 anjia
commented
2 years ago
anjia
commented
2 years ago 关于指数,上面我们只重点介绍了它的“差值”,即 2k-1-1 = 211-1-1 = 210-1 = 1023,因为这和十进制数的存储和读取规则直接相关。
接下来,我们重点讨论下指数的编码。
二. 指数编码
指数的实际范围是从 -1022 到 +1023。如下:
| 11 位指数 e | 实际指数 | 表示 |
|---|---|---|
| 00000000001(2) = 1(10) | 2e-1023 = 2-1022 | 最小指数 |
| 01111111111(2) = 1023(10) | 21023-1023 = 20 | 零偏移 |
| 11111111110(2) = 2046(10) | 22046-1023 = 21023 | 最大指数 |
对于所有的 IEEE 754 格式,指数的 emin = 1 − emax
当指数全 0 和全 1 时,是为特殊数字保留的。如下:
| 11 位指数 e | 实际指数 | 表示 |
|---|---|---|
| 00000000000(2) | 2-1022 | ±0 或 次正规数 |
| 11111111111(2) | 无 | ±Infinity 或 NaN |
当指数全 0 时
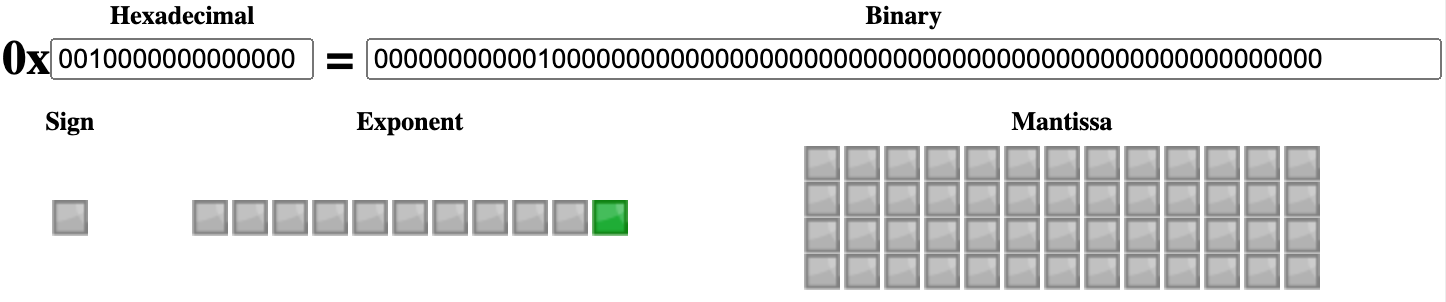
若 52 个有效位全是 0,则表示有符号的 ±0。
若 52 个有效位不全是 0,则表示“次正规数”。此时会将有效数小数点前默认的 1 变成 0,然后实际指数按照指数的最小值(即 -1022)来解释。这么做的目的是通过调整指数来去除有效数的前导 1,以此来表示比最小的“正常数”(相对次正规数而言)更接近 0 的数字。
这样就能填补浮点运算中 0 附近的下溢间隙了,进而避免“即使两个数值不相等,减法 a - b 也会下溢并产生 0”的情况(达到下溢时,会丢弃所有有效数字,然后就突然变 0 了)。所以,次正规数有时也被称为逐渐下溢,因为它允许(值非常小的)计算结果慢慢地失去精度。
次正规数可以保证浮点数的加减法永远不会下溢,两个相邻的浮点数总有一个可以表示的非零差。
在 IEEE 754-2008 中,非正规数(denormal numbers)被重命名为“次正规数”(subnormal numbers)。
当指数全 1 时
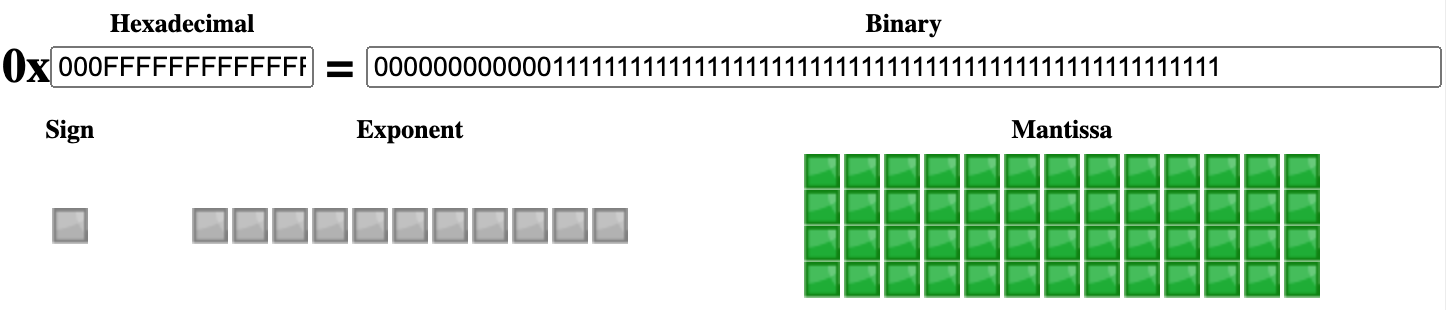
若 52 个有效位全是 0,则表示有符号的 ±Infinity。
若 52 个有效位不全是 0,则表示 NaN。
小结
| 有效位全 0 | 有效位不全 0 | |
|---|---|---|
| 指数全 0 | 表示 ±0 |
表示次正规数,此时: - 有效位的默认前导位由 1 变 0 - 指数按最小指数来解释,即 -1022 |
| 指数全 1 | 表示 ±Infinity |
表示 NaN |
IEEE 754 binary64 真实值
所以,IEEE 754 binary64 真实值的完整情况应该是:

- 当 e = 00000000000 且 f = 00...00 时,真实值是 (-1)sign 0,即
±0 - 当 e = 00000000000 且 f ≠ 00...00 时,真实值是
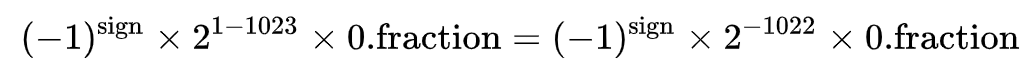
- 当 e = 11111111111 且 f = 00...00 时,真实值是 (-1)sign Infinity,即
±Infinity - 当 e = 11111111111 且 f ≠ 00...00 时,真实值是
NaN - 其它情况,真实值才是
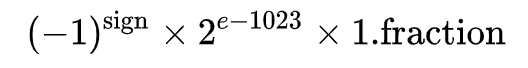
00...00 表示显式存储的 52 个有效位全是 0


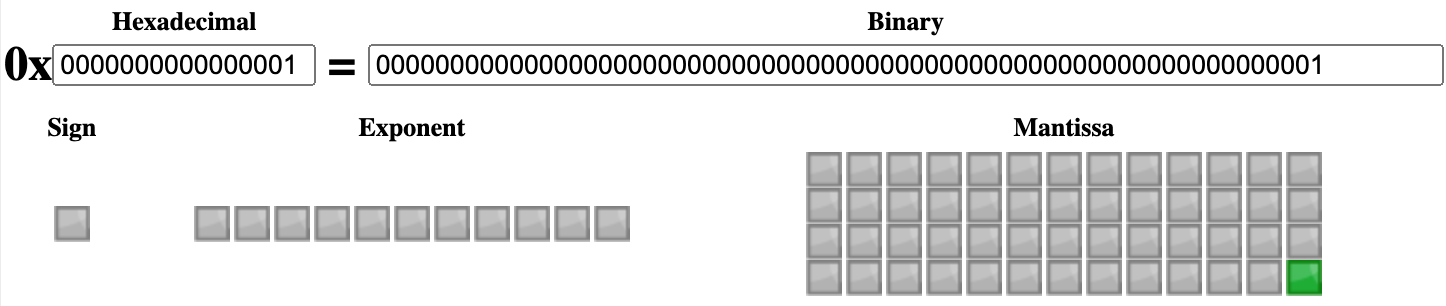
 huangle181
huangle181
目录
双精度浮点格式,也称 FP64 或 float64,是计算机的一种数字格式。通常它在内存中占 64 位,且使用浮动的小数点来表示较宽的数值范围。
在 IEEE 754-2008 标准中,64 位 base-2 格式被正式称为 binary64。它在 IEEE 754-1985 中被称为 double。IEEE 754 也指定了其它浮点格式,包括 32 位 base-2 单精度和最近的 base-10 表示。
最早提供单/双精度浮点数据类型的编程语言之一是 Fortran。在广泛采用 IEEE 754-1985 之前,浮点数据类型的表示和属性取决于计算机制造商、计算机模型以及编程语言的实现者(比如 GW-BASIC 的双精度数据类型是 64 位 MBF 浮点格式)。
一. 双精度二进制浮点数
双精度二进制浮点数,即 binary64,通常也简称为 double。它是 PC 上的常用格式,其范围比单精度浮点数更宽,尽管它的性能和带宽成本都比单精度浮点数的高。
IEEE 754 标准规定 binary64 有:
其中,符号位决定了数字本身的符号。指数是偏差指数,需要减去差值 1023(详见下小节“偏差指数”)。有效数精度是 52 位显式存储加 1 个隐藏位(值固定是 1),所以能表示 53 位。
偏差指数
在 IEEE 754 浮点数中,指数在工程意义上是有偏差的,也称偏差指数(或偏置指数)。
之所以有偏差,是因为指数必须是“有符号”的值才能同时表示微小值和巨大值,但是二进制补码(通常表示有符号值)会使比较变得更加困难。为了解决这个问题,指数被存储为适合比较的“无符号值”,然后在解释的时候“减去偏差”就转成有符号范围内的指数了。
偏差的值是 2k-1-1,其中 k 是指数的位数。比如:
双精度浮点数的指数字段是 11 位无符号整数,值从 0 到 2047。由于全 0 和全 1 的指数值是为特殊数字保留的,所以可用的指数值是从 1 到 2046。减去指数偏差值 1023,就能得到指数的实际范围,即从 -1022 到 +1023。
科学记数法
科学记数法是一种记数的方法。比如:
当数字过大或者过小的时候,用十进制表示通常要写一长串数字,此时用科学记数法就比较方便了。科学家、数学家和工程师们通常使用十进制的科学记数法,部分原因是它可以简化某些算术运算。
在十进制的科学记数法里,非零数字的写法是:a * 10n,其中 1≤|a|<10,n 是整数。
在计算机存储中,更常见的是二进制的科学记数法,即 a * 2n,其中 a 是由 0 和 1 组成的二进制表示,n 是整数。比如:
binary64 的存储
综上,我们知道了给定的 64 位双精度数据在内存中的格式及其含义。
值得一提的是,实际存储的有效数位,是经过归一化或者规范化(normalization)处理的。考虑到有效数字的第一位必然不是 0,对二进制来说那就只能是 1 了,所以它不需要在内存中表示,这样还能让格式再多一位精度。这个规则被称为前导位约定、隐式位约定、隐藏位约定或假定位约定。正因如此,52 位的有效数字位能表示 53 位。
所以,IEEE 754 binary64 格式对应的真实数值就是:
接下来,和大家一起感受下,十进制数值是如何以“双精度二进制浮点数”的格式存储在内存中的。
举几个栗子
要想在计算机中存储十进制数字,需要:
符号(1位) + 指数(11位) + 有效数(52位)的格式,将值依次填充在 64-bit 中即可精度损失以 168 为例
第一步,将十进制转为二进制。168(10) = 1010 1000(2),逻辑如下:
第二步,将二进制写成科学记数法的形式。1010 1000(2) = 1.0101 000(2) * 27 = 1.0101(2) * 27。此时:
第三步,调整指数。7 + (211-1-1) = 7 + 1023 = 1030。转成二进制就是 1030(10) = 100 0000 0110(2),逻辑如下:
第四步,规范化有效数。1.0101 省略首位的 1 之后就变成了 0101。
第五步,用 0 补齐指数(11 位)和有效数(52 位),最后再依次拼接即可。
0100 0000 01100101 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000以 0.125 为例
第一步,将十进制转为二进制。0.125(10) = 0.001(2),逻辑如下:
第二步,将二进制写成科学记数法的形式。0.001(2) = 1(2) * 2-3。此时:
第三步,调整指数。-3 + (211-1-1) = -3 + 1023 = 1020。转成二进制就是 1020(10) = 11 1111 1100(2),逻辑如下:
第四步,规范化有效数。1 省略首位的 1 之后就变成了 0。
第五步,用 0 补齐指数(11 位)和有效数(52 位),最后再依次拼接即可。
0011 1111 11000000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000以 0.1 为例
第一步,将十进制转为二进制。0.1(10) = 0.0 0011 0011 0011 ...(2),逻辑如下:
此时,我们发现出现了循环(0011),用小数部分乘以 2 之后永远也不可能得到小数部分是零的情况。这个时候,就要进行四舍五入了。由于二进制只有 0 和 1,所以就 0 舍 1 入。这个就是计算机在存储小数时会出现误差的原因所在了,但因为保留的位数很多,精度较高,所以在大部分情况下误差可以忽略不计。
第二步,将二进制写成科学记数法的形式。0.0 0011 0011 0011 ...(2) = 1.1001 1001 1001 ...(2) * 2-4。此时:
第三步,调整指数。-4 + (211-1-1) = -4 + 1023 = 1019。转成二进制就是 1019(10) = 11 1111 1011(2),逻辑如下:
第四步,规范化有效数。1.1001 1001 1001 ... 省略首位的 1 之后就变成了 1001 1001 1001 ...。
第五步,用 0 补齐指数(11 位)和有效数(52 位),最后再依次拼接即可。
0011 1111 10111001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1...因为有循环,所以最后一位要四舍五入(0 舍 1 入),最终结果是1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1001 1010结束语
本文重点介绍了双精度二进制浮点数(即 binary64,也称 double)的二进制格式及三个字段的含义。
需要特别注意的是,当它在存储小数的时候,可能会有精度损失(比如上方 0.1 的例子)。
只要是符合 IEEE 754 标准的(如 Fortran 里的
real64类型、Java / C# / C / C++ 中的double类型、JavaScript 中的 Number 类型等),在存储小数的时候都有可能出现误差。这个在对精度要求比较高的场景下,是不能忽略的。常规的替代方案就是将小数转成整数(大数)进行存储和运算,最后显示的时候再恢复成小数形式。主要参考
补充两个在线小工具: