 cheddar
commented
3 years ago
cheddar
commented
3 years ago That smaller stack trace definitely does seem nicer, I looked through the prototype branch and, honestly, wasn't able to fully wrap my head around the difference just from trying to dive into the code that was done. From your description (and the stack trace) it looks like it's a totally different implementation that might be ignoring the Toolchests and Factories, but it seems like it's still using those?
Once I found the Operator interface itself, if I'm understanding it correctly, I believe it is semantically equivalent to the Sequence interface. Iterator open() is semantically equivalent to Yielder<> toYielder() and close() is semantically equivalent to closing that yielder. Sequence also comes with a method that allows for accumulation with a callback, which was useful at one point but who knows how helpful it is anymore (it was pervasive in the way back ago times when Sequences only had the accumulate method and there was no such thing as a Yielder). The only seeming semantic difference between them would be the FragmentContext which is being passed directly into the Operator such that the Operator can close over it in the iterator implementation, where the equivalent thing doesn't happen directly on the Sequence, but rather happens on the QueryRunner call.
Honestly, the more I think about it, the more I think that the reason your stack trace is so much cleaner is because your Operators aren't using generic map/concat type operations but instead all of the logic is bundled together into each class which are implementing the Iterator interface. If someone were to implement the proposed Operators by doing, e.g. a Iterators.map(input.open(context), a -> a + 2) I think you would get the same ugly stack traces with Operators as well.. As such, I think that what this proposal actually boils down to is a suggestion that we stop using map/concat/filter style operators and instead have named classes that do specific things so that the stacktrace is more pretty. Fwiw, making the stack trace more pretty is super useful, so doing that is definitely nice. There's a chance that the whole callback/accumulator structure of the Sequence object still makes the stack traces more ugly, but I think that's not actually the case. The real thing that makes the stack traces so ugly is that we've got all these WrappingSequence and ConcatSequence and other things like that which are masking the actual work being done because the lambda that they do the work with doesn't actually make it into the stack trace.
So, going back to your description, in general, I think that you can actually think of the current QueryRunner as the QueryPlanner (at least, at the segment-level anyway), and the Sequence as the Operator.
All that said, I could be missing some major and I don't think there's any love for any specific way of writing the code. If things can be better, let's make them better. Some of the high level concerns:
1) Technically speaking, the QueryToolChest and QueryRunnerFactories are extension points. It would be good to get clarity on whether this proposal eliminates them as extension points, replaces them with a new extension point, or just magically keeps using them. Depending on which one of those it is, strategies might vary. 2) Query performance and memory management are important. Not to say that the proposal makes those worse, but swapping out the underlying implementation in-place creates a relatively high burden for making sure that there is no adverse impact to performance and memory management of the process in the face of many concurrent queries. Given that I think the proposal is just a stylistic adjustment to the current code without any new or different semantic constructs being added, making that adjustment to stop using concat/map/WrappingSequence, etc. shouldn't actually need to come with any sort of impact on performance, so if that understanding is correct, this is maybe not a big deal. 3) Some parts of the physical plan cannot be determined until the query reaches the segment. For example, if a query is expecting a numerical column, it might still get a String column in one segment and a numerical column in another segment, it needs to be intelligent enough to not balk at this and instead align the String column to be numerical at query time. From your explanation, some of me thought the proposal is to move planning to a top-level thing before segments are visited, but the Operators seem to be running and planning at the segment-level, in which case, this is doing per-segment planning. 4) There might be other requirements that I'm not thinking of immediately, but these are the ones that come to mind first.
Depending on which understanding of the proposal is actually correct, the path to introducing the changes in the "safest" possible manner will be different. Rather than speculating on all of the paths, it probably makes the most sense to come to a conclusion on what is actually different about the proposal as that is the primary input into which path to implementation makes the most sense. Just to summarize, I think getting to that understanding of what is different can probably come from answering two questions:
1) Why is the Operator interface not just different methods for the same semantics as what we have today? 2) What happens to the QueryToolChest and QueryRunnerFactory interfaces in the Operator world?
 paul-rogers
paul-rogers FrankChen021
FrankChen021 github-actions[bot]
github-actions[bot]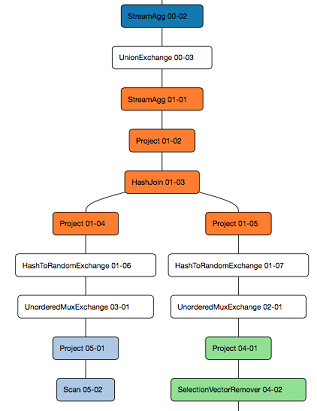{kind=link}
This issue seeks to spur discussion around an idea to make the Druid code a bit easier and faster: borrow ideas from the standard operator structure for the historical nodes (at least) to simplify the current code a bit.
Druid's query engine is based on a unique structure built around the
QueryRunner,Sequence,Yielderand related concepts. The original design is that aQueryRunnercreated (plans) what to do, and returns aSequencewhich does the work. Over time, the code has added more and more layers ofQueryRunners. Also, the code adopts a set of clever functional-programming ideas which uses closures and anonymous inner classes to manage state. The result evolved the original, simple concept into the complex, tightly-bound code we find today.Here, we illustrate that options exist to simplify the code by observing that the resulting Druid code is far more complex than that of similar tools that use the well-known operator structure. (We assume that the advantages of simple code speak for themselves.)
This is not (yet) a proposal. Instead, it is meant to start the conversation.
Background
Most query engines use a structure derived from the earliest System R architecture and clarified by the well-known Volcano paper. The idea is that a query is a sequence of operators, each of which reads from its input, transforms the data, and makes that data available to the output.
When used in a query with joins, the result is a DAG of operators. When used in a query without joins, or in an ETL pipeline, the result is a simple pipeline of operators. For example:
The Volcano paper suggested a specific way to implement the above: each operator is, essentially an iterator: it provides a
next()call which returns the next record (or, in many systems, the next batch of records.) When implemented in the Volcano style, the code is relatively simple, easy to debug and easy to instrument.The solution also works for parallel execution. For example, the Apache Storm project runs each operator concurrently. Apache Drill and Apache Impala parallelize "slices" (or "fragments") of a query (where a slice/fragment is a collection of operators.) Presto/Trino seems to try to get closer to the Storm ability to run (some?) operators concurrently.
Operators are typically stateful. An aggregation maintains its running totals, a limit maintains a count of the records returned thus far, and an ordered merge maintains information about the current row from each input. Because operators are stateful, they can also maintain instrumentation, such as row/batch counts, time spent, and so on. Many products display the resulting metrics as a query profile (proposal for Druid).
Operators are quite easy to test: they are completely agnostic about their inputs and outputs, allowing simple unit tests outside of the entire query system. Quick and easy testing encourages innovation: it becomes low-risk to invent a new operator, try to improve an existing one, and so on.
In typical SQL systems, the query planner creates the operators (or, more typically, a description of the operator.) The Calcite planner does that in Druid: it creates an execution plan with "logical" operators (that is, descriptions of operators.) Here, however, we'll focus on Druid's native queries which use a different approach to planning.
Most systems provide joins as a fundamental operation. In this case, the structure becomes a tree with each join having two inputs. The operator structure has proven to work quite well in such structures.
Druid's
SequenceAbstractionDruid's query stack is build around two fundamental abstractions:
QueryRunnerwhich, despite its name, plans how to return a query by defining a...Sequencewhich represents the result set from a query runner, and performs the actual data reading, transforms, etc.Here we focus on the way that the
Sequenceabstraction has evolved. First, let's compare how the two concepts do their work:QueryPlanner.run()accumulate: pass in something to consume rowsnext()close()on each operator.At a high level, the two concepts are somewhat similar (which is why we can entertain refactoring from one to the other). The challenge seems to be how the code evolved to realize the
Sequenceprotocol. (Note that were we say "row" above, we also include batches of rows.)Two main differences that appear to cause extra complexity is 1) the
Sequence.accumulate()vs.Operator.next()protocol, and 2) how resources are released, theSequencecleanup vs.Operator.close()protocol.A data pipeline consists of a number of operations chained together. Generally, only one has the luxury of a loop which reads all the rows and does something with them. (In Druid, this is the
QueryResource.) All the others need to get one or rows from its input, apply some transform, and return the result to its output (caller.) TheOperatorabstraction models this directly: eachOperatoris given an input to read from, and offers anext()method to return the next result.To achieve the same with the
Sequenceabstraction, theYielderclass was added. AYielderis an "adapter" that converts theSequence.accumulate()method into something a bit closer to an iterator. (With a few notable differences.) TheYielder, in its simplest form, is simply a class which performs the same function as theOperator.next()protocol.Druid's Query Stack
While the above protocol differences are important, they turn out to be much less critical, in practice, than the way in which the
Sequenceabstraction is actually used. TheOperatorabstraction pretty much demands that each operator be a named class that manages its state. The result is that operators have minimal dependencies, can be unit tested, mixed-and-matched, and so on. As @cheddar, points out,Sequences could be defined the same way. The key challenge is that they are not that way today.Much of the current code (at least in the scan query examined thus far) uses a functional programming approach in which the code tries to be stateless. A
QueryRunner, despite its name, does not run a query, and so theQueryRunnerhas no run-time state. Again, as @cheddar, notes, if we think of theQueryRunneras actually being aQueryPlanner, then this makes perfect sense.State is necessary in a query pipeline and the
Sequenceabstraction would be the logical place to keep it. We could define aSequenceclass for each operation, and use member variables to manage that state, just as is done with operators. In such a case, only theaggregate()vs.next(), cleanup vs.close()protocols would be the main question. (See a note below for a prototype of such an approach.)Instead, most code defines state as variables in the
QueryRunner.run()method and passes that state into an anonymousSequenceimplementation via a closure. The result tightly couples theSequenceto theQueryRunner, making unit testing difficult. Further, since theQueryRunner, as part of planing, wants to define the input sequences, we cannot easily break this dependency for testing. Moreover, since the combinedQueryRunner/Sequenceserves one specific use case (e.g., specific inputQueryRunnerto invoke), it is hard to reuse that code for another use case.The result is far more complex than other, similar query implementations. Quite a bit of time is spent navigating the large number of code layers that result. The runtime stack is cluttered with extra "overhead" methods just to handle the protocol, lambdas, and so on.
All that said, the code clearly works quite well and has stood the test of time. The question is, can we do even better?
The Question: Operators for Druid?
This issue asks the question: could Druid be faster, easier to maintain and more extensible if we were to adopt the classic operator approach?
Part of any such discussion is the cost: does this mean a complete rewrite of Druid? What is being proposed is not a rewrite: it is simply a refactoring of what already exists: keep the essence of each operator, but host it in an operator rather than in layers of sequences, yielders, etc.
@cheddar suggests we also consider a less intrusive solution: that the current complexity is more the result of over-use of closures and less a result of the
Sequenceabstraction. It is true the operators, by design, force loose coupling. Could we also achieve that same goal withSequences? This then gives another way to analyze the situation. (See the second prototype below for the results.) As it turns out, the sequence abstraction encourages the use of many small helper classes, as we see in the code today.Summary of Possible Approach
A prototype has been completed of the Scan query stack. Scan query was chosen because it is the simplest of Druid's native query types. The general approach is this:
The
QueryRunnerimplementations already perform planning and return a sequence with the results. The prototype splits this functionality: the planner part is moved into a planner abstraction which creates a required set of operators. The operators themselves perform the run-time aspect currently done by theSequenceandYielderclasses. (See the third prototype below for a less invasive way to refactorQueryRunners.)The above approach reflects the way in which Druid does "just-in-time planning": native queries are planned during the
QueryRunner.run()call: we simply move this logic into an explicit "just-in-time" planner. That planner also does what theQuerySegmentWalkerdoes to plan the overall structure of the query.As it turns out, most
QueryRunners don't actually do anything with data: they instead do planning steps. By moving this logic into the planner, the required set of operators becomes far smaller than the current set ofQueryRunners.With planning done in the planner, the operators become very simple. For the scan, we have operators such as the segment scan, merge, and limit. Developers typically try to optimize the data path to eliminate all unnecessary code. With the operator approach, the only code in the data path is that which obtains or transforms events: all "overhead" is abstracted away.
Example
The easiest way to summarize the potential benefits of the operator approach is with an example. Here is the call stack for a scan query with the debugger stopped in the function which retrieves data from segments:
Here is the exact same query using the code refactored to use operators:
Full disclosure: the scan query is, by far, the simplest native query type in Druid. More work is needed to try the same approach in the more heavy-duty query types such as top-n or group-by.
Possible Implementation Path
Changing Druid's query execution path is a bit like brain surgery: Druid is used in production by a large number of people: we can't risk breaking they query path. Hence, we need a low-risk approach if we wanted to explore this option.
The safest option is to implement the operator approach in parallel with the current approach: enable operators via a feature flag. And, indeed that is how the stack traces above were created. A note below expands on the incremental steps we could take.
Conversion of a native query can be incremental as well. Wrappers allow an operator to act like a
Sequenceand visa-versa, allowing us to migrate one piece of query execution at a time.The development approach could thus be to tackle one native query at a time. Within each, convert one operation at a time. At each step, enable the operator version via a feature flag, defaulting to the operator version only after sufficient testing.
Potential Benefits
We've already mentioned some benefits: simpler code, a tighter data execution path, easier debugging, and easier testing. Other possible benefits include:
Summary
The operator approach has many benefits. A prototype shows that the approach works well for the native scan query. The question that this issue raises is this: is this something that would provide sufficient benefit to the Druid community that we'd want to move to a concrete proposal?