 tgsmith61591
commented
2 years ago
tgsmith61591
commented
2 years ago Hi @claudia-hm sorry for the late reply. I'm looking into this. First thing I notice is a peculiar statsmodels warning when I enable the trace on the fit:
In [15]: model = pm.auto_arima(y2_train, trace=5)
Performing stepwise search to minimize aic
/opt/miniconda3/envs/ml/lib/python3.7/site-packages/statsmodels/tsa/statespace/sarimax.py:1890: RuntimeWarning: divide by zero encountered in reciprocal
return np.roots(self.polynomial_reduced_ar)**-1
ARIMA(2,1,2)(0,0,0)[0] intercept : AIC=-1614.762, Time=0.07 sec
First viable model found (-1614.762)
ARIMA(0,1,0)(0,0,0)[0] intercept : AIC=-1670.667, Time=0.06 sec
New best model found (-1670.667 < -1614.762)
ARIMA(1,1,0)(0,0,0)[0] intercept : AIC=-1665.984, Time=0.03 sec
ARIMA(0,1,1)(0,0,0)[0] intercept : AIC=15212.220, Time=0.05 sec
ARIMA(0,1,0)(0,0,0)[0] : AIC=-1839.861, Time=0.02 sec
New best model found (-1839.861 < -1670.667)
ARIMA(1,1,1)(0,0,0)[0] intercept : AIC=-1663.997, Time=0.04 sec
Best model: ARIMA(0,1,0)(0,0,0)[0]
Total fit time: 0.276 secondsI'll dig more into this.
 fkiraly
fkiraly
Describe the bug
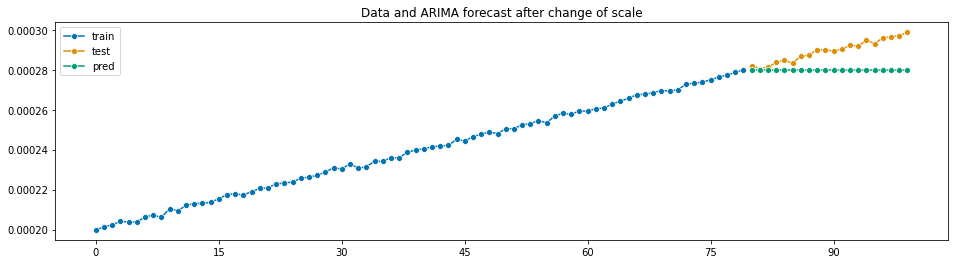
auto_arima is returning constant predictions when data is too small., i.e., close to zero
Initially, I generated a linear trendy time series with slope 0.5 and intercept 100, plus some noise. Then, I wanted to change units of my data and I divided the values of the time series by $10^6$. I expected to obtain a similar prediction. However, auto_arima returned a repeated constant value that poorly predicts my data.
To Reproduce
This is a sample code that shows the bug
The output is:
Versions
Expected Behavior
I would expect to obtain a similar shape to the one produced in the first forecast
Actual Behavior
auto_arimaproduces the following forecast:Additional Context
If this is due to some numerical issue, I would like to understand what is happening and if there is some tolerance value that I can change to bypass this problem.