 jiaodong
commented
1 year ago
jiaodong
commented
1 year ago It is still quite necessary in my opinion, since our OPT-175B benchmarks are executed in Nvidia's Selene with NVLink and NVSwitch you mentioned, pipeline parallelism is still essential for scaling, or even borderline of table stake.
I think the situation you described pushed to its extreme is basically TPU cluster that inter-chip connection is not a bottleneck of scaling, in this case it will suffice mostly with just tensor / intra-operator parallelism that relies less on inter-operator pass instead.
 GHGmc2
GHGmc2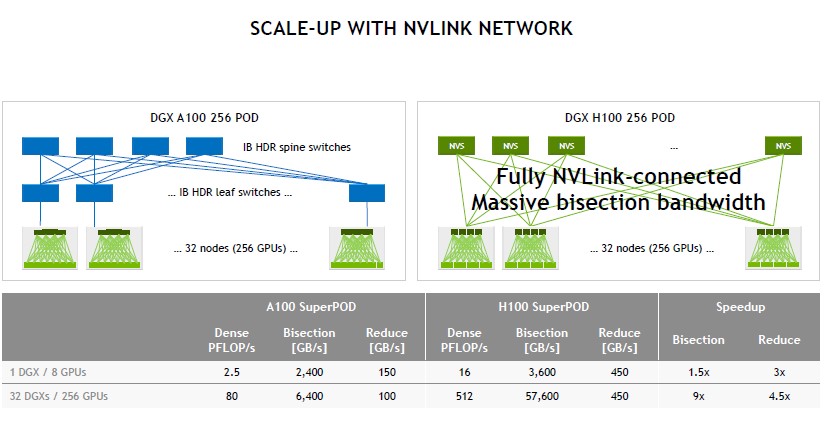
 zhisbug
zhisbug
alpa's two-level hierarchical space of parallelism is based on the observation that the bandwidth of inter-node(like InfiniBand) is much lower than intra-node(like NVLink).
But the latest NVLink Switch system supports up to 256 GPUs(32 nodes) with direct connection: https://www.nvidia.com/en-sg/data-center/nvlink/, is the pillar still solid since NVIDIA may support more and more GPU cards with direct connection in the future?
BTW, can we open a discussion section? Currently we can only fire a PR or issue if have some questions. Thanks!