 asfimport
commented
9 years ago
asfimport
commented
9 years ago Ian Ribas (@ianribas) (migrated from JIRA)
The patch with the initial work.
Closed asfimport closed 7 years ago
asfimport
commented
9 years ago Ian Ribas (@ianribas) (migrated from JIRA)
The patch with the initial work.
asfimport
commented
9 years ago Michael McCandless (@mikemccand) (migrated from JIRA)
I will dig more into this patch, it is a nice (big!) change, but this TODO caught my eye:
// TODO: Problems: In the substitution below, how to identify that the terms "united" "states" "of" "america"
// are actually a phrase and not individual synonyms of "usa"? And how to differentiate that phrase from the
// phrase "u" "s" "a"? We can do that adding position lengths ...One approach could be to use TokenStreamToAutomaton, then enumerate all finite strings from the resulting automaton, and assert it's as expected? I.e. that things did not get unexpectedly "sausaged"?
asfimport
commented
9 years ago Michael McCandless (@mikemccand) (migrated from JIRA)
Example images.
asfimport
commented
9 years ago Michael McCandless (@mikemccand) (migrated from JIRA)
Just to confirm the scope of this change, if I have these synonyms:
wtf --> what the fudge
wtf --> wow that's funnyAnd then I'm tokenizing this:
wtf happenedBefore this change (today) I get this crazy sausage incorrectly matching phrases like "wtf the fudge" and "wow happened funny":

But after this change, the expanded synonyms become separate paths in the graph right? So it will look like this?:
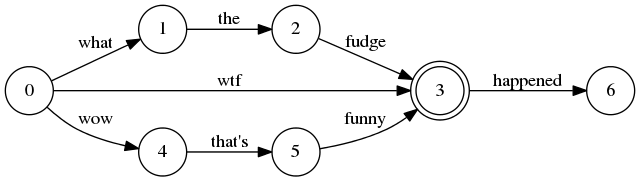
Matching exactly the right phrases? Note that absolute position numbers become somewhat meaningless now ... they are really "node IDs".
Some small things I noticed:
originalInputIdx = -10;Why -10?
Can we just add the new test cases into the existing (tiny) TestMultiWordSynonyms.java?
Related: #6076 is an effort to make such "graph consuming and producing token streams" easier ... but that's a major change to the TokenStream API.
In the case where a given input token matches no rules in the FST, are we still able to pass that through to the output without buffering (calling capture())?
asfimport
commented
9 years ago Ian Ribas (@ianribas) (migrated from JIRA)
This comment was written early in my attempts and I'm afraid I didn't review it later. In the final solution, it is much clearer that the longer terms are not individual synonyms of the shorter terms, specially since the longest version is what appears first on the output. I'll have to change the comment, and take away the TODO (it was a marker for things to remember to ask when submitting).
I don't think things will get "sausaged", but I'll look into TokenStreamToAutomaton to see if I can understand it enough to use it.
What might still happen is that a phrase "u s of america" would match, as is implied on the second question on the comment above, which is a lesser problem but still kind of wrong. More on that below.
asfimport
commented
9 years ago Ian Ribas (@ianribas) (migrated from JIRA)
Another example image.
asfimport
commented
9 years ago Ian Ribas (@ianribas) (migrated from JIRA)
> But after this change, the expanded synonyms become separate paths in > the graph right? So it will look like this? > Matching exactly the right phrases?
Actually, I think it looks more like this:
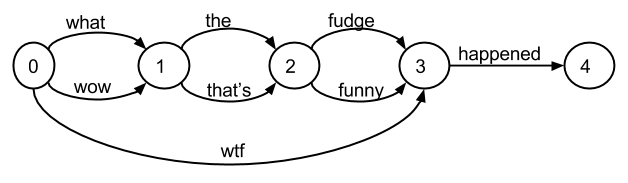
That means that "wtf the fudge" and "wow happened funny" will no longer match, but "wow the fudge" would.
The absolute positions still have meaning. I couldn't figure out how to clearly separate the two phrases from the rules (as was mentioned on the TODO comment above) using the token attributes. They will be stacked in the same order on each position, but that doesn't seem to be enough to make things unambiguous. Specially since with rules like:
pass, ticket
cheap, unexpensiveand tokenizing:
cheap passI would expect to mach all the resulting combinations: "cheap pass", "unexpensive pass", "cheap ticket" and "unexpensive ticket". And there is no difference in the representation of the tokens "unexpensive" as a synonym for "cheap" from "wow" as a synonym for "what" on the previous rules, using the attributes.
> Why -10?
I was unsure if -1 as an invalid value was clear enough and ended up using -10. It could probably just be -1. I'll check.
> Can we just add the new test cases into the existing (tiny) TestMultiWordSynonyms.java?
Probably. Since all tests in the new file use the new constructor to force the new behavior, and TestMultiWordSynonyms tests the old behavior, I didn'tt want to mix things. But I'll just join them, with a comment on the test to make it clear its the old behavior.
> In the case where a given input token matches no rules in the FST, are > we still able to pass that through to the output without buffering > (calling capture())?
I didn't test this specifically, but would think yes. The new behavior only handles matches differently, I didn't have to do any extra buffering before the match, nor did I change anything on the matching part of the code. The extra buffering is needed only when there was already buffering (lookahead for a partial match) and the synonym was longer than the match.
asfimport
commented
9 years ago Ian Ribas (@ianribas) (migrated from JIRA)
New patch with minor fixes: changed -10 to -1 (it was a leftover that I had overlooked, sorry for that).Changed the comment on the TODO, making it clearer what the problem is: output is still a sausage for multiple multi term synonyms.
Unfortunately, I could not merge the tests into a single file because they have different base classes and the new tests depend on asserts on the base class.
asfimport
commented
9 years ago Michael McCandless (@mikemccand) (migrated from JIRA)
changed -10 to -1
Thank you!
Unfortunately, I could not merge the tests into a single file because they have different base classes and the new tests depend on asserts on the base class.
Ugh, OK, thanks for trying. It's fine to leave it separate...
The absolute positions still have meaning.
OK but with this change we have now created new nodes (something SynFilter does not do today), because wtf now has posLen=3. This is great (necessary!) for SynFilter to be correct...
And there is no difference in the representation of the tokens "unexpensive" as a synonym for "cheap" from "wow" as a synonym for "what" on the previous rules, using the attributes.
Well, it is entirely possible for PosInc/PosLenAtt to express the correct graph, it's just hairy to implement, but I think your patch is part way there (it creates new positions!).
E.g. here's a sequence of tokens that would be the fully correct graph output for the wtf example:
| token | posInc | posLen |
|---|---|---|
| wtf | 1 | 5 |
| what | 0 | 1 |
| wow | 0 | 3 |
| the | 1 | 1 |
| fudge | 1 | 3 |
| that's | 1 | 1 |
| funny | 1 | 1 |
| happened | 1 | 1 |
It corresponds to this graph:
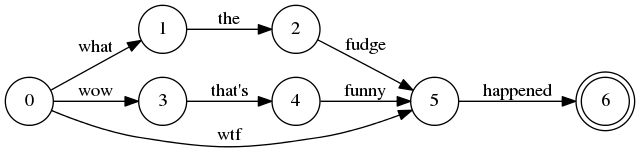
The token posInc/posLen is just a "rote" serialization of the arcs of the graph based on how the states are numbered, and other numberings would be possible resulting in different token outputs because there is inherent ambiguity in how you serialize a graph. I think the only constraints are that 1) all arcs leaving a given state must be serialized one after another (exactly like Lucene's Automaton class!), 2) an arc from node X must go to another node > X (i.e., arcs cannot go to an earlier numbered node).
asfimport
commented
9 years ago Ian Ribas (@ianribas) (migrated from JIRA)
I really hadn't thought of using position lengths as "references", like this! For some reason I could only think of position length spanning over terms on the "base" stream, not creating independent branches. And so I was stuck in thinking how to represent the graph correctly once I saw that my implementation was still a "sausage" on the overlapping phrases.
I will try to implement this solution and see how far I can get.
One problem that I see is that I'll need more buffering as now the future output is no longer the size of the longest synonym but the added sizes of all synonyms that are phrases (each minus one). Getting this number at the beginning might require a change on the synonym parser...
One other doubt I have is how this affects the indexer. I imagine it saves position lengths on the index too, so this shouldn't be a problem, right?
Thanks very much for such clear guidelines!
asfimport
commented
9 years ago Michael McCandless (@mikemccand) (migrated from JIRA)
I really hadn't thought of using position lengths as "references", like this!
It's hard to think about :) But it "just" means the positions become node IDs, and you must number the nodes "properly" (so that any token always goes from node X to Y where Y > X).
One problem that I see is that I'll need more buffering
I think that's fine, I think better correctness trumps the added buffering cost.
One other doubt I have is how this affects the indexer. I imagine it saves position lengths on the index too, so this shouldn't be a problem, right?
The index does NOT record position length today... I think if we fix syn filter here to produce the correct graph, we should also insert a "sausagizer" phase that turns this graph back into a sausage for indexing? (So that "what the fudge" and "wow that's funny" will in fact match a document that had "wtf").
However, if you apply syn filter at search time, we could fix query parsers to possibly "do the right thing" here, e.g. translating this graph into a union of phrase queries, or using TermAutomatonQuery (in sandbox still), or something ...
asfimport
commented
9 years ago Ian Ribas (@ianribas) (migrated from JIRA)
Ok, I think I have an idea on how to do this, but it will definitely need some thinking, so it will probably take a while.
I think that's fine, I think better correctness trumps the added buffering cost.
I completely agree.
I think if we fix syn filter here to produce the correct graph, we should also insert a "sausagizer" phase that turns this graph back into a sausage for indexing?
I think Robert also commented something on these lines in his answer to my email. I think I understand the general idea of what that means, but I would certainly appreciate some guidance, when the time comes. I'll focus on producing a correct graph first.
This also means that maybe I'll need changes on the test validations, since we might run into conditions that are considered wrong now. Specially regarding offsets (start and end) and their relation to position lengths. But I'll see what I can do about that too.
However, if you apply syn filter at search time, we could fix query parsers to possibly "do the right thing" here
I was planning taking a shot at that too, once this part is finished. To make the solution more complete. And, again, I'll certainly appreciate ideas when the time comes.
asfimport
commented
9 years ago Robert Muir (@rmuir) (migrated from JIRA)
Can we consider mike's "crazy graph" as a second step? I don't know, it just seems like the current patch might be an easier-to-digest improvement. Then again I get totally lost in the synonymfilter :)
There is a lot still to do after even this first step before users get real improvements, for instance fixing querybuilder for the boolean case (hopefully easier now), and improving stuff like sandbox/TermAutomatonQuery (maybe?) for the positional case, and so on.
If we spend the work on a hypercorrect graph for synonymfilter I'm just afraid of things getting lost, queryparser can't make use of it because posinc/poslen semantics become too confusing, analysis is hard to reason about because posinc/poslen semantics are too confusing, more performance tradeoffs (like graph re-sausaging at index time), ...
asfimport
commented
9 years ago Michael McCandless (@mikemccand) (migrated from JIRA)
I agree @rmuir, we can do the "correct graph" as a follow-on issue; this one is already a good step towards that.
I'll look more closely at this patch.
I can also help with "phase 2" ... e.g. maybe build the re-sausagizer filter. I do think "phase 2" may result in a simpler syn filter implementation ... some of the complexity in the current one is because it's being forced to sausagify at the same time as producing synonyms, so if we can more cleanly split out those two functions maybe we get simpler code ... not sure.
asfimport
commented
9 years ago Ian Ribas (@ianribas) (migrated from JIRA)
I'll be glad to help either way. I trust whatever priority you both decide.Where should I start looking for the next step? QueryBuilder?
some of the complexity in the current one is because it's being forced to sausagify at the same time as producing synonyms, so if we can more cleanly split out those two functions maybe we get simpler code
Very good point! It does depend, though, on how the graph is represented, of course. I'll try to keep this in mind when working on the "correct graph" (now or later).
asfimport
commented
9 years ago Ian Ribas (@ianribas) (migrated from JIRA)
Added one test with automaton (following @mikemccand's first comment) to clearly show sausagization.
asfimport
commented
9 years ago Michael McCandless (@mikemccand) (migrated from JIRA)
Thanks @ianribas!
I've opened #7696 to create a "graph flattener" TokenFilter, and it seems to work well ... I'm going to now try to simplify SynFilter by removing the hairy graph flattening it must do today, and have it create correct graph outputs. I think with the combination of these two we can then have 100% accurate synonym graphs for accurate query-time searches, but also have the "sausagized" version that indexing needs to "match" the graph corruption we do today.
asfimport
commented
9 years ago Michael McCandless (@mikemccand) (migrated from JIRA)
I'm going to now try to simplify SynFilter by removing the hairy graph flattening it must do today
I opened #7722 for this... it seems to work!
asfimport
commented
7 years ago Michael McCandless (@mikemccand) (migrated from JIRA)
This has been fixed with the addition of SynonymGraphFilter in #7722.
Some time ago, I had a problem with synonyms and phrase type queries (actually, it was elasticsearch and I was using a match query with multiple terms and the "and" operator, as better explained here: https://github.com/elastic/elasticsearch/issues/10394).
That issue led to some work on Lucene: #7460 (where I helped a little with tests) and #7461. This issue is also related to #4916.
Starting from the discussion on #7460, I'm attempting to implement a solution. Here is a patch with a first step - the implementation to fix "SynFilter to be able to 'make positions'" (as was mentioned on the issue). In this way, the synonym filter generates a correct (or, at least, better) graph.
As the synonym matching is greedy, I only had to worry about fixing the position length of the rules of the current match, no future or past synonyms would "span" over this match (please correct me if I'm wrong!). It did require more buffering, twice as much.
The new behavior I added is not active by default, a new parameter has to be passed in a new constructor for
SynonymFilter. The changes I made do change the token stream generated by the synonym filter, and I thought it would be better to let that be a voluntary decision for now.I did some refactoring on the code, but mostly on what I had to change for may implementation, so that the patch was not too hard to read. I created specific unit tests for the new implementation (
TestMultiWordSynonymFilter) that should show how things will be with the new behavior.Migrated from LUCENE-6582 by Ian Ribas (@ianribas), 1 vote, resolved Jan 03 2017 Attachments: after.png, after2.png, after3.png, before.png, LUCENE-6582.patch (versions: 3) Linked issues:
7696