 asfimport
commented
6 years ago
asfimport
commented
6 years ago Adrien Grand (@jpountz) (migrated from JIRA)
Thanks for opening this one @tokee. I agree that the current encoding is not great, it was mostly a minor evolution from the previous dense format in order for things to work not too bad with sparse data, we should probably re-think it entirely. I know Robert suggested we should try to encode things more like postings, eg. with skip data.
Unfortunately this lookup-table cannot be generated upfront when the writing of values is purely streaming
Since this lookup table would be loaded into memory, we would typically write it into the meta file (extension: dvm) rather than into the data file (extension: dvd) so I don't think it would be an issue in practice.
It would be far better to generate the rank-structure at index time and store it immediately before the bitset (this is possible with streaming as each block is fully resolved before flushing), but of course that would require a change to the codec.
+1 FWIW I don't have any objections to modifying the current format for doc values, I think it's much needed. Happy to help if you need guidance.


The
Lucene70DocValuesProducerhas the internal classesSparseNumericDocValuesandBaseSortedSetDocValues(sparse code path), which again usesIndexedDISIto handle the docID -> value-ordinal lookup. The value-ordinal is the index of the docID assuming an abstract tightly packed monotonically increasing list of docIDs: If the docIDs with corresponding values are[0, 4, 1432], their value-ordinals will be[0, 1, 2].Outer blocks
The lookup structure of
IndexedDISIconsists of blocks of 2^16 values (65536), where each block can be eitherALL,DENSE(2^12 to 2^16 values) orSPARSE(< 2^12 values \~= 6%). Consequently blocks vary quite a lot in size and ordinal resolving strategy.When a sparse Numeric DocValue is needed, the code first locates the block containing the wanted docID flag. It does so by iterating blocks one-by-one until it reaches the needed one, where each iteration requires a lookup in the underlying
IndexSlice. For a common memory mapped index, this translates to either a cached request or a read operation. If a segment has 6M documents, worst-case is 91 lookups. In our web archive, our segments has \~300M values: A worst-case of 4577 lookups!One obvious solution is to use a lookup-table for blocks: A long[]-array with an entry for each block. For 6M documents, that is < 1KB and would allow for direct jumping (a single lookup) in all instances. Unfortunately this lookup-table cannot be generated upfront when the writing of values is purely streaming. It can be appended to the end of the stream before it is closed, but without knowing the position of the lookup-table the reader cannot seek to it.
One strategy for creating such a lookup-table would be to generate it during reads and cache it for next lookup. This does not fit directly into how
IndexedDISIcurrently works (it is created anew for each invocation), but could probably be added with a little work. An advantage to this is that this does not change the underlying format and thus could be used with existing indexes.The lookup structure inside each block
If
ALLof the 2^16 values are defined, the structure is empty and the ordinal is simply the requested docID with some modulo and multiply math. Nothing to improve there.If the block is
DENSE(2^12 to 2^16 values are defined), a bitmap is used and the number of set bits up to the wanted index (the docID modulo the block origo) are counted. That bitmap is a long[1024], meaning that worst case is to lookup and count all set bits for 1024 longs!One known solution to this is to use a [rank structure|[https://en.wikipedia.org/wiki/Succinct_data_structure]]. I [implemented it|[https://github.com/tokee/lucene-solr/blob/solr5894/solr/core/src/java/org/apache/solr/search/sparse/count/plane/RankCache.java]] for a related project and with that (), the rank-overhead for a
DENSEblock would be long[32] and would ensure a maximum of 9 lookups. It is not trivial to build the rank-structure and caching it (assuming all blocks are dense) for 6M documents would require 22 KB (3.17% overhead). It would be far better to generate the rank-structure at index time and store it immediately before the bitset (this is possible with streaming as each block is fully resolved before flushing), but of course that would require a change to the codec.If
SPARSE(< 2^12 values \~= 6%) are defined, the docIDs are simply in the form of a list. As a comment in the code suggests, a binary search through these would be faster, although that would mean seeking backwards. If that is not acceptable, I don't have any immediate idea for avoiding the full iteration.I propose implementing query-time caching of both block-jumps and inner-block lookups for
DENSE(using rank) as first improvement and an index-timeDENSE-rank structure for future improvement. As query-time caching is likely to be too costly for rapidly-changing indexes, it should probably be an opt-in in solrconfig.xml.Some real-world observations
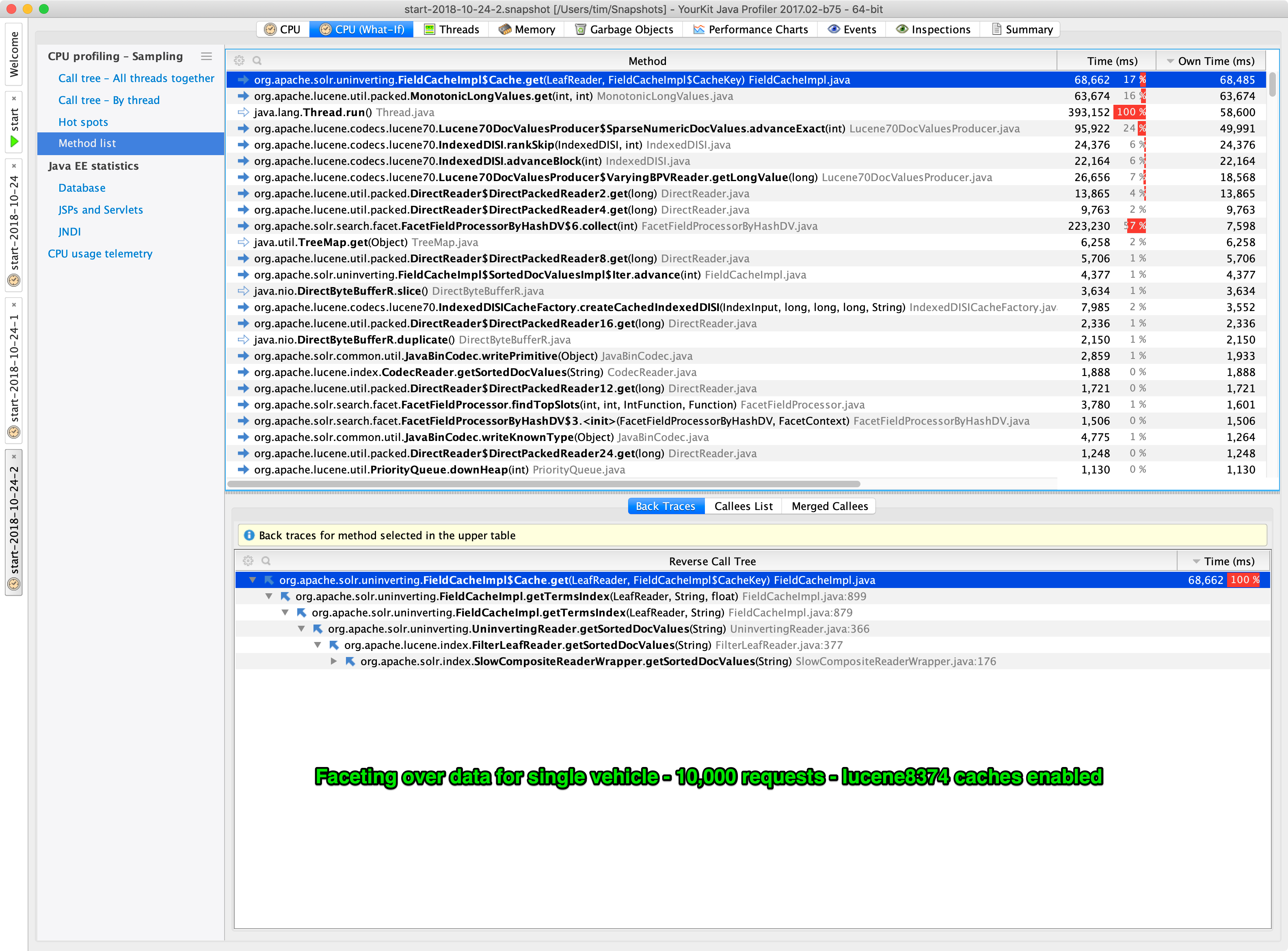
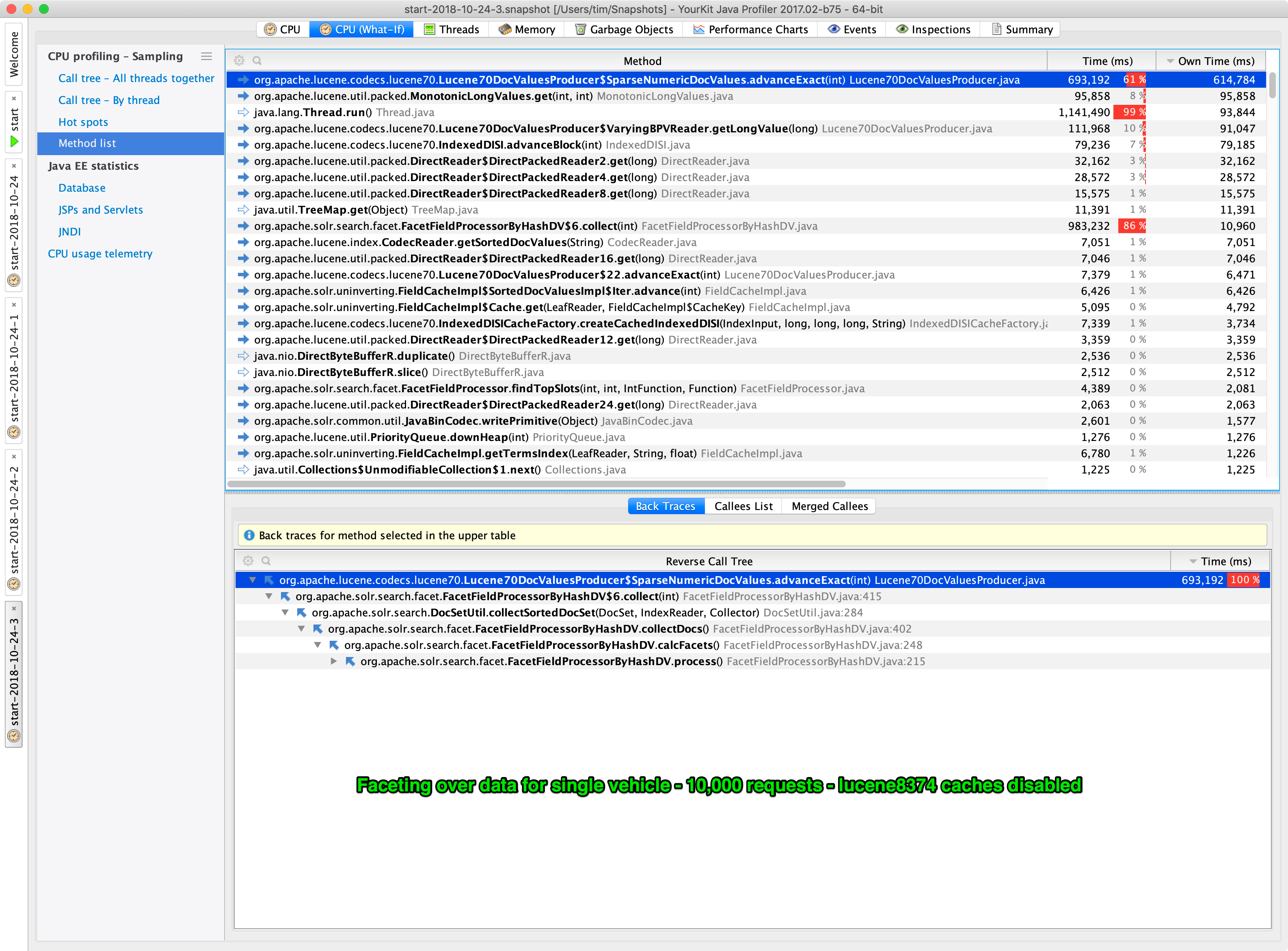
This analysis was triggered by massive (10x) slowdown problems with both simple querying and large exports from our webarchive index after upgrading from Solr 4.10 to 7.3.1. The query-matching itself takes ½-2 seconds, but returning the top-10 documents takes 5-20 seconds (\~50 non-stored DocValues fields), up from ½-2 seconds in total from Solr 4.10 (more of a mix of stored vs. DocValues, so might not be directly comparable).
Measuring with VisualVM points to
NIOFSIndexInput.readInternalas the hotspot. We ran some tests with simple queries on a single 307,171,504 document segment with different single-value DocValued fields in the fl and gotNote how both url and source_file_offset are very fast and also has a value for all documents. Contrary to this, content_type_ext is very slow and crawl_date is extremely slow and as they both have nearly all documents, I presume they are using
IndexedDISI#DENSE. last_modified is also quite slow and presumably usesIndexedDISI#SPARSE.The only mystery is crawl_year which is also present in nearly all documents, but is very fast. I have no explanation for that one yet.
I hope to take a stab at this around August 2018, but no promises.
Migrated from LUCENE-8374 by Toke Eskildsen (@tokee), 6 votes, resolved Dec 11 2018 Attachments: entire_index_logs.txt, image-2018-10-24-07-30-06-663.png, image-2018-10-24-07-30-56-962.png, LUCENE-8374_branch_7_3.patch, LUCENE-8374_branch_7_3.patch.20181005, LUCENE-8374_branch_7_4.patch, LUCENE-8374_branch_7_5.patch, LUCENE-8374_part_1.patch, LUCENE-8374_part_2.patch, LUCENE-8374_part_3.patch, LUCENE-8374_part_4.patch, LUCENE-8374.patch (versions: 7), single_vehicle_logs.txt, start-2018-10-24_snapshot_Users_tim_Snapshots-_YourKit_Java_Profiler_201702-b75-_64-bit.png, start-2018-10-24-1_snapshot_Users_tim_Snapshots-_YourKit_Java_Profiler_201702-b75-_64-bit.png Linked issues:
8640
9631