 asfimport
commented
4 years ago
asfimport
commented
4 years ago Xin-Chun Zhang (migrated from JIRA)
I worked on this issue for about three to four days. And it now works fine for searching.
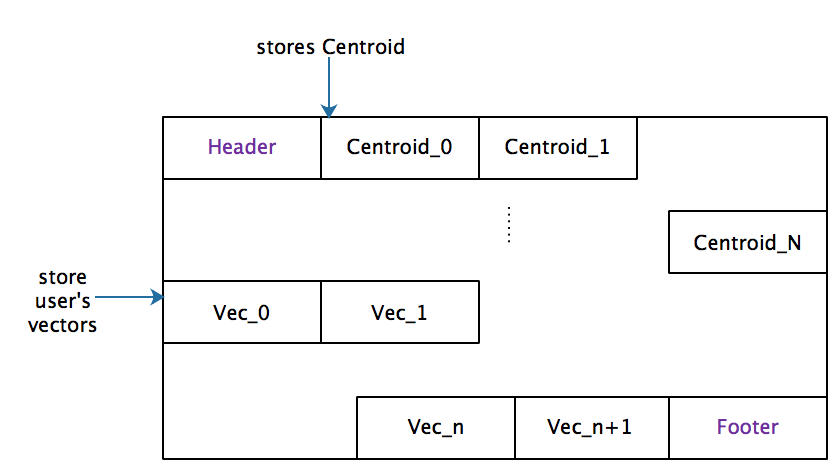
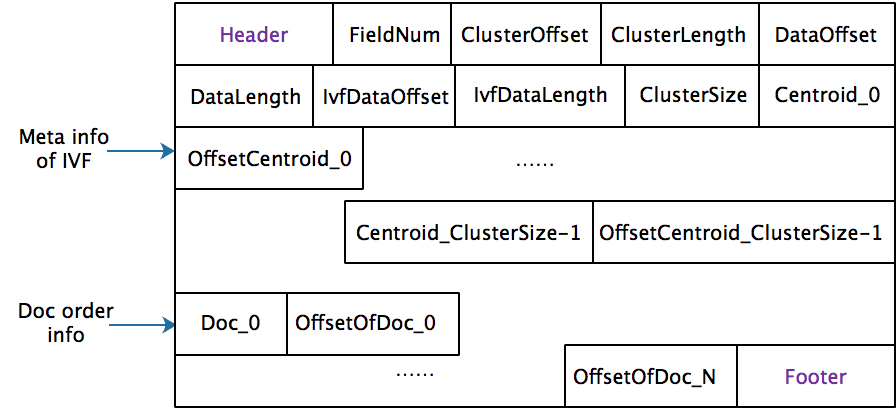
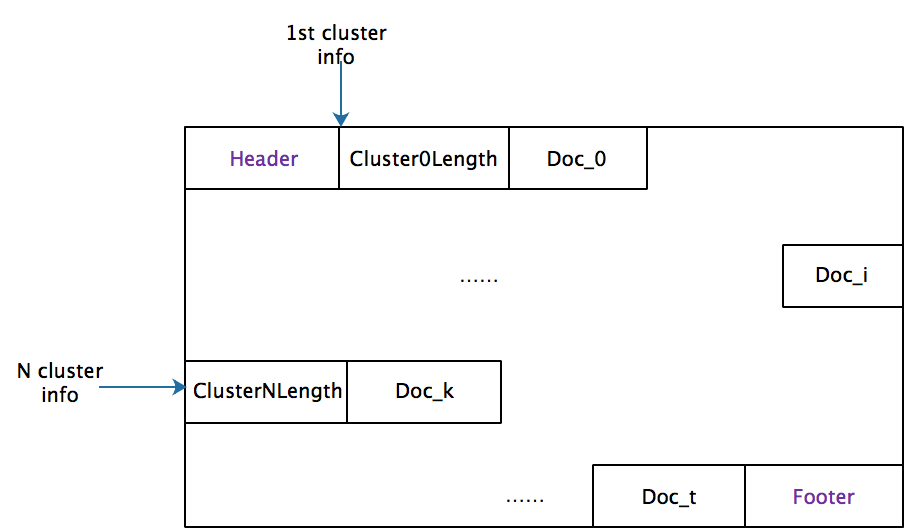
My personal dev branch is available in github https://github.com/irvingzhang/lucene-solr/tree/jira/LUCENE-9136. The index format (only one meta file with suffix .ifi) of IVFFlat is shown in the class Lucene90IvfFlatIndexFormat. In my implementation, the clustering process was optimized when the number of vectors is sufficient large (e.g. > 200,000 per segment). A subset after shuffling is selected for training, thereby saving time and memory. The insertion performance of IVFFlat is better due to no extra executions on insertion while HNSW need to maintain the graph. However, IVFFlat consumes more time in flushing because of the k-means clustering.
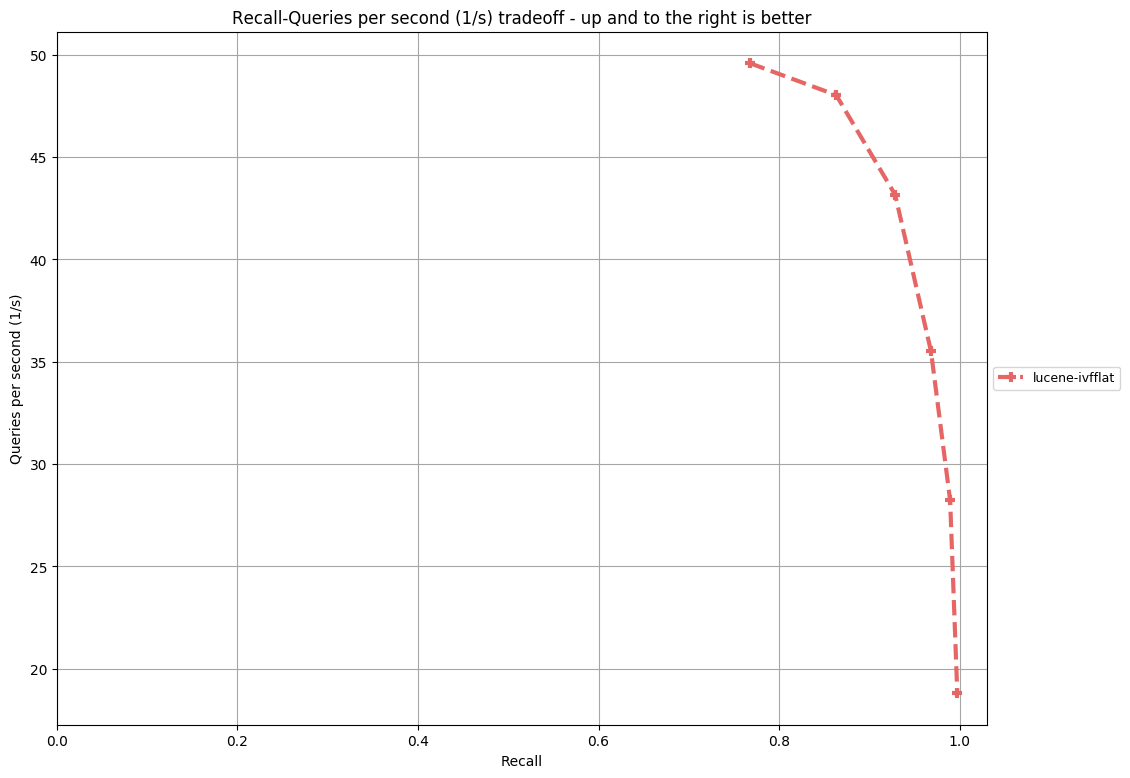
My test cases show that the query performance of IVFFlat is better than HNSW, even if HNSW uses a cache for graphs while IVFFlat has no cache. And its recall is pretty high (avg time <10ms and recall>96% over a set of 50000 random vectors with 100 dimensions). My test class for IVFFlat is under the directory https://github.com/irvingzhang/lucene-solr/blob/jira/LUCENE-9136/lucene/core/src/test/org/apache/lucene/util/ivfflat/. Performance comparison between IVFFlat and HNSW is in the class TestKnnGraphAndIvfFlat.
The work is still in its early stage. There must be some bugs that need to be fixed and and I would like to hear more comments. Everyone is welcomed to participate in this issue.
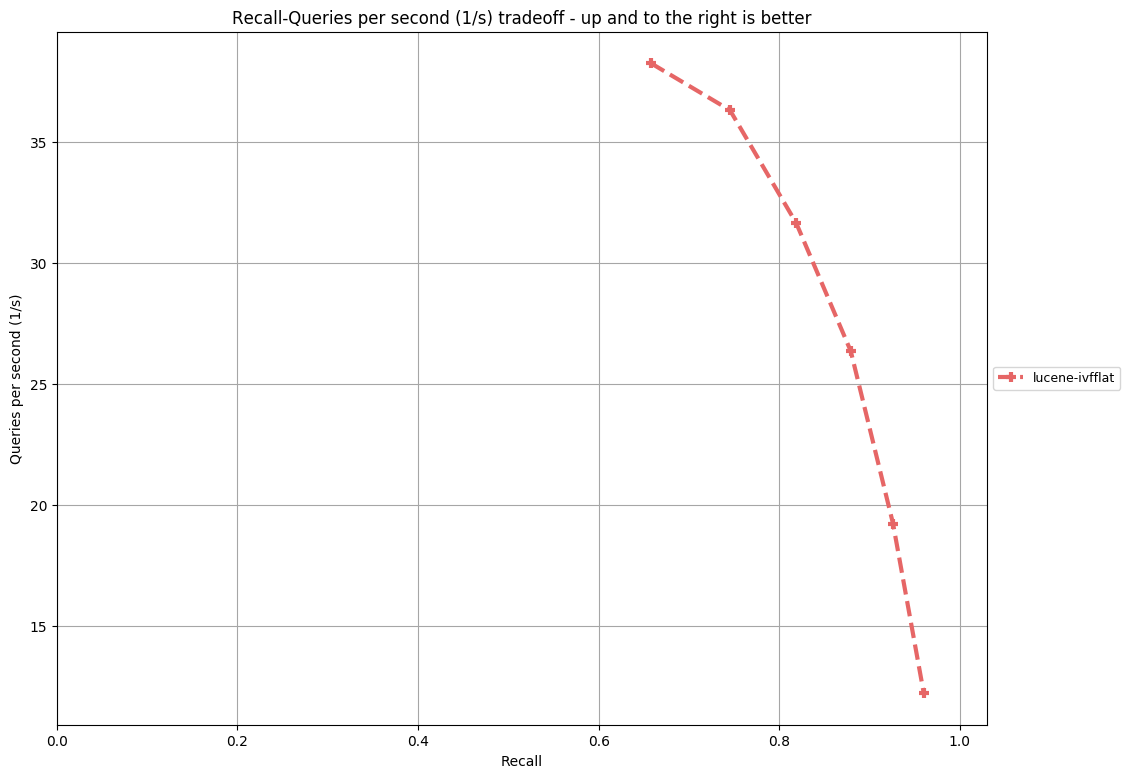
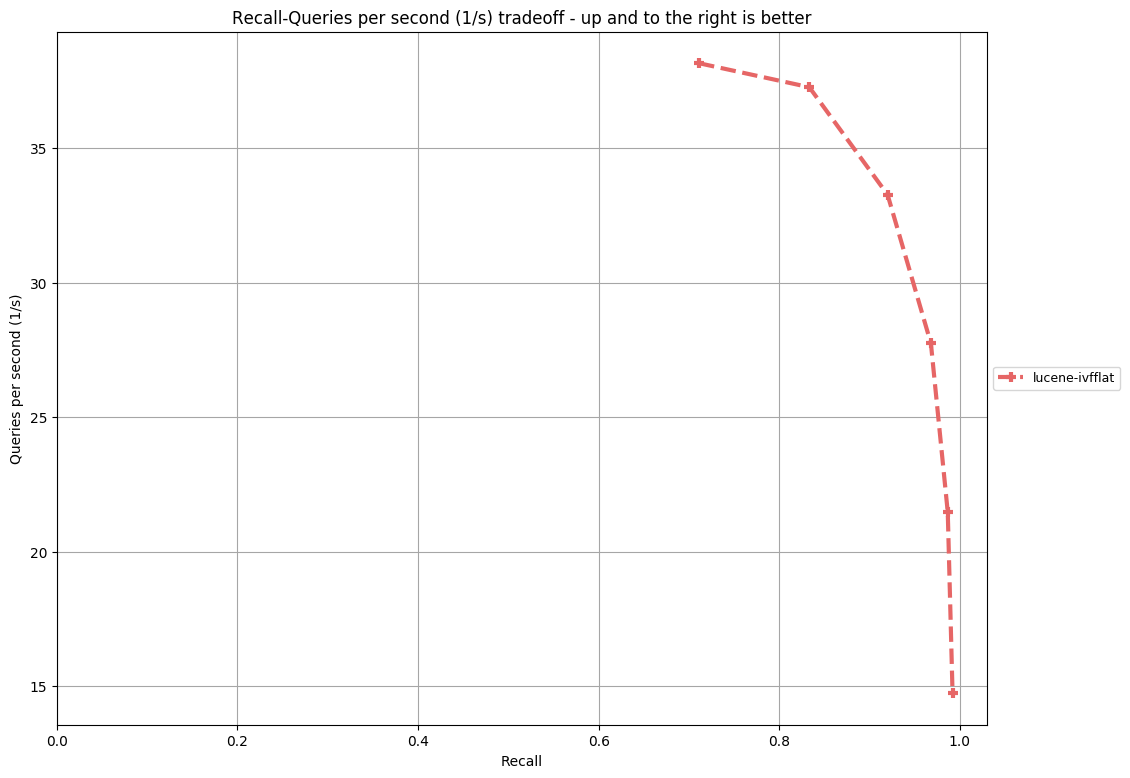
 Mahdi-Seeker
Mahdi-Seeker
Representation learning (RL) has been an established discipline in the machine learning space for decades but it draws tremendous attention lately with the emergence of deep learning. The central problem of RL is to determine an optimal representation of the input data. By embedding the data into a high dimensional vector, the vector retrieval (VR) method is then applied to search the relevant items.
With the rapid development of RL over the past few years, the technique has been used extensively in industry from online advertising to computer vision and speech recognition. There exist many open source implementations of VR algorithms, such as Facebook's FAISS and Microsoft's SPTAG, providing various choices for potential users. However, the aforementioned implementations are all written in C+, and no plan for supporting Java interface, making it hard to be integrated in Java projects or those who are not familier with C/C+ [[https://github.com/facebookresearch/faiss/issues/105]].
The algorithms for vector retrieval can be roughly classified into four categories,
where IVFFlat and HNSW are the most popular ones among all the VR algorithms.
IVFFlat is better for high-precision applications such as face recognition, while HNSW performs better in general scenarios including recommendation and personalized advertisement. The recall ratio of IVFFlat could be gradually increased by adjusting the query parameter (nprobe), while it's hard for HNSW to improve its accuracy. In theory, IVFFlat could achieve 100% recall ratio.
Recently, the implementation of HNSW (Hierarchical Navigable Small World, LUCENE-9004) for Lucene, has made great progress. The issue draws attention of those who are interested in Lucene or hope to use HNSW with Solr/Lucene.
As an alternative for solving ANN similarity search problems, IVFFlat is also very popular with many users and supporters. Compared with HNSW, IVFFlat has smaller index size but requires k-means clustering, while HNSW is faster in query (no training required) but requires extra storage for saving graphs [indexing 1M vectors|[https://github.com/facebookresearch/faiss/wiki/Indexing-1M-vectors]]. Another advantage is that IVFFlat can be faster and more accurate when enables GPU parallel computing (current not support in Java). Both algorithms have their merits and demerits. Since HNSW is now under development, it may be better to provide both implementations (HNSW && IVFFlat) for potential users who are faced with very different scenarios and want to more choices.
The latest branch is lucene-9136-ann-ivfflat](https://github.com/irvingzhang/lucene-solr/commits/jira/lucene-9136-ann-ivfflat)
Migrated from LUCENE-9136 by Xin-Chun Zhang, 3 votes, updated Dec 09 2020 Attachments: glove-100-angular.png, glove-25-angular.png, image-2020-03-07-01-22-06-132.png, image-2020-03-07-01-25-58-047.png, image-2020-03-07-01-27-12-859.png, sift-128-euclidean.png