 asfimport
commented
4 years ago
asfimport
commented
4 years ago Adrien Grand (@jpountz) (migrated from JIRA)
CommonTermsQuery probably makes the issue worse by having clauses on multiple levels of boolean queries (see e.g. how the nested boolean queries perform worse than single-level boolean queries in the nightly benchmarks http://people.apache.org/\~mikemccand/lucenebench/AndMedOrHighHigh.html), but this is an issue with BooleanQuery too. We have complex logic that tries to skip as many hits as possible, but when this logic is defeated, which is typically the case when
- there are lots of clauses,
- or clauses have about the same max scores,
- or maximum score upper bounds are highly overestimated (ClassicSimilarity might contribute a bit here too), then we need to pay the price for this overhead without getting any benefits.
What latency do you get if you run a pure disjunction with these clauses instead of a CommonTermsQuery?
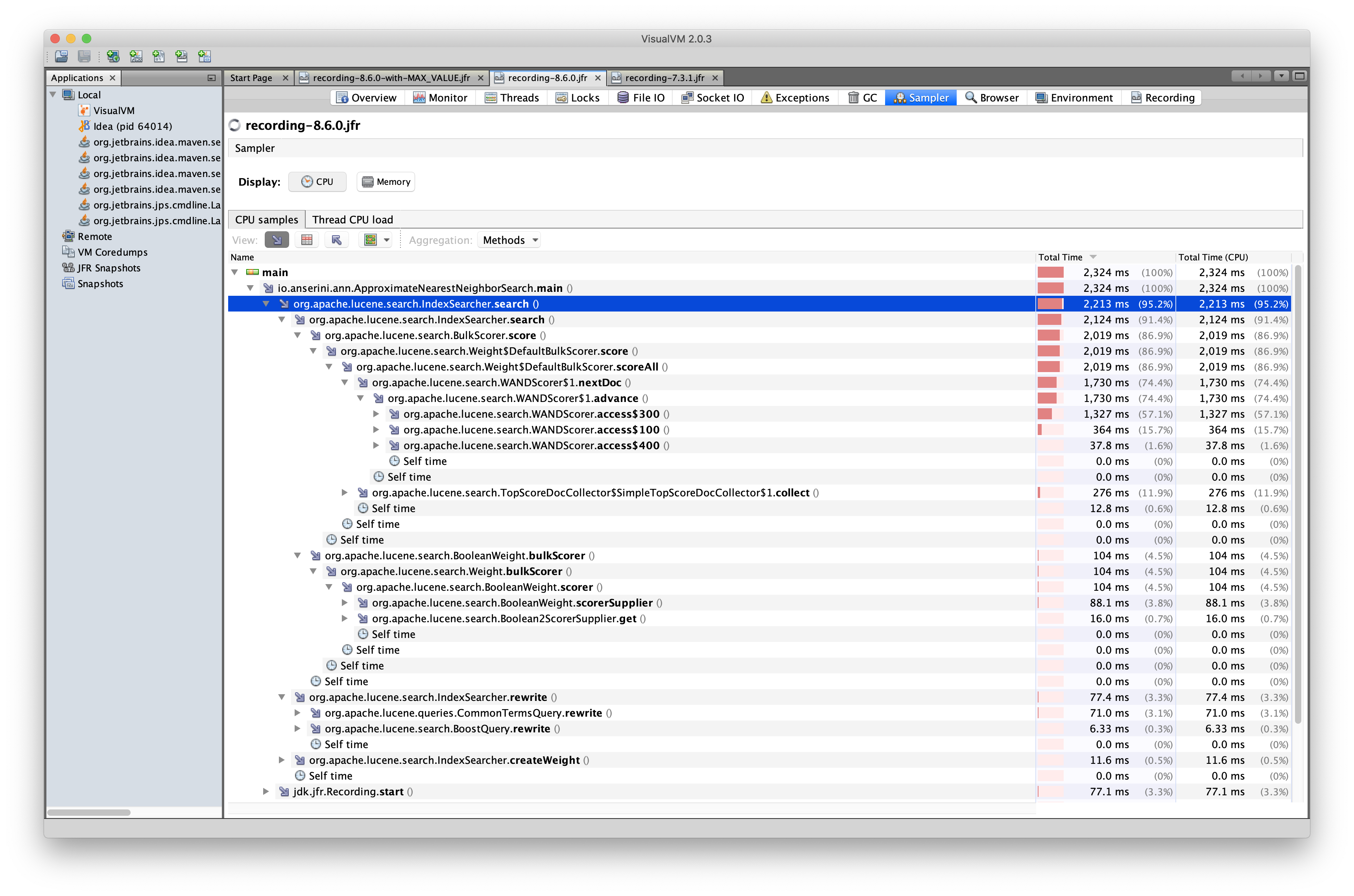
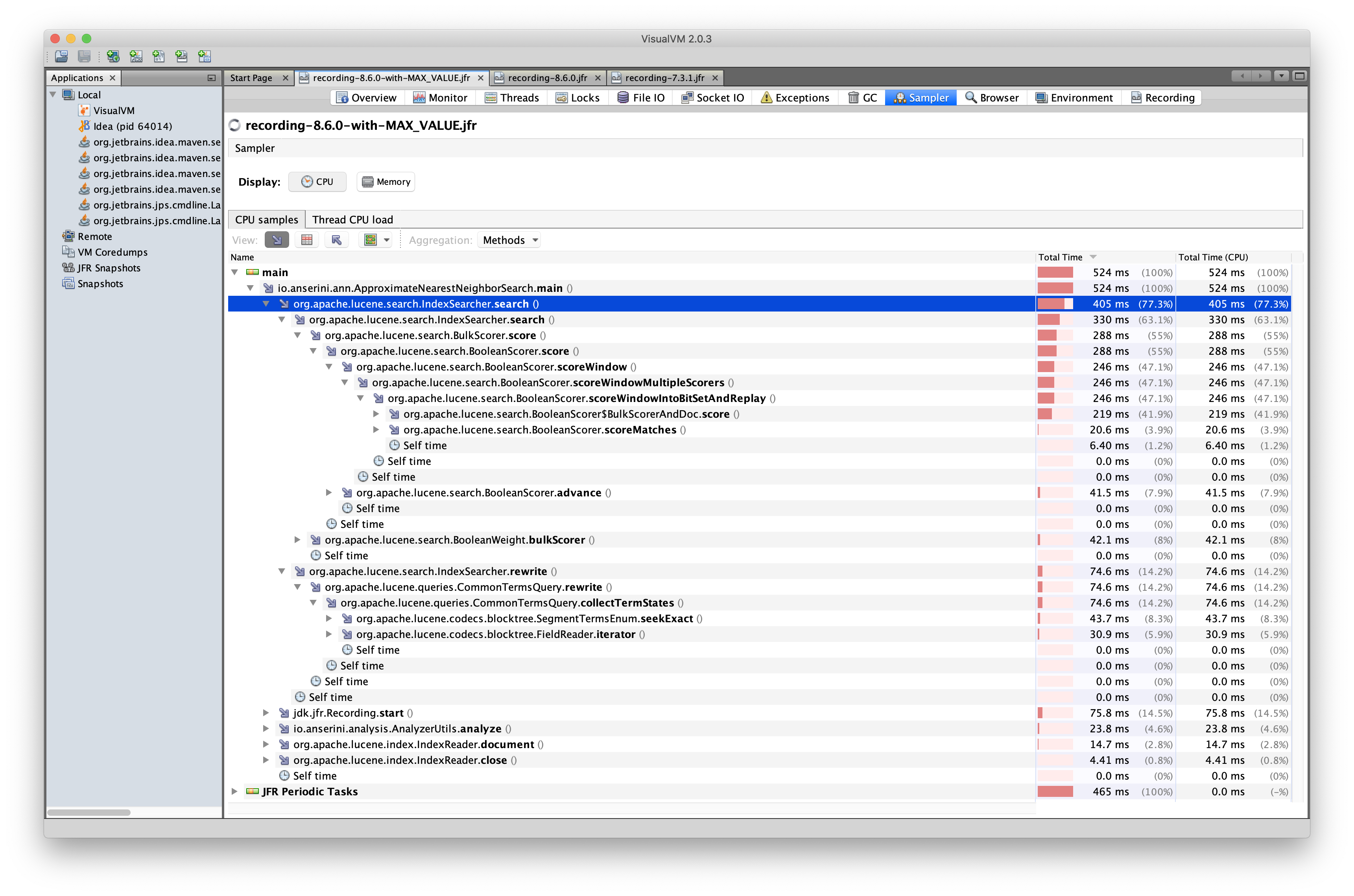
In [1] a
CommonTermsQueryis used in order to perform a query with lots of (duplicate) terms. Using a max term frequency cutoff of 0.999 for low frequency terms, the query, although big, finishes in around 2-300ms with Lucene 7.6.0. However, when upgrading the code to Lucene 8.x, the query runs in 2-3s instead [2]. After digging a bit into it it seems that the regression in speed comes from the fact that top-k scoring introduced by default in version 8 is causing that, not sure "where" exactly in the code though. When switching back to complete hit scoring [3], the speed goes back to the initial 2-300ms also in Lucene 8.3.x. It'd be nice to understand the reason why this is happening and if it is only concerningCommonTermsQueryor affectingBooleanQueryas well. If this is a case that depends on the data and application involved (Anserini in this case), the application should handle it, otherwise if it is a regression/bug in Lucene it'd be nice to fix it.[1] : https://github.com/tteofili/Anserini-embeddings/blob/nnsearch/src/main/java/io/anserini/embeddings/nn/fw/FakeWordsRunner.java [2] : https://github.com/castorini/anserini/blob/master/src/main/java/io/anserini/analysis/vectors/ApproximateNearestNeighborEval.java [3] : https://github.com/tteofili/anserini/blob/ann-paper-reproduce/src/main/java/io/anserini/analysis/vectors/ApproximateNearestNeighborEval.java#L174
Migrated from LUCENE-9107 by Tommaso Teofili (@tteofili), updated Aug 07 2020 Attachments: image-2020-08-07-16-54-27-905.png, Screenshot 2020-08-07 at 16.20.01.png, Screenshot 2020-08-07 at 16.20.05.png