 alexk2037
commented
3 years ago
alexk2037
commented
3 years ago My Vosk Server Implementation
Machine: AWS EC2 Server Operating System: Ubuntu 18.04 Python Version: Python 3.8
Steps
Create Python virtual environment
$ python3 -m venv venv
$ source venv/bin/activateDownload Vosk Server
$ git clone https://github.com/alphacep/vosk-server.gitInstall dependencies
$ python3 -m pip install aiortc aiohttp aiorpc vosk websocketsDownload Speech Recognition model:
$ cd
# Download accurate wideband model
$ wget http://alphacephei.com/vosk/models/vosk-model-en-us-0.20.zip
$ unzip vosk-model-en-us-0.20.zip
# Rename the downloaded model
$ mv vosk-model-en-us-0.20 modelCreate System Daemon
$ mkdir -p ~/.config/systemd/user
$ touch ~/.config/systemd/user/vosk_service.service
$ systemctl --user list-unit-files | grep vosk_service
>>> vosk_service.service maskedWrite to .service File
$ nano ~/.config/systemd/user/vosk_service.service[Unit]
# Human readable name of the unit
Description=Vosk Service
[Service]
# Command to execute when the service is started
WorkingDirectory=/home/ubuntu
ExecStart=/home/ubuntu/venv/bin/python3 /home/ubuntu/vosk-server/websocket/asr_server.py
# Disable Python's buffering of STDOUT and STDERR, so that output from the
# service shows up immediately in systemd's logs
Environment=PYTHONUNBUFFERED=1
# Automatically restart the service if it crashes
Restart=on-failure
# Our service will notify systemd once it is up and running
Type=simple
[Install]
# Tell systemd to automatically start this service when the system boots
# (assuming the service is enabled)
WantedBy=default.targetActivate service
$ systemctl --user daemon-reload
$ systemctl --user start vosk_service
$ systemctl --user status vosk_serviceEnable Vosk to start on bootup:
$ systemctl --user enable vosk_serviceCheck Logs
$ journalctl --user -u vosk_service
# Or
$ journalctl --user -u vosk_service --since today nshmyrev
nshmyrev LuisFerchx
LuisFerchx
Hello, I was wondering how I could configure the appearance of the closed captioning on Jitsi Meet?
Currently it looks like this for me: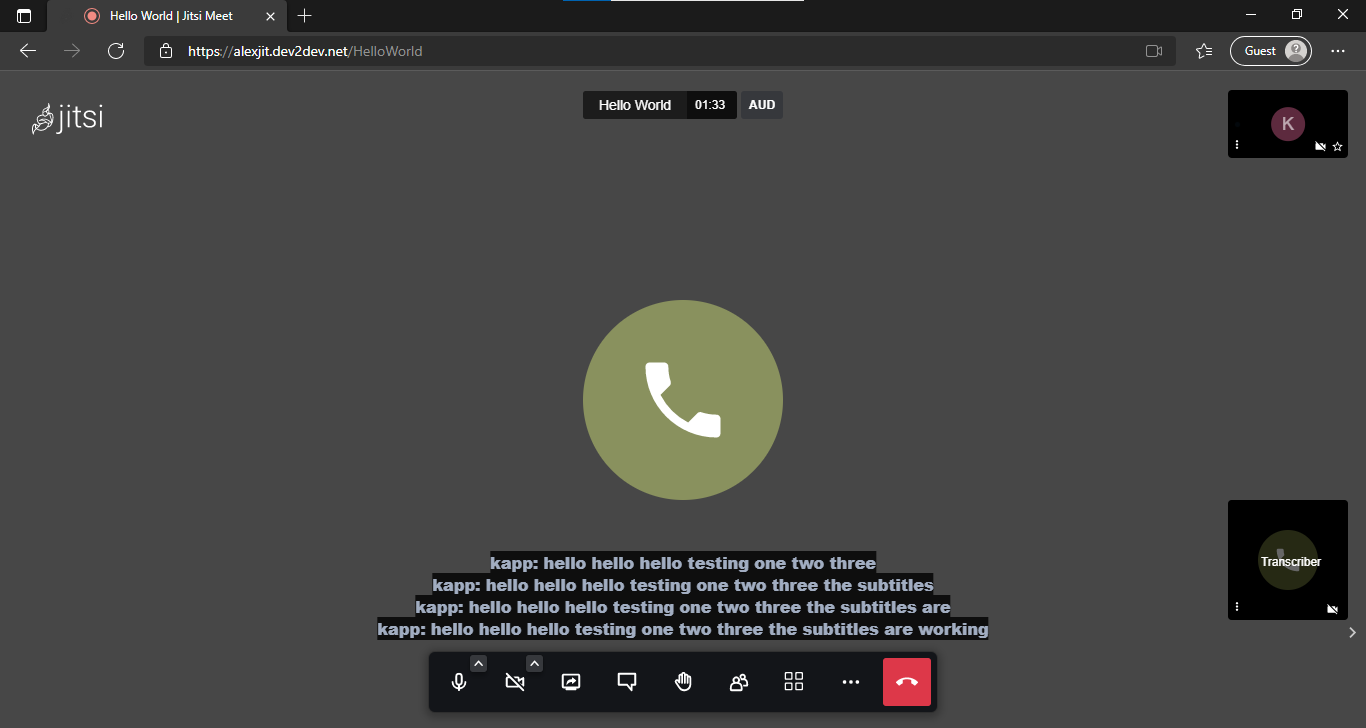
You can see that the subtitles are stacked on top of one as the text-to-speech program processes the audio. However, I would like the closed captioning to appear more like Google Meet, in that the subtitles stay in one line and get overwritten in place. For example, this video about Jitsi closed captioning demonstrates the behaviour I am looking for.
I am currently using Vosk Server to handle the text-to-speech. It looks to me like the subtitles are showing multiple lines of partial text at once, however, I’m not sure where I can configure the UI to display one line of partial text at a time, or even just the full text for a sentence.
On the Jitsi community forums, I received a reply stating:
I can write down my Vosk Server implementation if that may be useful. Any help, advice, or links would be appreciated. Thanks.