adeshpande3
commented
6 years ago
adeshpande3
commented
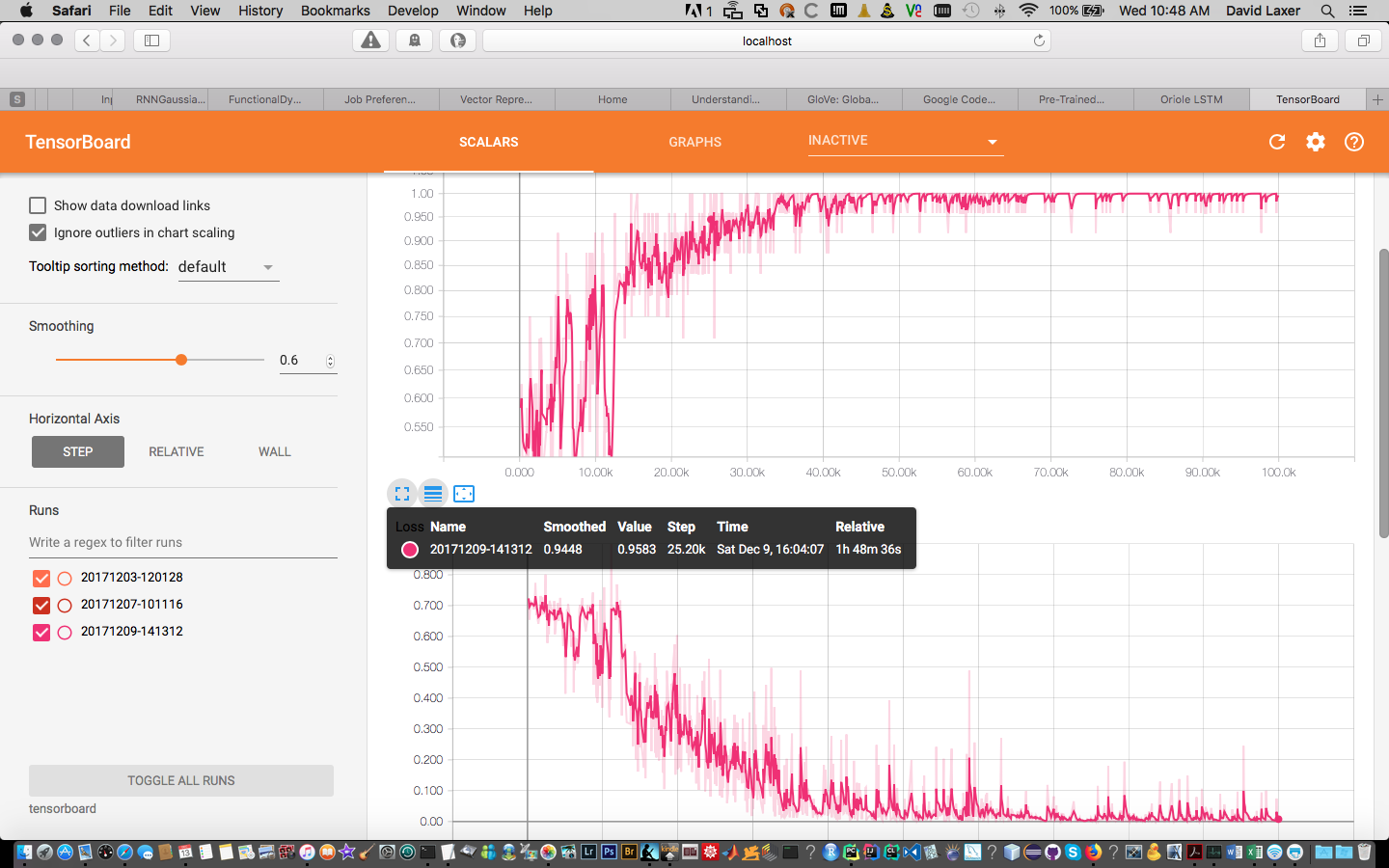
6 years ago My initial thought is that a big problem with these LSTM/RNN models is combatting the issue of overfitting to the training data, and judging from your training curves, I think it's safe to say that the network definitely has learned the training data, but it might not be able to generalize to newer examples, and thus the reasoning for the fluctuating test accuracy.
Since this tutorial was just to mainly get people exposed to NLP tasks and using LSTMs/RNNs in Tensorflow, I didn't include these in the code, but what I think would be helpful is thinking about adding some types of regularization, thinking about using just RNNs (since the LSTMs might just be contributing to the overfitting problem), using early stopping, splitting your data into train/test/validation instead of just train/test so that you can see where the validation accuracy drops off, etc etc.
Hope this helps!
 dbl001
dbl001
 anil215
anil215
I'm running on Tensorflow version: 1.4.0 Anaconda Python 3.6 OS X 10.11.6 No GPU I trained the models in my own environment:
iterations = 10 for i in range(iterations): nextBatch, nextBatchLabels = getTestBatch(); print("Accuracy for this batch:", (sess.run(accuracy, {input_data: nextBatch, labels: nextBatchLabels})) * 100)
Accuracy for this batch: 87.5 Accuracy for this batch: 75.0 Accuracy for this batch: 83.3333313465 Accuracy for this batch: 95.8333313465 Accuracy for this batch: 83.3333313465 Accuracy for this batch: 91.6666686535 Accuracy for this batch: 91.6666686535 Accuracy for this batch: 79.1666686535 Accuracy for this batch: 87.5 Accuracy for this batch: 79.1666686535
Any ideas why the accuracy varies so much for each batch? I tried running against the pre-trained model, but tensorflow 1.4.0 can't process the file. Here's my tensorboard output: