 balmas
commented
4 years ago
balmas
commented
4 years ago Some problems with the current code:
- The multiple asynchronous, interdependent remote and local service calls with differing logic per language and per page (e.g if treebank is available or not) make the code very complex and increasingly difficult to add new sources of data .
- many of the remote data sources are fairly static and caching of combined calls could improve performance
- current code does not support more than one query result at a time and all calls need to be reexecuted to reissue a prior query
- this is less than optimal for the wordlist downloads, for which only short definitions are needed
- cancelling a request mid-stream may not work optimally
 irina060981
irina060981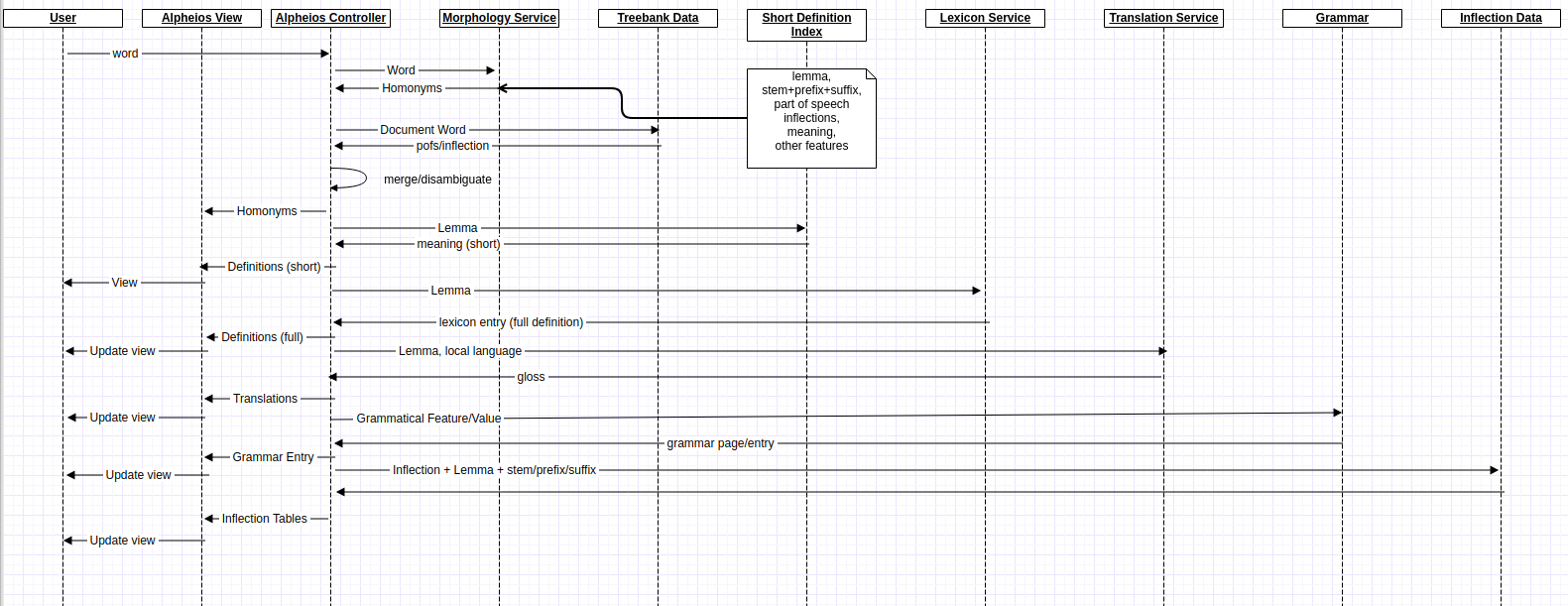



 kirlat
kirlat



This issue is to discuss requirements and design decisions for refactoring the lexical query
Some desired features driving the need for refactoring: