 bonotake
commented
5 years ago
bonotake
commented
5 years ago What triggers the execution of this app? Does it monitor submissions of arXiv, or does it take an author name/e-print id from the user by some UI?
Closed erickpeirson closed 5 years ago
bonotake
commented
5 years ago What triggers the execution of this app? Does it monitor submissions of arXiv, or does it take an author name/e-print id from the user by some UI?
 erickpeirson
commented
5 years ago
erickpeirson
commented
5 years ago We'll run it via uWSGI, and expose two endpoints: an HTML user interface, and a JSON API. So it's getting HTTP requests directly from either user agents or API clients. Both of those interfaces will be implemented in this app. This page has some explanations of how this comes together: https://arxiv.github.io/arxiv-arxitecture/crosscutting/services.html.
bonotake
commented
5 years ago So where should we implement for this issue? Should we implement controllers and services (and process, if we need) here, as #1 was for domain, and #11 and #12 are for routes?
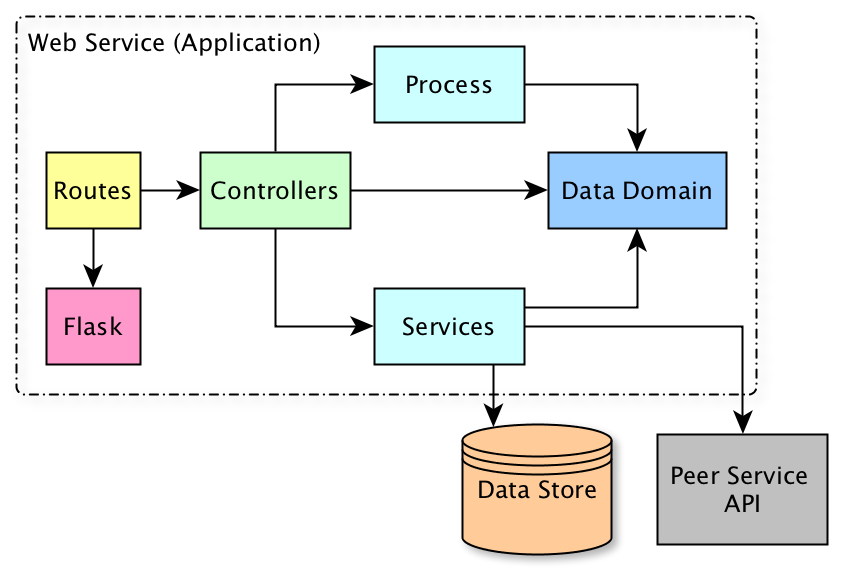
erickpeirson
commented
5 years ago Yes, that sounds right to me.
bonotake
commented
5 years ago I'll try this, anyway.
bonotake
commented
5 years ago I'm still unsure about the spec, so please let me clarify a few things:
erickpeirson
commented
5 years ago Good questions.
How does it retrieve a resource e.g., DOI from an arXiv ID? Does it send a query to other publishers' APIs with the title of the e-print as a key?
There are two different applications that work together on this.
references app that we're working on here is responsible for accepting, storing, and making available relations that are added by other apps+users. relations app is available, we'll reimplement the harvesters, and they'll add relations via the relations API.Is there a possibility that it retrieves multiple resources from one request?
From the perspective of the relations app, clients (including the harvesters) may add more than one DOI for an e-print. At this point the relations app doesn't need to discriminate among them; it should just store them all with info about who added them and when.
Similarly, the harvesters may retrieve and add (via relations API) more than one DOI per e-print.
But in either case, we're working with one relation (e.g. DOI) at a time. The harvesters work through feeds one record at a time, and make individual requests to the relations service to add new DOIs (one at a time).
bonotake
commented
5 years ago Are the retriever(s) outside the relations app, and do they put info of a resource to the app at one time?
So in #11,
POST to
/{arxiv id}/relations: create a new relation for an e-print (supports #3)
Does this method have info around a resource in its body?
erickpeirson
commented
5 years ago Are the retriever(s) outside the relations app, and do they put info of a resource to the app at one time?
Yes, that's correct.
Does this method have info around a resource in its body?
We haven't explicitly defined the content of the body, but yes: the URI, relation type, resource type etc would all be in the payload.
bonotake
commented
5 years ago @erickpeirson Now it seems OK to close this issue.
An example application is the feed collectors that monitor publisher APIs for DOIs associated with e-prints.
Another application might be a collector that pulls from ORCID.
To support this use case, we will need an HTTP route that supports POST and/or PUT requests that creates new assertions.