 AbdullahDawud
commented
4 years ago
AbdullahDawud
commented
4 years ago 1>Are these three almost same function or are different with different set of color maps?
'gray' and 'binary' are different colormaps. If you refer to matplotlib documentation, the difference is shown graphically. Click the following to see the difference between the binary and gray colormaps: Colormaps
2>Are the color maps same but perform differently when operated on these three?
Now, there are not three different colormaps in the codes you quoted but only two. Two of these codes refer to the same colormap I'm. The first and the third refer to the same colormaps but are just different ways of accessing the same colormap object 'gray'.
3>If not then are these functions some data or dataset specific if not then what are the use of these three statements...
It's been a long time since I have seen these codes. But if I remember correctly, the cm module in the matplotlib package is where the colormaps are found. So, to use colormaps in your codes you have to import the matplotlib.cm module. Now, since the pyplot module in the matplotlib package also imports the matplotlib.cm module in it's code, therefore you can also access the cm module with a syntax like cmap=plt.cm.gray or cmap=plt.get_cmap("gray")
You can consult the source code of the pyplot module to see that it imports the matplotlib.cm module at line 53 and 54 here: pyplot.py
Do not get too much into this source codes at this stage, rather concentrate on the machine learning codes instead.
 Samrat666
Samrat666 tcarr032
tcarr032 ageron
ageron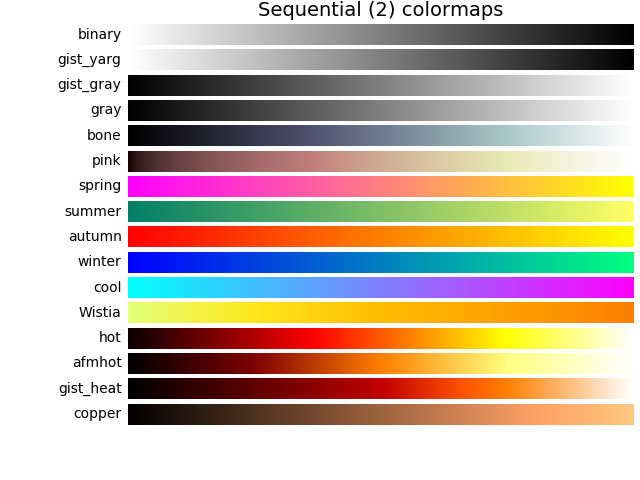{kind=link}
i just wanted to ask that what is the difference between all these three and the other functions. Please help me out sir I searched a lot on the internet over this issue but could not be resolved. My issue is that :-- 1>Are these three almost same function or are different with different set of color maps? 2>Are the color maps same but perform differently when operated on these three? 3>If not then are these functions some data or dataset specific if not then what are the use of these three statements... You can understand my breadth of confusion sir please help...