 28 * 28) with values between 0 and 1.
通常手写辨识习惯把每个像素格子里的灰度从[0, 255]压到[0, 1]
此篇是记录开始学习Deep learning的笔记。 所用的资料是:Deep Learning with Python 所用的视频是:【深度学习】《python深度学习》教程
To do machine learning,we need three things:
How deep learning works
每个输入都找一个weight(权重)和截距项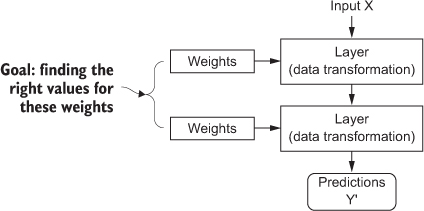
得到的Y和标准答案的Y比较,差距就是用loss function衡量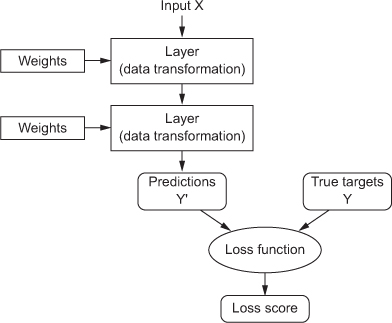
Loss sore当做一种回馈,经过Optimizer(优化器),做最适化的方法重新调成Weights。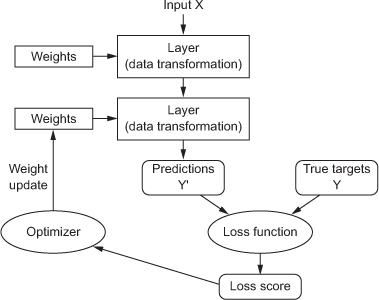
The mathematical building blocks of neural networks
手写辨识作为深度学习的入门基础,被称为深度学习的Hello World。
资料库:\ Keras datasets \ UCI Machine Learning Repository
Prepare
The problem we are trying to solve here is to classify grayscale images of handwritten digits (28 pixels by 28 pixels), into their 10 categories (0 to 9). The dataset we will use is the MNIST dataset, a classic dataset in the machine learning community, which has been around for almost as long as the field itself and has been very intensively studied. It's a set of 60,000 training images, plus 10,000 test images, assembled by the National Institute of Standards and Technology (the NIST in MNIST) in the 1980s. You can think of "solving" MNIST as the "Hello World" of deep learning -- it's what you do to verify that your algorithms are working as expected. As you become a machine learning practitioner, you will see MNIST come up over and over again, in scientific papers, blog posts, and so on.
The MNIST dataset comes pre-loaded in Keras, in the form of a set of four Numpy arrays:
train_images:用来训练的图片 \ train_labels:训练的标准答案 \ test_images:用来测试的图片 \ test_labels:测试资料的标准答案 \ (一般在train_image里割出一部分做val_image和val_label用来调参,防止test资料被污染)
Output:
构筑神经网络
.add(layers.Dense(神经元个数, activation = ' ', input_shape = (输入的神经元的个数, )))
Keras 最常用的连个优化器:rmsprop 和 Adam 多元分类问题通常用 categorical_crossentropy 做损失函数
Before training, we will preprocess our data by reshaping it into the shape that the network expects, and scaling it so that all values are in the [0, 1] interval.Previously, our training images for instance were stored in an array of shape (60000, 28, 28) of type uint8 with values in the [0, 255] interval. We transform it into a float32 array of shape (60000, 28 * 28) with values between 0 and 1. 通常手写辨识习惯把每个像素格子里的灰度从[0, 255]压到[0, 1]
batch_size:一次训练所选取的样本数(每次丢进去图的个数,一般是2的倍数)被称为“一批数据”。
epoch:使用训练集的全部数据对模型进行一次完整训练,被称为“一代训练”。
会返回两个值
test_loss :测试数据的损失函数值
test_acc :测试数据的准确率
过拟合(overfit):机器学习模型在新数据集上的性能往往比在训练数据集上要差。