 agostini01
commented
4 years ago
agostini01
commented
4 years ago - [ ] Quantization
- [ ] Profiling
- [ ] Pruning
Open agostini01 opened 4 years ago
agostini01
commented
4 years ago  malithj
commented
4 years ago
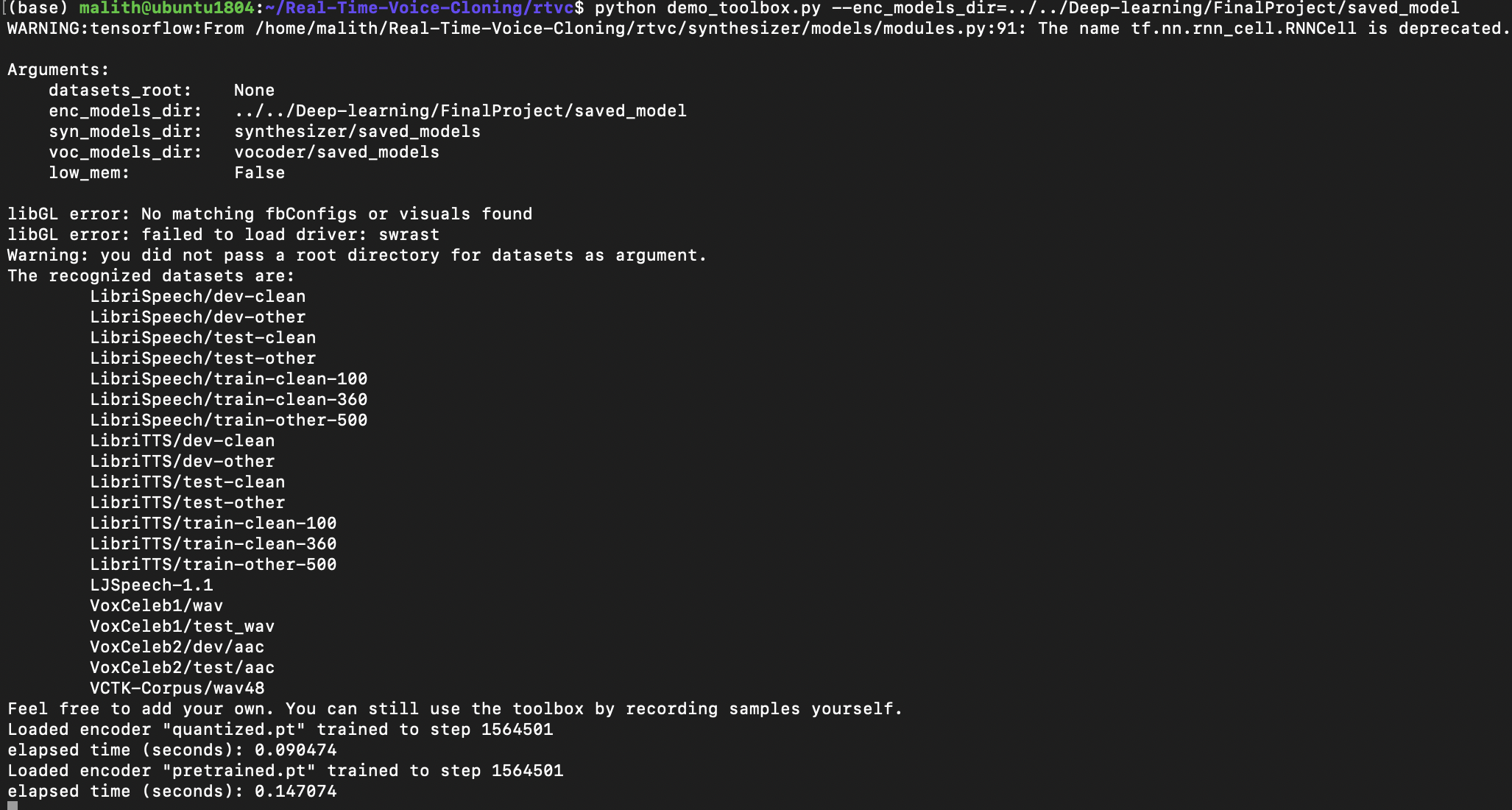
malithj
commented
4 years ago Finished quantization.

agostini01
commented
4 years ago Wow!
@malithj , This is rather impressive! Really cool.
Just to confirm as you have much more experience with quantization than I do. Are the following steps correct?
torch.quantization.quantize_* functions to perform the quantization - passing in the correct datatype.What datatype did you use?
Really awesome work! Can it still do the same kind of encoding?
malithj
commented
4 years ago Thanks.
Yep. I used torch.qint8 so that there would be 256 (2^8) quantization levels. The sound quality doesn't seem to degrade that much.
Here's the script I used. https://github.com/malithj/Deep-learning/blob/master/FinalProject/psq.py
But pytorch only supports quantization on CPUs. So, testing will have to be done using CPUs.
agostini01
commented
4 years ago Understood! Sounds reasonable!