 erwinmombay
commented
8 years ago
erwinmombay
commented
8 years ago how about stricter validation instead?
Closed aghassemi closed 3 years ago
erwinmombay
commented
8 years ago how about stricter validation instead?
 aghassemi
commented
8 years ago
aghassemi
commented
8 years ago I am okay with that too.
 Gregable
commented
8 years ago
Gregable
commented
8 years ago Sure, stricter validation is fine.
I just checked and the validation rules allow using src instead of data-videoid (one or other required), though it seems the documentation doesn't mention src, and the runtime doesn't seem to understand it either. I suppose we should remove the src option as well?
 powdercloud
commented
8 years ago
powdercloud
commented
8 years ago Interestingly the video id's for YouTube may not have a specified format. http://webapps.stackexchange.com/questions/54443/format-for-id-of-youtube-video
 shimonenator
commented
8 years ago
shimonenator
commented
8 years ago There's a very valuable reason to keep src and document it: when CMS uses oEmbed to resolve embed data, YouTube does not provide video id. By allowing full embed URL to be passed, theres no need to keep custom business logic to strip out id out of the URL, which means less errors due to URL variations.
Gregable
commented
8 years ago @shimonenator , I'd be OK with that as well, but what we have now is the worst of both worlds. We validate src, but the runtime doesn't support it and it doesn't work.
aghassemi
commented
8 years ago It is possible that the publisher who misconfigured the tag as amp-youtube data-videoid="https://youtu.be/UDGKqWyzuRs" used oEmbed and didn't bother parsing the Id out of the URL.
Despite src passing the validation, it currently does not work as @Gregable mentioned.
Two different approaches here:
Option 1
src and remove the rule from the validator. amp-youtube to detect and do the right thing.Option 2
amp-youtube to handle src as well as videoid
src wins? videoid wins? (anything other than videoid winning could be a breaking change affecting existing docs considering src has been passing validation but ignored)data-videoid if possible (doesn't have to be precise. as @powdercloud commented, there may not be a specific characterset or length for youtube ids. Maybe just ensuring videoid is not a Url as part of validation is good enough to prevent )Option 2 is more explicit but I am personally not a fan of either this or that attribute is required model, so I slightly refer Option 1 @dvoytenko @mkhatib thoughts?
 dvoytenko
commented
8 years ago
dvoytenko
commented
8 years ago @aghassemi Please see if this issue needs to be deduped with #361. On the surface, I think an src attribute would be better, but would be open to re-parsing videoid as well.
powdercloud
commented
8 years ago @shimonenator to clarify, 'src' currently doesn't work as @Gregable mentioned. On extracting the id from a URL, I think even though the id format isn't specified, using the preceding '/' makes this easy, e.g. 'https://youtu.be/UDGKqWyzuRs'.split('/').pop() in Javascript.
So I think stricter validation is useful, it reduces frustration with pages that validate but won't work. So maybe this?
data-videoid, disallow '/' and ':', e.g. something like [^/:]+. This disallows placing a URL into there without assuming much about the format of the video id.src, since it's not implemented in amp-youtube.js.powdercloud
commented
8 years ago Oh sorry - I didn't reload the page before commenting, so I was blind to the other comments. I think it's cool to have src if someone implements it for the runtime.
powdercloud
commented
8 years ago On the other hand 'src' is easy to remove so I made a PR for doing that. https://github.com/ampproject/amphtml/pull/4381
powdercloud
commented
8 years ago Upon looking at extracting the video id, I don't think we should pursue this in the runtime because it doesn't seem stable. E.g., there are already these variations: https://youtu.be/UDGKqWyzuRs, https://www.youtube.com/watch?v=UDGKqWyzuRs&feature=youtu.be, https://www.youtube.com/watch?v=UDGKqWyzuRs. We'd be going down a path of encoding a bunch of heuristics, which makes the runtime slower and harder to maintain over time. And it's not a good precedent.
So I think for this as well, tightening the validation is probably the right call. I'll send a PR for that and we can discuss it.
powdercloud
commented
8 years ago I made a PR https://github.com/ampproject/amphtml/pull/4383 for discussion. This would invalidate a few pages but it would reduce user confusion down the road, probably. If you want to support the URLs in the runtime instead, fine with me as well (consider the example URLs I provided).
shimonenator
commented
8 years ago Just as @dvoytenko, I would choose option 2 from proposed by @aghassemi. To solve the problem of which attribute takes precedence, may be it possible to prohibit having 2 attributes at the same time?
@powdercloud, it is not hard to extract ID with a moderate regex. Shouldn't make things slower since you're already running a regex validation for the attribute anyway. The reason to expose support for src attribute would then be to keep this logic in one, authoritative place, where each of the providers can appoint a representative who will verify and keep the regex up to date. This is a big win in the cases where similar URLs provide different functionality, and publishers don't have to keep catching up with new options all the time.
powdercloud
commented
8 years ago @shimonenator It's possible to have mutually exclusive attributes. This feature is already in use for the data-videoid and video-id and src. Regarding runtime cost, not that I'm too worried about a regex, but note that the validation is usually done offline, but id extraction would be online. I'm more worried about complexity and having something that works well. So, +1 to having services specify what their ids are and how to extract them from a URL. I'm not satisfied with http://webapps.stackexchange.com/questions/54443/format-for-id-of-youtube-video. I hope removing the deprecated stuff and making stuff invalid that doesn't work is noncontroversial regardless.
shimonenator
commented
8 years ago @powdercloud I am certainly not disputing clean up part.
I don't think that the link you shared is representative of the URL formats. Rather it's more relevant to validation of videoid itself. As for the src and URL the problem is not as much validating it, but however extracting the videoid from the URL. We're not discussing supporting the entire Internet but only a handful of very popular embeds. It should be pretty safe to assume that the burden of updating the id-extracting regex is no bigger than what's already in each publisher. Due to AMP's high visibility, it should be safe to assume that in the situation of a new URL format for any of the , there will be a new PR rather quickly.
powdercloud
commented
8 years ago @shimonenator Yeah you have a point. Perhaps the best compromise on the src attributes is to specify the allowed values relatively precisely with a regexp in the validator. E.g., for YouTube we'd allow rougly https://www.youtube.com/watch?v=[^&]+, but not any of the shortened URLs (youtu.be) or stuff with additional parameters, etc. Then the runtime / amp-youtube extension can assume that the src attribute conforms to this format and extract the video id by looking for the first '=' in the URL, for example - there's no need to do query string parsing.
shimonenator
commented
8 years ago @powdercloud requiring a certain format of a URL is not a good idea: each publisher gets their urls in a different way: some copy URL from the address bar, some click share button and copy share URL, some use oEmbed or similar tech to get more info about the embed. Each form brings its own URL format, and requiring specific URL structure is then going to be even more burden as well as more error prone than not supporting it.
I am still not quite sure what you're trying to achieve by reducing regex complexity: the speed of id extraction will vary in nanoseconds in a well structured pattern, and the same pattern could be used for validation and extraction. Even if there's a 100 Youtube, Twitter, Instagram, Scribd, Facebook and other embeds on the page, any performance hit will come from elsewhere.
I've just had to write a unit test for the same functionality, so consider a few Youtube URLs and my regex:
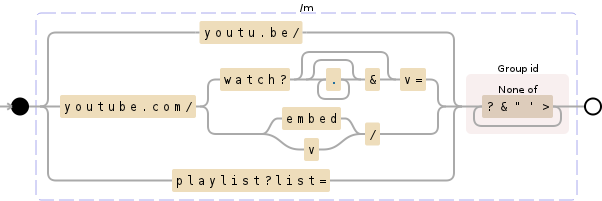
 rudygalfi
commented
8 years ago
rudygalfi
commented
8 years ago I think there's a reasonable middle ground we can reach here, but I do want to call out the slippery slope.
There are a number of other instances in designing AMP features where if we can save the client from needing to do work that can reasonably happen elsewhere, we do that. I think having a well-documented API around how a video ID should be passed as an input is a reasonable place to have the division of concerns rest.
With this proposal, we introduce more work the client has to do to mitigate developer error. As I said above, maybe that's a price worth paying, but we should quantify the cost, which, by the way, also includes validation complexity, documentation, and further upkeep.
Also, I favor invalidating src and sticking to one attribute. The attribute should just be documented to say that it accepts multiple formats to identify the video object.
dvoytenko
commented
8 years ago I'd be in favor of supporting an embed-like common src attribute. For inspiration, see here: https://developer.mozilla.org/en-US/docs/Web/HTML/Element/embed
I believe, what to do when both src and data-videoid is specified is a small-ish detail we can support fairly easily. And we need only a very mild validation on src URL itself.
dvoytenko
commented
8 years ago /cc @ericlindley-g
Gregable
commented
8 years ago This is a good discussion. A few thoughts:
@shimonenator, I tried timing your regexp on a simple youtube.com URL and it looks like parsing + running the regexp takes around 100ms in Chrome on my desktop with beefy CPUs. Probably slower on a phone. I think you believe that validation is happening anyway, which isn't correct. Validation never runs on the client side for a document unless #development=1 is added to the URL. Instead, validation happens in the AMP cache, ahead of the user's request and on beefy hardware.
@dvoytenko, it's important to note that we can't just take any URL and try it because in this case the runtime extracts the videoid for the sake of requesting a thumbnail. It would be nice if we could accept src=https://goo.gl/SsAhv and follow the redirect chain (like we do with amp-img), but the thumbnail loading requires us to be able to parse the videoid much earlier.
@powdercloud, One thing we could imagine doing, in a restricted set of cases, is to perform the transformation in the AMP Cache. The AMP Cache could have logic for replacing src=https://www.youtube.com/watch?v=dQw4w9WgXcQ with data-videoid=dQw4w9WgXcQ. The validator could restrict valid URLs to those that could be transformed by the Cache. The issue still remains what to do for AMP loads from the origin, so the runtime does need this extraction regexp to run on those documents, which still leads us to the performance problems above.
shimonenator
commented
8 years ago @rudygalfi one of the problems with video id is that there's no vendor documentation on the extraction of the ID. By saying it's too much burden to support the extracting, you're essentially asking publishers to do the guessing and carry the burden. Which is understandable but very error prone.
@Gregable 100ms is quite concerning, since you're not processing megabytes of data... There's certainly space for improvement in the original regex, but 100ms is really slow. I will see what I can do to optimize it.
Gregable
commented
8 years ago @shimonenator, if it helps here is the doc I used. It's a pretty quick and dirty test:
<!DOCTYPE html>
<meta charset="utf-8">
<script>
var yturl = 'https://www.youtube.com/watch?v=dQw4w9WgXcQ'
console.time('regex');
var re = /(?:youtu\.be\/|youtube\.com\/(?:watch\?(?:.*&)?v=|(?:embed|v)\/)|playlist\?list=)[^\?&"\'>]+/;
var valid = re.test(yturl);
console.timeEnd('regex');
console.log(valid);
</script>I suspect most of the time is spent constructing the regexp object initially and that putting the test() in a loop would be fast for later calls.
shimonenator
commented
8 years ago @Gregable compare to http://jsbin.com/husuwiqoki/edit?js,console - I get about 0.00016ms per operation on '14 MB Pro Chrome 52.0.2743.82 (64-bit)
Running your version I get regex: 0.096ms
powdercloud
commented
8 years ago I think doing something elaborate - such as attempting to parse all possible YouTube URLs, including playlists, shortened URLs, stuff with parameters, etc ... ... increases complexity, thereby introducing bugs, undocumented behavior, length of documentation, etc., making it harder for developers to use this stuff. ... decreases performance offline and online. ... makes it more difficult for others to implement validation. ... reduces the capacity we have to do other, more valuable work. The URL approach is less trivial than people realize because YouTube URLs carry some parameters with meaning. E.g., one may specify that a video starts at a certain time. But note that the extension also allows this, with data- attrs. Allowing both requires that we implement precedence, document and test it, or alternatively, leave things unspecified and open to grief down the road when rendered documents don't behave in the way that their authors intended. It is sad enough that YouTube's documentation has a fair amount of deprecation comments and so on for these parameters as is.
Gregable
commented
8 years ago @shimonenator , I'm not an expert, but I think that v8 pre-builds the regexp when it first parses it or lazily on each pass through the loop. I doubt you are paying the setup cost on all runs through that loop, only the actual matching cost. It may even be caching the operation result or observing that the result is not used and has no side-effects and optimizing it away (this is why I added the console.log(valid) in my test, to ensure that the result was being computed). I have a hard time believing that this regexp is being evaluated in less than a microsecond which is what jsbin is reporting.
shimonenator
commented
8 years ago @powdercloud if you go with either src only or data- attributes, you won't be running against complexity. Again, assuming we're only talking about high profile names, such as YouTube, there's always going to be numerous eyes and hands to provide an update to the regex quickly, if such a need arises.
Testing is going to be done by unit tests, so hardly any overhead either.
I do not think documentation for src needs to say anything other than paste video URL in here. It will certainly be shorter than explaining in simple terms how to extract video ID from the URL.
Validation - I agree with @dvoytenko that it will be very mild.
And as for performance, please see above numbers, unoptimized regex runs in microseconds, and only once per tag.
powdercloud
commented
8 years ago @shimonenator The data- attributes are always allowed except for those that are explicity mutually exclusive. E.g., I can say it's either src or data-videoid but not both, but I cannot say that if it's src, then no data- parameter can be specified. Note also that the data attributes interact with other amp features, e.g., an amp-youtube tag could be an item in an amp-live-list, and then there'd be data attributes noting when it was published / updated. So we cannot just disallow all data attributes for some specific situation.
shimonenator
commented
8 years ago @Gregable I was worried about pre-compilation which is why I've added 2 tests in there. Here's an updated test with some additional operations. Note, the slowdown is between 2 and 3 times: http://jsbin.com/giginotena/1/edit?js,console
shimonenator
commented
8 years ago @Gregable I've optimized my original regex a little, to make it better structured and easier to read and extend in the future, here's an ![updated regex]:(https://www.debuggex.com/r/h0Db9KgYjoHg8gA3)
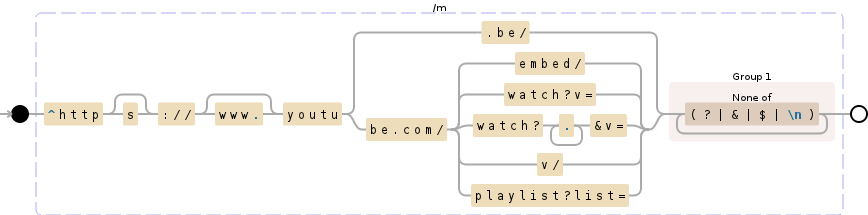
It runs at about the same speed — even in the worst case scenario we're talking about ~0.1ms: http://jsbin.com/vumeziyegi/1/edit?js,console
dvoytenko
commented
8 years ago I still believe we need a simple support for src.
yotube.com?v=VIDEOID and youtu.be/VIDEOID is trivial.videoid should take precedence over src. ericlindley-g
commented
8 years ago
ericlindley-g
commented
8 years ago I favor simple support for src as @dvoytenko describes above (though graceful fallbacks in videoid for URL formats also seem like a reasonable course, and +1 @rudygalfi's slippery slope concerns. Support for multiple approaches like this will need a strong justification—such as: this occurs enough in the wild that the severity to user experience justifies the implementation and maintenance cost—to avoid sliding down the slope)
Regarding the validation changes already in flight in #4381 :
@powdercloud , will the changes in #4381 make it so pages that were previously valid will now be invalidated by the inclusion of the url attribute? Two cases I want to avoid are:
src attribute was used instead of videoid. The video wasn't the primary content on the page, but the page is now invalid in toto.videoid and src specified, so the video was able to be fetched and displayed, albeit with a superfluous attribute. That page is now invalid, though there were no user-facing errors.If the larger solution to this issue will supercede these validation issues, then there's no risk of an issue, but I just wanted to flag these concerns. It occurs to me that changes like this could go through a "warning-first" process, where the validation eventually issues an error, but for some time issues a warning with an indication that it will soon become an error (though of course the overhead to proceed through that process should be commensurate with the benefit in staging it :)
shimonenator
commented
8 years ago @dvoytenko, just curious why are you in favor of multiple regexes?
Gregable
commented
8 years ago @ericlindley-g, regarding #4381, when adding validation constraints, we always compute stats on existing usage so we know what we'll break. In a very large sample, zero documents were using <amp-youtube src=> which isn't surprising given that it didn't work and no documentation mentioned this.
The general approach is that if we're breaking existing docs, and it's not for a critical reason like a security issue, we issue warnings for a short while from the validator, which do not invalidate docs. Later, we switch these to errors which do invalidate docs. If we're not breaking docs (as is in this case), we skip the warning step.
The data driven approach isn't perfect. A site could suddenly implement an invalid change across all of their docs by updating a template, and the timing could be such that we still invalidate the entire site, but it's relatively unlikely in this case.
powdercloud
commented
8 years ago @ericlindley-g The tightening / simplification that I did is mostly live at this point. The easiest way to play / try out the status quo is to load the test case into the web ui. https://goo.gl/3KxuB6 I think it's fine to add support for src as long as it's kept reasonably simple.
ericlindley-g
commented
8 years ago @Gregable @powdercloud That sounds like a great process (not perfect, as you outlined, but very minimal risk, particularly in this case)—I should have known that you had it covered :)
dvoytenko
commented
8 years ago @shimonenator I don't feel too strongly about number of RegEx. My point was simply that we need to only check 1-2 URL forms that a component itself advertises for their embeds. Thus, a full redirect chain is not relevant here. As far as checks themselves - I don't think the URL check needs to be 100% perfect either, we just need to avoid the most obvious errors.
shimonenator
commented
8 years ago @dvoytenko ok, then my regex should be usable
 adelinamart
commented
7 years ago
adelinamart
commented
7 years ago Some of the referenced issues here are closed. Is this still valid?
aghassemi
commented
7 years ago @adelinamart Yes, the original FR is still valid.
aghassemi
commented
5 years ago (I am classifying this as UX instead of DevX since ultimately user wins from unintentional dev mistakes)
 stale[bot]
commented
3 years ago
stale[bot]
commented
3 years ago This issue has been automatically marked as stale because it has not had recent activity. It will be closed in 7 days if no further activity occurs. Thank you for your contributions.
We should either allow Url values for
data-videoidonamp-youtubeand or expose and document asrcattribute as well.Originally a feature request in https://github.com/ampproject/amphtml/issues/361
We have also seen misconfigurations like
<amp-youtube data-videoid="https://youtu.be/UDGKqWyzuRs"in the wild.Also currently
srcpasses validation foramp-youtubebut does not do anything.