 aloctavodia
commented
5 years ago
aloctavodia
commented
5 years ago Hi @HectorM14 thanks for this contribution, the plot looks really nice. It will be really great if you send a PR with this new plot. Please use our existing plots as a reference, maybe pair_plot is a good place to check.
 hectormz
hectormz OriolAbril
OriolAbril






 ahartikainen
ahartikainen
I wanted a way to efficiently compare multiple marginal posteriors in PyMC3/ArviZ like in Figure 9.10 from Kruschke's book: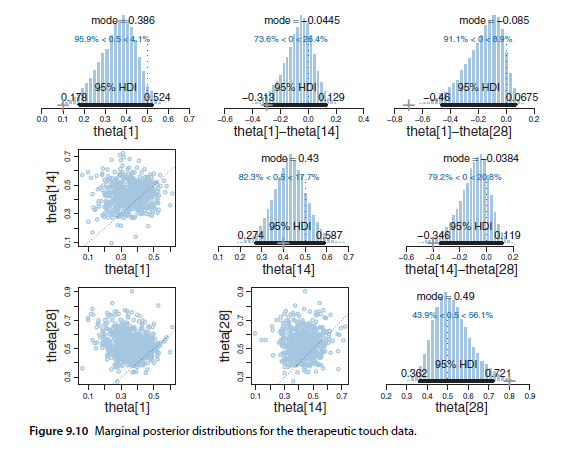
This is especially the case when using vectorized parameters in a model, and I'd like to compare many/all of them. If I have two, creating a
pm.Deterministicdifference isn't bad.I searched PyMC3/ArviZ documentation and examples, and didn't seem to find anything that fit this need. Forest plots give similar answers, but comparing HPDs of two parameters is not the same as looking at the HPD of their difference.
I created a function to plot the difference in marginal posteriors.
Here's the combined forest plot for the same trace: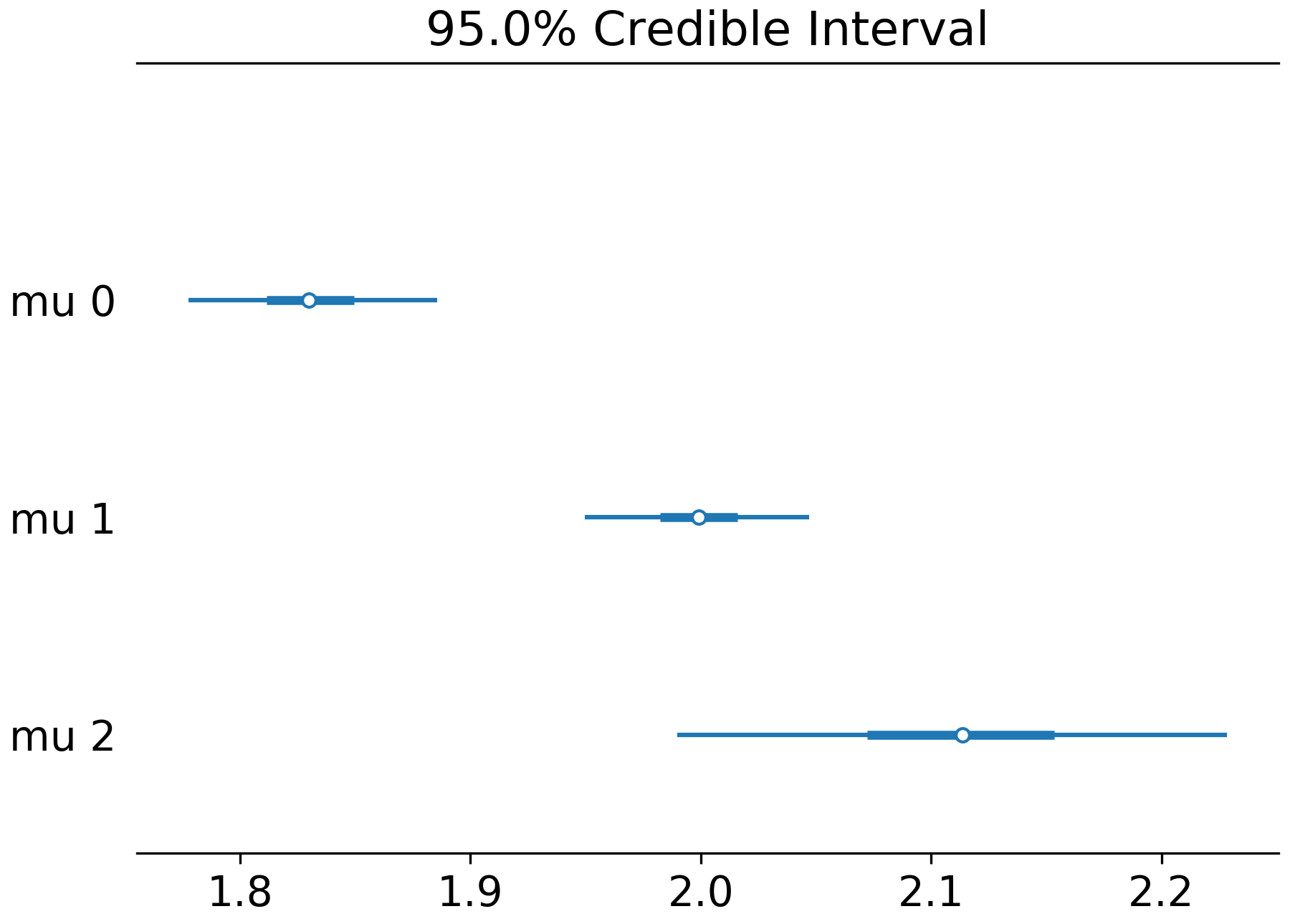
I didn't care about recreating the scatter plots, but the function could be modified to faithfully recreate the original figure: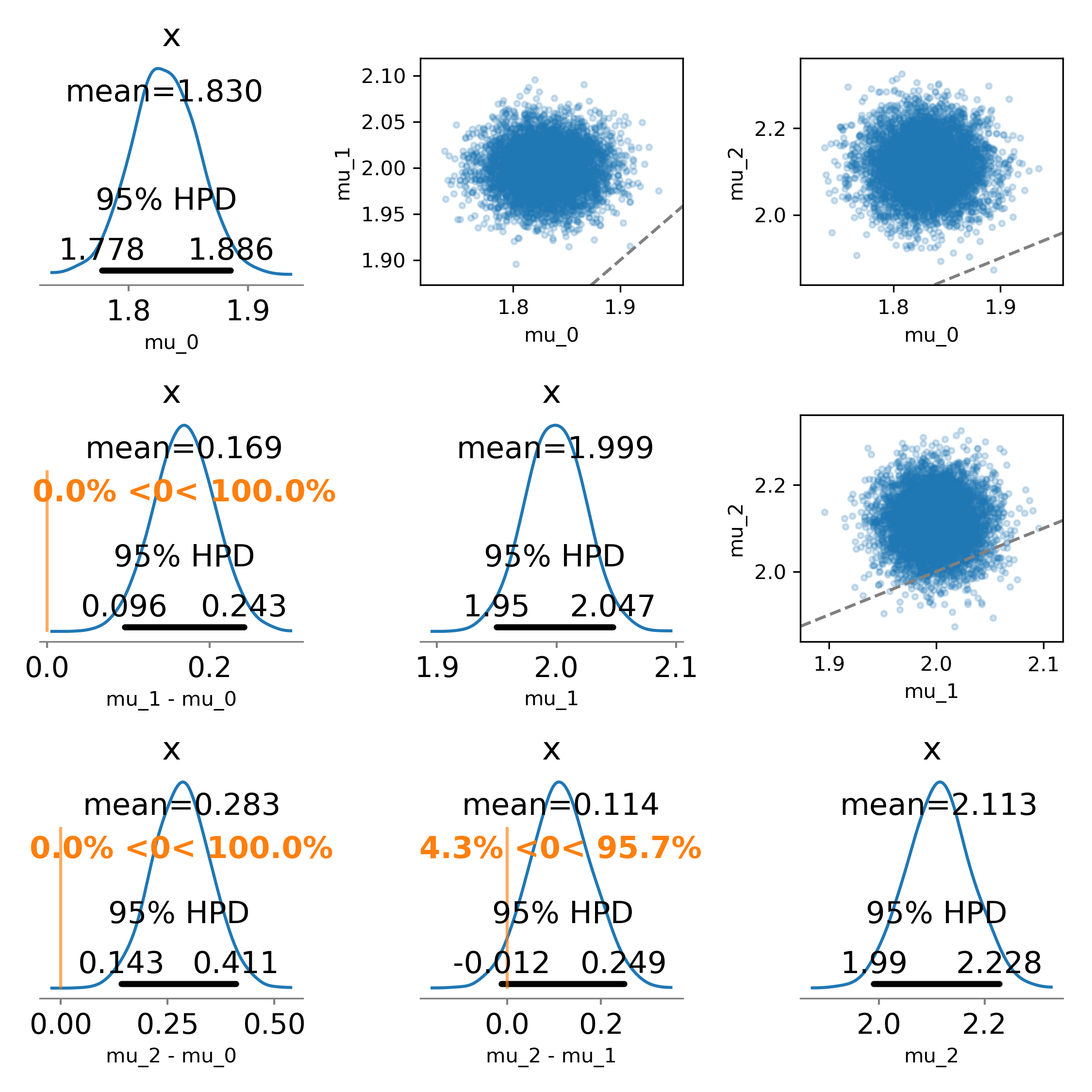
The results (and interpretations) may be different from what you'd get from a forest plot, depending on the data and parameters.
My function assumes that only one parameter would be compared at a time, and assumes that the parameter vector is a reasonable length. It's a little hackish, and assumes a PyMC3 trace for data.
Is this something worth adding to arviZ? Is there any reason that these types of plots are invalid or shouldn't be encouraged? If there's interest, I'd be willing to build this into a PR to add to arviZ (and PyMC3 plotting).