 natowi
commented
3 years ago
natowi
commented
3 years ago It is not as easy as just adding a new input path to the sfm node. It requires some tinkering to get it to work with your own camera poses. You need to convert your known camera poses from ScanNet format to the Meshroom sfm (json) format. "Cannot find image file corresponding to the view" suggests that the images are not correctly referenced (image view ids/names do not match).
I then copied the input file path in the SfM node input attribute, removed the input link of Structure from Motion node, and paste back the input file path in the input attribute field, and run the SfM node again.
That is not what the documentation says. Carefully read the second part.
 SamMaoYS
SamMaoYS


 stale[bot]
stale[bot]
Describe the problem I am working on reconstructing a scene with known camera poses, I followed the link Using known camera positions but it doesn't work for me.
I tested the pipeline, by running the entire default pipeline, which successfully goes through the entire pipeline and returned a mesh.
I then copied the input file path in the SfM node input attribute, removed the input link of Structure from Motion node, and paste back the input file path in the input attribute field, and run the SfM node again. The SfM node works fine, and then the next node PrepareDenseScene only goes from rangStart 0 with rangSize 40. And output only has 0.log, 0.statistics, 0.status and some images. Whereas, originally it will have 0.log, 0.statistics, 0.status, and 1.log, 1.statistics, 1.status.
Which makes the node DepthMap reports an error. Cannot find image file coresponding to the view ...
Screenshots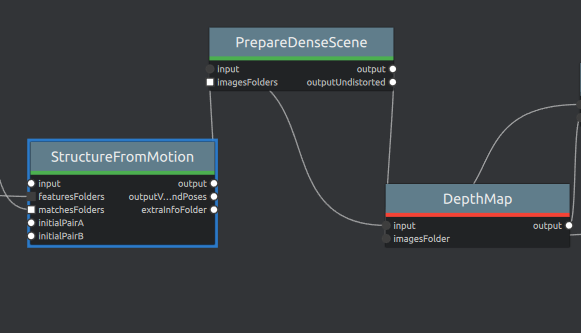
Log
Desktop:
This is very confusing to me, since I didn't change anything. I simply just remove an input link and set back the input file path. Which makes the pipeline fails. I would like to ask, is the input link have some additional functionalities except for setting the input file path?
Thank you!