 aivarannamaa
commented
5 years ago
aivarannamaa
commented
5 years ago I just wanted to let you know that I intended to achieve similar goals in my Thonny IDE:
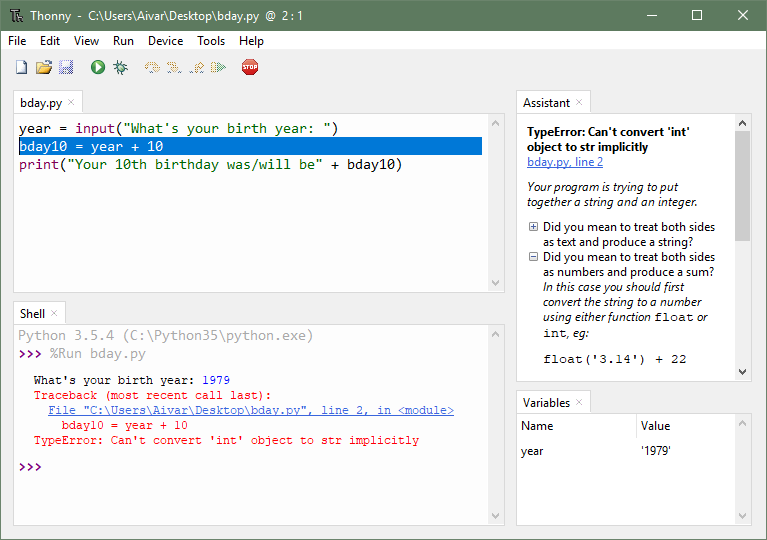
Currently the results can be considered proof-of-concept. I believe it makes sense to gather community efforts around a more general library (like friendly-traceback or pyta), which could be used by many tools.
Here are my efforts so far:
- https://files.realpython.com/media/Screenshot_2018-10-20_10.18.50.1f3845020f38.png
- https://github.com/thonny/thonny/issues/458
- https://github.com/thonny/thonny/issues/344
- https://github.com/thonny/thonny/blob/master/thonny/plugins/stdlib_error_helpers.py
Are you familiar with PyTA project?
 aroberge
aroberge ntoll
ntoll
 jharris1993
jharris1993{kind=link}
Some modules in the Python standard library have their own exceptions, such as
decimalorturtle. After the basic exceptions are included, it might make sense to include such exceptions as these modules might be used by beginners. In particular, the turtle module would like benefit from having translations.Please add your own examples from the standard library as a comment to this issue.