 ad1happy2go
commented
1 year ago
ad1happy2go
commented
1 year ago @HuangFru Did you tried by increasing executor memory? executor--cores you can still keep 5.
Closed HuangFru closed 1 year ago
ad1happy2go
commented
1 year ago @HuangFru Did you tried by increasing executor memory? executor--cores you can still keep 5.
 danny0405
commented
1 year ago
danny0405
commented
1 year ago Yes, it seems we still use the UPSERT code path for the INSERT OVERWRITE TABLE operation, should be optimized to INSERT if possible.
 HuangFru
commented
1 year ago
HuangFru
commented
1 year ago @HuangFru Did you tried by increasing executor memory? executor--cores you can still keep 5.
I'm doing a performance test so I must control variables, I've tried to decrease the number of executors and increase the executor memory, but still OOM.
HuangFru
commented
1 year ago Yes, it seems we still use the
UPSERTcode path for theINSERT OVERWRITE TABLEoperation, should be optimized toINSERTif possible.
Any suggestion for me to carry on this? Should I use 'insert into' to write the data? But usually insert into has worse performant than insert overwrite.
HuangFru
commented
1 year ago @HuangFru Did you tried by increasing executor memory? executor--cores you can still keep 5.
Even if I increase executor memory to 16G, and keep all other resources the same. The same phenomenon will also occur.
 xmubeta
commented
1 year ago
xmubeta
commented
1 year ago I could be wrong, but it is worth to try to run the insert statement on a non-hudi table. I suspect you might get the same error because of too much data.
HuangFru
commented
1 year ago I could be wrong, but it is worth to try to run the insert statement on a non-hudi table. I suspect you might get the same error because of too much data.
I've tried it in the Iceberg, works fine. Iceberg takes about 230s, the same resources to do the same 'insert overwrite'. And I also tried it in Hive, which took more time but works fine.
 KnightChess
commented
1 year ago
KnightChess
commented
1 year ago insert overwrite will still deal with small file, you can use bulk insert avoid it to speed up, but it only support to insert into which is not idempotent operation, you need truncate partitions which you want to insert. Fortunately, the community has related patch support bulk overwrite, #8076 , you can try it.
HuangFru
commented
1 year ago insert overwrite will still deal with small file, you can use
bulk insertavoid it to speed up, but it only support toinsert intowhich is not idempotent operation, you need truncate partitions which you want to insert. Fortunately, the community has related patch support bulk overwrite, #8076 , you can try it.
If the table is empty, will the 'insert into' using 'bulk insert' have better performance than 'insert overwrite'?
KnightChess
commented
1 year ago @HuangFru yes, much better
HuangFru
commented
1 year ago @HuangFru yes, much better
Thanks for your answer. I'll try.
HuangFru
commented
1 year ago insert overwrite will still deal with small file, you can use
bulk insertavoid it to speed up, but it only support toinsert intowhich is not idempotent operation, you need truncate partitions which you want to insert. Fortunately, the community has related patch support bulk overwrite, #8076 , you can try it.
'bulk insert' works fine. According to my understanding, the MOR table will have better performance than the COW table in writing, but I found that the COW table took 450s to finish this and the same MOR table took 500s. Why? In addition, the 450s are much worse than the Iceberg's 230s. Are there some configurations I didn't set?
KnightChess
commented
1 year ago @HuangFru 1.if the primaryKey not exist in the table, it will add parquet first in generally, you can confirm it. 2.Can you confirm your parallelism? or Can you provide spark ui in stage tab, iceberg and hudi
HuangFru
commented
1 year ago @KnightChess
Hudi: SQL(just change the table name):
create table lineitem_kp_mor (
l_orderkey bigint,
l_partkey bigint,
l_suppkey bigint,
l_linenumber int,
l_quantity double,
l_extendedprice double,
l_discount double,
l_tax double,
l_returnflag string,
l_linestatus string,
l_shipdate date,
l_receiptdate date,
l_shipinstruct string,
l_shipmode string,
l_comment string,
l_commitdate date
) USING hudi tblproperties (
type = 'mor',
primaryKey = 'l_orderkey,l_linenumber',
hoodie.memory.merge.max.size = '2004857600000',
hoodie.write.markers.type = 'DIRECT',
hoodie.sql.insert.mode = 'non-strict'
) PARTITIONED BY (l_commitdate);set hoodie.sql.bulk.insert.enable=true; set hoodie.sql.insert.mode=non-strict; set hoodie.bulkinsert.shuffle.parallelism=200;
insert into lineitem_kp_mor select l_orderkey,l_partkey,l_suppkey,l_linenumber,l_quantity,l_extendedprice,l_discount,l_tax,l_returnflag,l_linestatus,l_shipdate,l_receiptdate,l_shipinstruct,l_shipmode,l_comment,l_commitdate from spark_catalog.test_origin.lineitem_sf100 order by l_commitdate;



Iceberg:
ID)
first: insert one record: id = 1
second: insert one record: id = 2
third: insert one record: id = 1
fourth: insert two records: id = 1 and 3KnightChess
commented
1 year ago hoodie.populate.meta.fields false have a try, not populate meta to base fileKnightChess
commented
1 year ago @HuangFru Does the above configuration solve your problem? I found a article desc the benchmark load, you can refer to it: https://www.onehouse.ai/blog/apache-hudi-vs-delta-lake-transparent-tpc-ds-lakehouse-performance-benchmarks
HuangFru
commented
1 year ago @KnightChess Sorry, I'm a little busy recently, I didn't push this thing forward. I'll try it when I'm free.
ad1happy2go
commented
1 year ago @HuangFru Did you got the chance to try above.
HuangFru
commented
1 year ago @HuangFru Did you got the chance to try above.
Not yet, It may be a long time until my next performance test(or I'll forget about it). You can close this issue temporarily. When I do a test next time, I will reopen this issue and give feedback.
 nandubatchu
commented
1 year ago
nandubatchu
commented
1 year ago Hey @ad1happy2go - I too observed similar OOM behaviour on using insert_overwrite_table on reasonably large table (200gb) - works fine with very small tables
ad1happy2go
commented
1 year ago @nandubatchu What executor-memory you were using?
Describe the problem you faced
I'm doing a simple write performance test for Hudi in Spark on Yarn, but my executors will be dead for OOM. And the 'insert overwrite' SQL could be very slow. I've created a table like this:
This is one of the TPC-H Benchmark's table
lineitem, and I add a partition key 'l_commitdate' for it. Then the table will have 2466 partitions. Then I'm trying to write into the table throw 'insert overwrite as select from' in Spark SQL. The data size is 'sf100', with about 600 million rows of data, and 15GB in storage.Here's my command submit to yarn:
Resources: 11 executors, each 8G memory, each 5 cores, driver memory 4G.
The insert overwrite SQL:
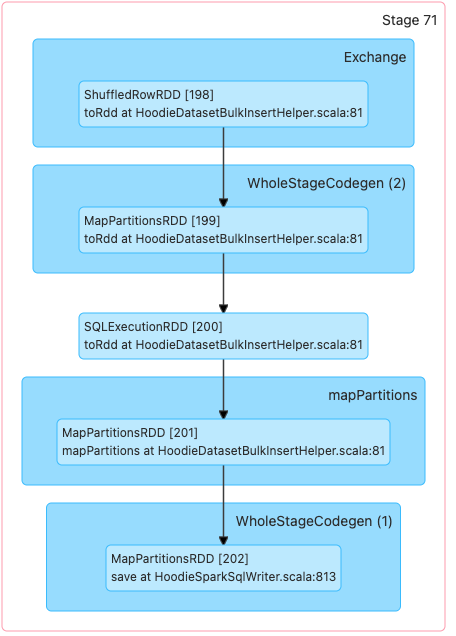
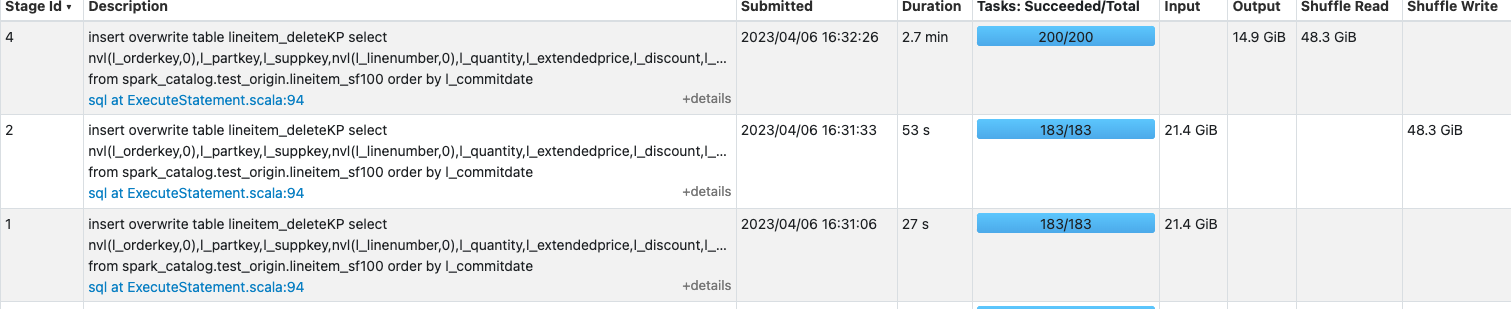
The SQL run very slow and will failed due to executor dead. Executors: Stages:
Stages:
 Dead Executors' log:
Dead Executors' log:

To Reproduce
Steps to reproduce the behavior:
Expected behavior
I don't know if I've missed some important config of something. I'm new to Hudi. Could you please give me some help?
Environment Description
Hudi version : 0.13.0
Spark version : 3.1.3
Hive version : 2.1.1
Hadoop version : 2.7.3
Storage (HDFS/S3/GCS..) : HDFS
Running on Docker? (yes/no) : no
Additional context
Add any other context about the problem here.
Stacktrace