 ahasusie
commented
5 years ago
ahasusie
commented
5 years ago We say that the data is labelled if one of the attributes in the data is the desired one, i.e. the target attribute. For instance, in the task of telling whether there is a cat on a photo, the target attribute of the data could be a boolean value [Yes|No]. If this target attribute exists, then we say the data is labelled, and it is a supervised learning problem.
And the learning continues iterating until the algorithm discovers the model parameters with the lowest possible loss. Usually, you iterate until overall loss stops changing or at least changes extremely slowly. When that happens, we say that the model has converged. The gradient always points in the direction of steepest increase in the loss function. The gradient descent algorithm takes a step in the direction of the negative gradient in order to reduce loss as quickly as possible. 导数的几何意义是该函数曲线在这一点上的切线斜率, 计算gradient也就是在计算函数在某点的切线斜率,怎么计算?算函数的导数。函数的导函数在某一区间内恒大于零(或恒小于零),那么函数在这一区间内单调递增(或单调递减)so if given a loss function of a linear regression model function, we don't need to calculate each loss value to get the minimum parameter vector, we use the gradient descent algorithm to get to the minimum point and get the related parameter vector.
supervised unsupervised
classification problem linear regression problem logistic regression problem
squared loss mean square error(MSE): average squared loss per example over the whole dataset
[ ] loss: measures how well the model fits the data
[ ] generalization: underfitting / overfitting
[ ] regularization: measures model complexity, early stop, regularization rate(lambda) aim: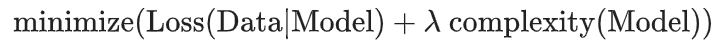
[ ] freture engineering
[ ] training set / test set / validation set