人工智能固定函数(AI Fixed Function,AIFF)加速器(called Hardware Accelerator (HWA) in Z1)
所有计算单元都有必要的寄存器registers(文件)和本地 SRAM。整个pipeline还有各种存储器(memories),如指令和数据缓存(instruction and data caches)以及紧密耦合存储器(Tightly-Coupled Memory,TCM)。
AIPU 工具链包括编译器(compiler),汇编器(assembler),链接器(linker)。利用这些工具,程序员可以在 AIPU 上开发自己的人工智能操作。
完成运算符的编码后(coding of an operator),需要对代码进行编译(compile),生成可在 AIPU 上运行的最终二进制文件(binary file)。编译过程与传统的编译过程类似,包括编译、汇编和链接。
在编译阶段:
In the compilation stage, the .c source file is compiled through AIPU C compiler aipucc to generate a .s assembly file(汇编文件).
In the assembly stage, the .s file is turned into a .o object file by assembler aipuas.
In the final stage, linker aipuld(链接器aipuld) links one or more .o files and the dependent(从属的) .a static library file and generates the final .out binary file.
对于某些特殊函数(如 printf),还需要驱动程序的支持。
最终编译好的 .out 二进制文件可以直接在 AIPU 模拟器上运行,也可以通过插件集成到 NN 编译器中。
AIPU C compiler
AIPU C,它基于 C 编程语言并进行了一些扩展,还提供了名为 aipucc 的 AIPU C 编译器。
与传统的 C 语言一样,AIPU C 支持标量日期类型和标量运算符。此外,AIPU C 还有以下主要扩展:
函数修饰符 __entry 用于指定入口函数(entry function)。入口函数定义了 AIPU C 程序的入口点。该函数类似于 C 语言中的主函数。
地址空间限定符(Address space qualifiers),用于区分AIPU三个不同的内存区域(memory regions)。限定符gsram0/gsram1 用于全局 SRAM,__lsram0/lsram1 用于局部 SRAM。
用于 TPC 编程的矢量数据类型(vector data types)。矢量数据类型包括用于放置数据的张量矢量类型和用于设置计算掩码的谓词矢量类型。
用于简化 TPC 编程的向量内置函数。
高级 DMA 函数,用于简化 DMA 操作。
用于调试的 printf 函数。
AIPU C 编译器支持所有周易系列平台。编译器提供 -mcpu 选项,用于指定程序运行的进程。这个编译器选项是你需要知道的最重要的选项。
AIPU C 编译器支持多级优化(mulit-level optimization)。Arm 中国建议在开发过程中使用 -O0,在需要更高性能的版本中使用 -O2。
请注意以下 aipucc 编译命令中的选项:
Create a platform and select it as the current platform
创建一个平台并将其选为当前平台
platform connect (connect-url)
Select the current platform by providing a connection URL
通过提供连接 URL 来选择平台
target create (target-file)
Create a target using the argument as the main application
使用作为主程序的参数创建目标
settings set target.run-args (configuration-file) [core-id=Number]
Set the run arguments with the configuration file and the core ID for multi-instance mode. The core ID is 0 by default. core-id is only used for hardware targets
使用配置文件和多实例模式的核心 ID 设置运行参数。core-id 仅用于硬件目标
breakpoint set (cmd-options)
Set a breakpoint or a set of breakpoints in the executable using the options
使用选项在可执行文件中设置一个或一组断点
breakpoint delete (cmd-options)
Delete the specified breakpoint(s). If no breakpoints are specified, delete them all
删除指定的断点。如果没有指定断点,则全部删除
watchpoint delete (cmd-options)
Delete the specified watchpoint(s). If no watchpoints are specified, delete them all
删除指定的观察点。如果没有指定观察点,则全部删除
process launch
Launch the AIPU application in the debugger
在调试器中启动 AIPU 应用程序
thread step-in
Source level single step, stepping into calls
来源级单步骤,进入呼叫
thread step-over
Source level single step, stepping over calls
源级单步,跨步调用
thread continue
Commands for operating on one or more threads in the current process
对当前进程中的一个或多个线程进行操作的命令
thread backtrace
Show thread call stacks
显示线程调用堆栈
memory read (cmd-options) (address-expression)
Read from the memory of the current target process
Receive the float Internal Representation (IR) and build the float graph.
Calibrate each operation to get the output range and the constant data range (like weight and bias) of each operation.(校准每个操作,以获得每个操作的输出范围和常量数据范围(如权重和偏置)。)
周易AIPU编程指南
Chapter 1:介绍
1.1 Zhouyi AIPU
周易AIPU是一款领域灵活、高能效的处理单元(power efficient processing unit)。
周易AIPU在架构(architecture)及其软件开发工具包(Software Development Kit)上有几个显着的特点:
1.2 Hardware architecture
AIPU可以通过不同单元提供 一般用途计算能力(general-purpose computing ability) 和 人工智能计算能力(AI-specific processing ability):
寄存器
根据访问方式将 AIPU 寄存器分为六种类型:
1.3 Software architecture
SDK 包括以下:
Chapter 2:内存操作
Memory hierarchy
DMA operation
DMA由软件控制,在内部存储器和外部存储器空间之间执行数据移动。与 AIFF 操作类似,支持两种模式--MMR 配置模式(MMR configuration model)和描述符模式(descriptor model)。这两种模式不能同时工作,当软件需要更改模式时,需要确保 DMA 处于空闲状态(DMA is idle)。
有两种寄存器:
Register configuration mode
要在寄存器配置模式下工作,软件必须执行以下配置:
Chapter 3:AIPU toolchain
AIPU 工具链包括编译器(compiler),汇编器(assembler),链接器(linker)。利用这些工具,程序员可以在 AIPU 上开发自己的人工智能操作。
完成运算符的编码后(coding of an operator),需要对代码进行编译(compile),生成可在 AIPU 上运行的最终二进制文件(binary file)。编译过程与传统的编译过程类似,包括编译、汇编和链接。
在编译阶段:
In the final stage, linker aipuld(链接器aipuld) links one or more .o files and the dependent(从属的) .a static library file and generates the final .out binary file.
对于某些特殊函数(如 printf),还需要驱动程序的支持。
最终编译好的 .out 二进制文件可以直接在 AIPU 模拟器上运行,也可以通过插件集成到 NN 编译器中。
AIPU C compiler
AIPU C,它基于 C 编程语言并进行了一些扩展,还提供了名为 aipucc 的 AIPU C 编译器。
与传统的 C 语言一样,AIPU C 支持标量日期类型和标量运算符。此外,AIPU C 还有以下主要扩展:
AIPU C 编译器支持多级优化(mulit-level optimization)。Arm 中国建议在开发过程中使用 -O0,在需要更高性能的版本中使用 -O2。
请注意以下 aipucc 编译命令中的选项:
$aipucc -O0 -mcpu=Z2_1104 -S test.c$aipucc -O2 -mcpu=Z2_1002 -c test.c$aipucc -O2 -mcpu=Z2_1104 test.c -Lpath_to_libcommon.a -lcommon -o test.outAIPU assembler
如编译过程所示,AIPU 汇编程序 aipuas 将汇编语言代码转换为目标机器代码。如果您熟悉 AIPU 汇编语言,就可以直接用汇编语言为 AIPU 编程。
AIPU 汇编语言的语法与普通汇编语言的语法相同,只是有一些细微差别。AIPU 汇编程序支持指令、指令和用户定义的宏。
aipuas 的主要特点有:
示例
请参阅《Arm 中国 AI 平台周易指南针汇编编程指南》。
AIPU linker
AIPU 链接器 aipuld 用于将目标文件链接到可执行文件。 AIPU 连接器的简单用法:
$aipuld test.o -Lpath_to_libcommon.a -lcommon -o test.out$aipuld test1.o test2.o -o test.outAIPU debugger
Arm 中国还提供了一个名为 aipudbg 的调试器,用于在 AIPU 模拟器或实际硬件上调试 AIPU 应用程序。aipudbg 允许您设置断点和单步,并检查和修改存储器和变量。
在硬件平台上调试则需要实际的额外外设,以便在客户端和实际硬件之间进行通信。
在多实例(多核)模式下,调试只支持硬件目标。应在调试器中启动应用程序前指定内核。
要调试程序,除了强烈建议使用"-O0 "外,还可在使用 aipucc 编译时添加 -g 选项,因为更高的优化级别和捆绑策略会扰乱调试信息。
Chapter 4:AIPU NN compiler
工作流程:
神经网络编译器是将神经网络模型编译成 AIPU 可执行文件的串行工具。 神经网络编译器的运行主要包括三个步骤:
这三个步骤有以下相应的三个模块:
Model parse module
模型解析模块用于将预训练模型转换为 IR。该版本支持以下模型格式:
对于 Caffe 模型,还包括一些非官方层,如 shuffle 和 detectionoutput。 在模型解析模块中,应包含一个预训练模型,以及关于该模型的一些关键信息:
要解析一个模型,模块将执行以下操作:
Quantization module
为了降低内存存储和计算成本,量化模块会将浮点模型转换为量化模型。目前只支持 8 位对称量化方法(8-bit symmetric quantization method)。
量化模块的工作如下:
Generation module
生成模块是神经网络编译器的后台。生成模块是构建神经网络模型的最后一步。
在生成模块中,流程与其他编译器类似:
Quantization
The following figure shows the 8-bit quantization general pipeline of an operation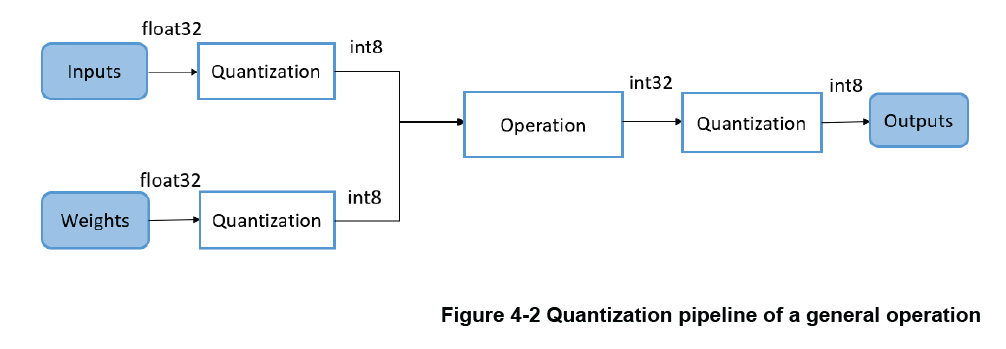
可以先离线量化所有权重,然后在推理过程中,在每次操作(如卷积、元素相加等)之前,将浮点输入量化为 8 位值。之后,还要重新量化,以确保操作结果再次回到 8 位。
单个值的量化相当于将 float32 范围内的值映射到 int8 范围内。
下图显示了该pipeline: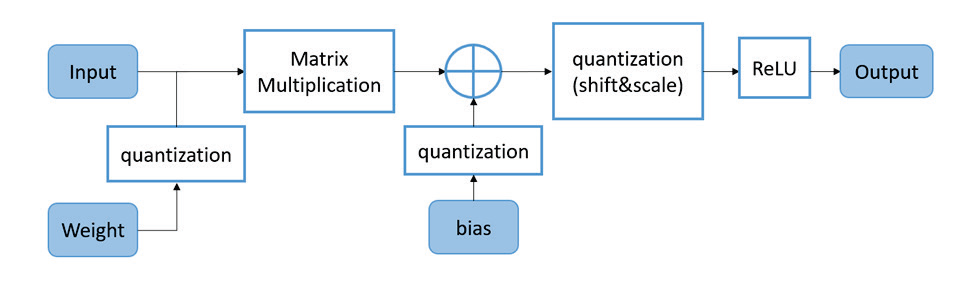
量化程序
NN 编译器中的量化模块执行以下步骤:
Using the NN compiler
安装
NN编译器打包为Pythonwheel包,即WHL文件。
该软件包将依赖于TensorFlow、NumPy、NetworkX和其他第三方软件包。确保满足以下依赖关系:
用法:
用于设置全局选项的环境变量:
aipubuild
aipubuild 是软件包的入口点。可以使用 -h 或 --help 获取帮助信息。该工具使用配置文件中的参数。运行时需要指定所有相关参数。
配置文件是一个标准的 ini 配置文件。它由四个部分组成:
Common section
共用部分只包含一个模式键,用于告诉 aipubuild 在哪种模式下运行。默认情况下,该键处于运行模式,只有两种模式可用:
Parser section
该部分用于模型解析模块:
输入模型的模型格式。默认为 TensorFlow。支持的类型有:
模型的输入形状,通常是单一张量形状,例如 input_shape=[1,224,224,3]
如果有多个输入,请使用逗号分隔,例如 input_shape=[1,224,224,3],[1,112,112,3]
输入数据格式,Onnx 和 Caffe 采用 NCHW 格式,TensorFlow 和 TFLite 采用 NHWC 格式
输入模型的名称,必须是字符串。它用于标识模型。
模型的域,只有 5 个可用选项:
当 model_domain 为 object_detection 时,需要使用 detection_postprocess。
如果您的 model_domain 是 object_detection,并且使用的是官方检测模型,则需要指定检测后置处理。(只支持YOLO和SSD)
输入第三方模型的文件路径。目前,它支持 TensorFlow frozen pb/tflite/onnx/caffemodel。
Caffe 模型的 Prototxt 文件路径
两个方框之间的重叠阈值
当前方框的置信度阈值
某些检测层(如 Region/DecodeBox)的最大方框数
输入图像宽度
输入图像高度
模型的输入节点名称。如果有多个输入节点,请使用逗号分隔。 输入张量名称在实验中支持用于此字段。如果不知道节点名称或节点名称为空,可以尝试在此处使用张量名称。
模型的输出节点名称。如果有多个输出,请使用逗号分隔。 该字段实验支持输出张量名称。如果不知道节点名称或节点名称为空,可以尝试在此处使用张量名称。
张量列表文件名。张量列表文件将列出量化模型所需的所有张量名称。该文件是一个 .txt 文件。每行是 PB 文件和 IR 文件中的 张量名称,用 Tab 键分割。
Optimizer section
该部分用于量化模块:
数据集插件名称,用于创建数据集以处理数据和标签
用于校准模型的数据集路径
量化校准中推断图形的批量大小
权重校准策略。目前支持 "extreme "和 "Nstd"。默认为 "extreme"
量化权重数据的权重位数。支持 4、5、6、7、8、9、10、11、12、13、14、15 和 16 位。默认为 8
用于量化偏置数据的偏置位。支持 16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47 和 48。默认为 32。
量化激活数据的激活位。支持 7、8、9、10、11、12、13、14、15 和 16。默认为 8。
动量(范围[0.0, 1.0]),用于在校准数据集有多个批次时计算某些统计量的加权平均值,如 min_value = momentum pre_min_value + (1-momentum) cur_min_value。默认值为 0.9。
权重和偏差的量化方法。可以设置为‘per_tensor_symmetric_restricted_range’, ‘per_tensor_symmetric_full_range’, ‘per_channel_symmetric_restricted_range’ 和 ‘per_channle_symmetric_full_range’. 默认为‘’per_tensor_symmetric_restricted_range"。
权重和偏置的量化方法,可以设置为 ‘per_tensor_symmetric_restricted_range’, ‘per_tensor_symmetric_full_range’, ‘per_channel_symmetric_restricted_range’ 和 ‘per_channle_symmetric_full_range’.默认为 "per_tensor_symmetric_full_range"。
统计文件路径。统计文件包含统计特征图和权重范围。如果使用自动统计,则不会使用此字段。
量化IR file name。如果设置为 "resnet_50_quant",工具将输出量化的 IR:resnet_50_quant.txt 和 resnet_50_quant.bin。
量化 IR, calibration statistic file and quantization configuration JSON file。如果未设置,量化IR将在"./"中输出。
度量模型的度量插件名称。目前,优化器支持 'cosdistancemetric', 'maskrcnncocomapmetric', 'mioumetric', 'topkmetric', 'vocmapmetric', 'fasterrcnncaffemapmetric', 'fasterrcnntfmapmetric', 'ssdvocmapmetric', 'yolovocmapmetric', 'wermetric', 'keywordspottingmetric', 'iwsltbleumetric', 'psnrmetric' and 'eachcosdistancemetric'。
用于度量模型的数据集路径。
用于度量模型的标签路径。
对模型进行度量时的批量大小。
表示是否在可能的情况下统一每个分支的尺度。
启用 unify_scales_for_concat(=True) 后,可以设置最大搜索深度以加快搜索速度。默认值为 20。
表示是否在可能的情况下启用 Winograd 算法。
文件路径。该 JSON 文件存储每个节点的量化配置。
表示是否启用转储所有张量和其他数据的功能。
一个路径。当 "dump=true "时,所有转储数据文件都将保存到此路径。
DataLoader 的 Worker 数量。调试时应将其设置为 0,以排除多线程的影响。
表示是否将调整大小的方法降级为最近邻方法,以加快调整大小的速度。
GBuilder section
本节介绍一些控制 GBuilder 模块行为的选项
运行模式时模拟器的路径。如果留空,将使用上次运行时的模拟器路径。
输入文件。仅在运行模式时使用。输入文件用于在模拟器上运行。输入文件通常是一些二进制文件,例如原始图像或原始张量。如果有多个输入文件,请使用逗号分隔。
如果要使用自定义库,本地库的路径。通常可以留空。
要构建/运行的目标硬件。默认为 Z1_0409。它支持所有周易系列平台。格式应为 ZX_YYYY(对于 Z1/Z2,X 可以是 1 或 2,YYYY 可以是每个 ZX 的不同配置)。
定义是否启用剖析器。
定义剖析器将剖析哪个硬件单元。目前,它支持 TPC 或 AIFF。如果没有 "prof_unit "选项,默认值为 AIFF。仅适用于 Z1。
AIPU 的堆栈大小(KB)。默认值为 257(KB)。
后缀名为 .png 的文件名,用于以 PNG 格式显示图表。要生成 PNG 图像,必须安装 graphviz 软件包。
下面是一个配置文件示例: