 YunchaoYang
commented
1 year ago
YunchaoYang
commented
1 year ago -
Game Theory
- Zero Sum Games
- A mathematical representation of a situation in which each participant's gain (or loss) of utility is exactly balanced by the losses (or gains) of the utility of the other participant(s).
- Non-deterministic: the probability of the game
- Perfect Information Game
- All agents know the states of other agents
- minimax == maximin
- Hidden Information Game
- Some information regarding the state of a given agent is not know by the other agent(s)
- minimax != maximin
- Probability of Actions: the probability of the player
- Pure Strategies
- Mixed Strategies
- Nash Equilibrium
- No player has anything to gain by changing only their own strategy.
-
Repeated Game Strategies
-
Finding best response against a repeated game finite-state strategy is the same as solving a MDP
-
Tit-for-tat
- Start with cooperation for first game, copy opponent's strategy (from the previous game) every game thereafter.
-
Grim Trigger
- Cooperates until opponent defects, then defects forever
-
Pavlov
- Cooperate if opponent agreed with your move, defect otherwise
- Only strategy shown that is subgame perfect
-
Folk Theorem: Any feasible payoff profile that strictly dominates the minmax/security level profile can be realized as a Nash equilibrium payoff profile, with sufficiently large discount factor. 无名氏定理: 如果参与者对未来足够有耐心, 如果参与者对未来足够有耐心, 任何程度的合作(只要是可行的且满足个人理性)都可以通过一个子博弈精炼纳什均衡来达成。
-
In repeated games, the possibility of retaliation opens the door for cooperation.
-
Feasible Region
- The region of possible average payoffs for some joint strategy
-
MinMax Profile
- A pair of payoffs (one for each player), that represent the payoffs that can be achieved by a player defending itself from a malicious adversary.
-
(too vague, the worst case for one player): best in the worst possible conditions
-
why it is a profile? a strategy profile refers to a set of strategies, one for each player in the game, that specifies how each player will act in the game. Say mixed strategy
-
Subgame Perfect
- Subgame perfect: is there a formal definition in English with good intuition?
- How to find: backward induction See wikipedia
- Always best response independent of history
-
Plausible Threats: is there a formal definition in English with good intuition?
- B threatens A, but with a cost of losing his own benefit, If A think B is bluffing, does not believe that B will follow his threat. which is not reasonable for B himself. Thus it is definitely in a subgame perfect condition. So, the plausibility of the threat depends on whether or not the other player believes that the player making the threat is capable of carrying out the threatened action. If the threat is believed to be implausible, then it is unlikely to be effective in achieving the player's goals.
-
Zero Sum Stochastic Games
-
Value Iteration works!
-
Minimax-Q converges
-
Unique solution to Q*
-
Policies can be computed independently
-
Update efficient
-
Q functions sufficient to specify policy
-
General Sum Stochastic Games
-
Value Iteration doesn't work
-
Minimax-Q doesn't converge
-
No unique solution to Q*
-
Policies cannot be computed independently
-
Update not efficient
-
Q functions not sufficient to specify policy
-
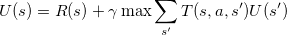
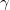 (typically between 0 and 1),
describes the value placed on future reward. The higher
(typically between 0 and 1),
describes the value placed on future reward. The higher 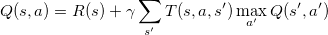
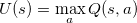
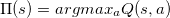
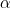 , is how far we move
each iteration.
, is how far we move
each iteration.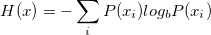
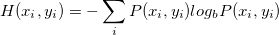
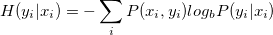
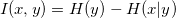
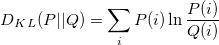
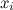 is strongly relevant if removing it degrades the Bayes' Optimal
Classifier
is strongly relevant if removing it degrades the Bayes' Optimal
Classifier a subset of features S such that adding
a subset of features S such that adding
2 Unsupervised Learning
UL consists of algorithms that are meant to "explore" on their own and provide the user with valuable information concerning their dataset/problem