 anindita127
commented
2 years ago
anindita127
commented
2 years ago Hi, thanks for your interest in our work. The method is trained with multiple text descriptions for a motion. You'll find the dataset has multiple annotations for the same kind of action so it's more of a many -to-one mapping. We also used a pose discriminator to train the model so it's not deterministic.
 EricGuo5513
EricGuo5513 Mathux
Mathux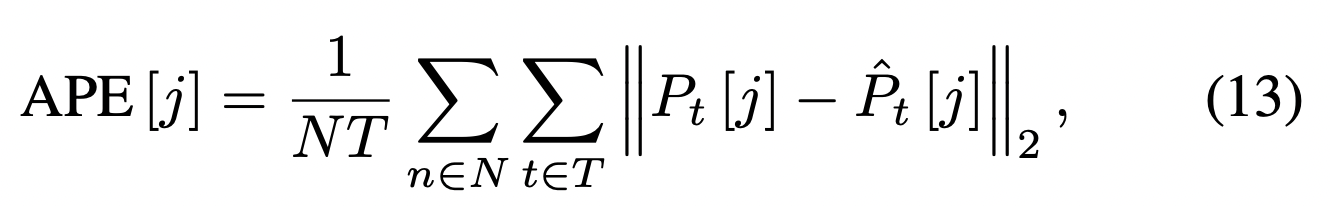
Hi, thanks for your great work on ICCV. I have a question about the usage of text description. As we know, there could be multiple description for each motion animation. However, the proposed method is one-to-one mapping deterministic method. Do we also use mutiple descriptions for each motion during training, or we just keep using one specific description?