 FlightofIcarus
commented
7 months ago
FlightofIcarus
commented
7 months ago Linguagem
JavaScript
Detalhes da decisão
A linguagem escolhida para o desenvolvimento da API foi a JavaScript, pois além de ser uma linguagem bastante atual, sua integração com o ambiente de execução Node.js é nativo, não precisando de módulos específicos para a execução, nem que o código seja buildado antes da execução, o que acelera a produção do nosso MVP, de forma a termos uma API funcional já em pouco tempo. Além disso, esta linguagem acrescenta um bom nível de simplicidade de codificação, sendo amplamente conhecida por todos da equipe, que a veem inclusive como uma ótima ferramenta para prototipagem rápida, por ter um vasto ecossistema e uma comunidade bastante ativa.
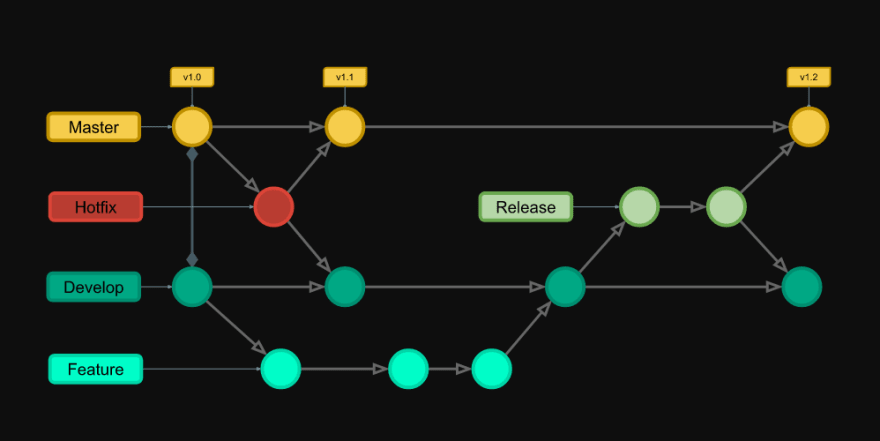
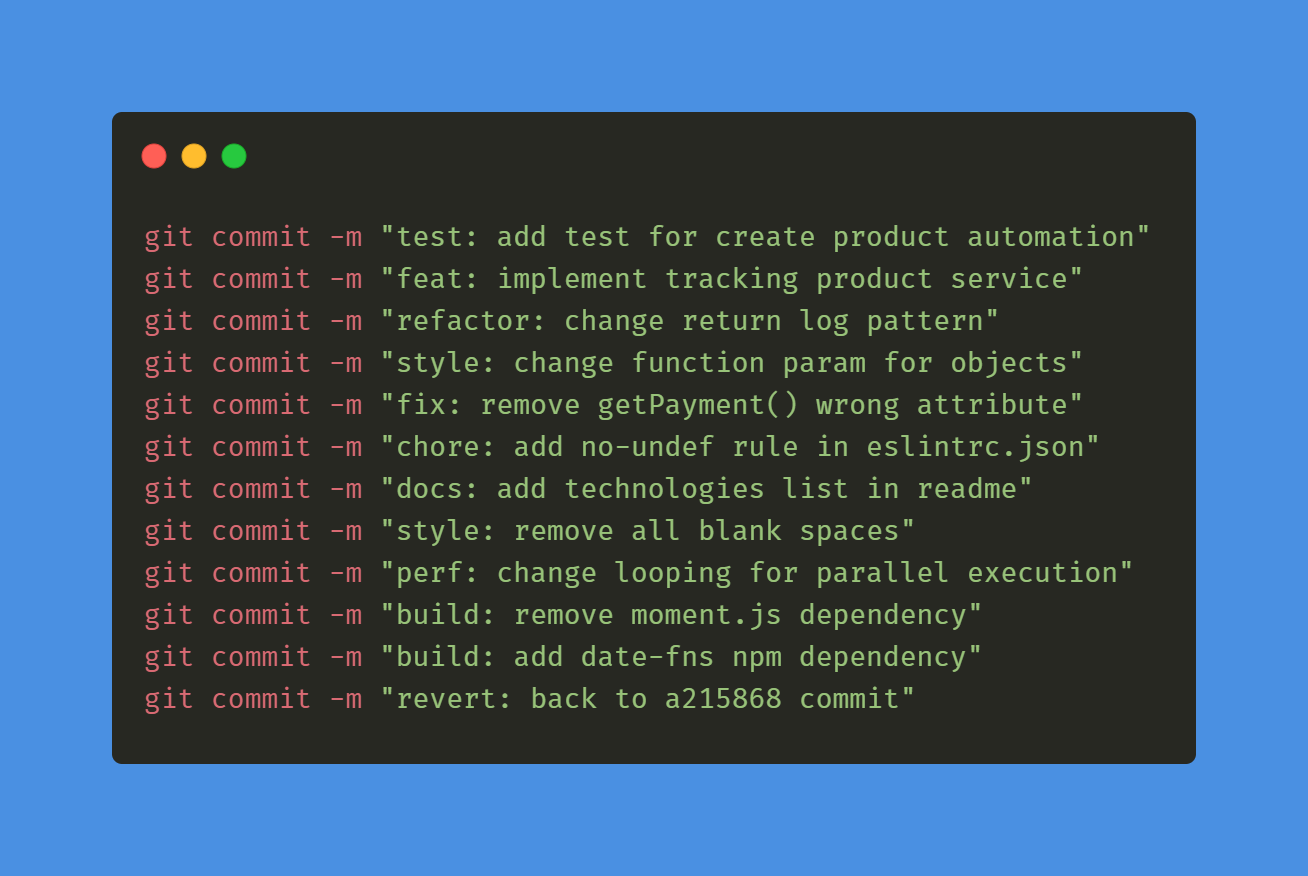
Definir parâmetros técnicos de ferramentas, tecnologias, pattners, etc.
• Linguagem • Paradigma • Arquitetura • Fluxo de trabalho • Pattern de commits • Tipo de banco de dados • Banco de dados • ORM (Object Relational Mapper) • Padrão de nomenclatura de variáveis e funções • Ferramentas de desenvolvimento • Módulos/Dependências