 rccoder
commented
7 years ago
rccoder
commented
7 years ago 实现上
文章中 Immutable 的实现是利用 object 的 key 构建了一棵 tire 树,然后在 update 之后针对没有修改的地方依旧指向老的 node,针对改变了的地方创建新的 node。
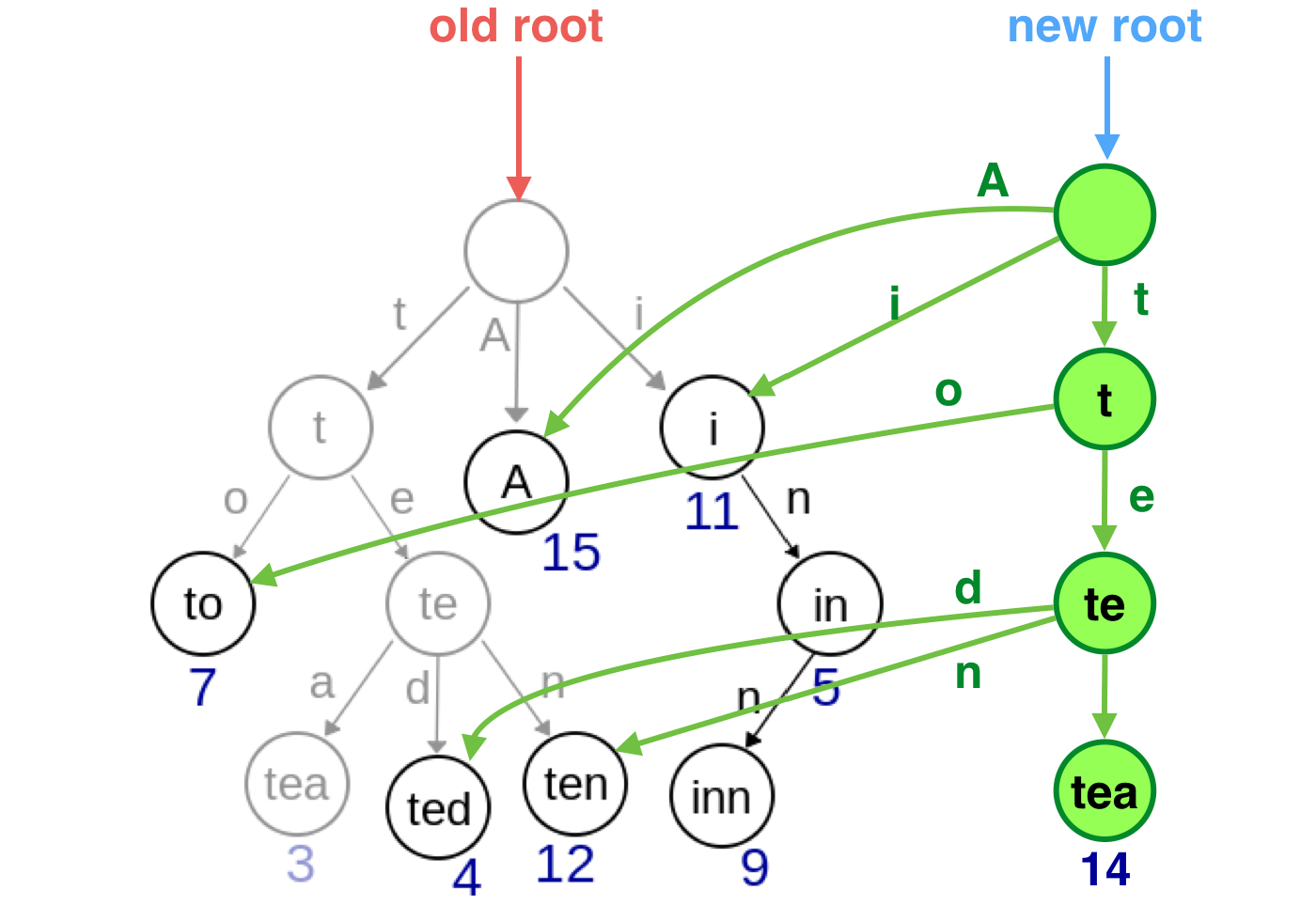
做个动画就是 camsong 之前画过的:
正是借助这种指向老节点的方式实现了 结构共享,在保持快速复制的同时保持内存占用低(有种软链接的感觉 😂)。
疑问? 如果是 tire 树的实现方式,在数据没怎么变化的情况下目测会增高内存占用?构建树本身应该需要一定的内存占用,记忆中这棵树还是比较大的。不过利用多数组 tire 树好像可以解决,目测相关库应该做了这方面的工作?
除此,如果实现一个简单的 Immutable,也可以不上 tire 树,比如: seamless-immutable
使用上
目前 Immutable 数据的更新都是借助相关库的 API 来更新,有比较强的侵入性。用了他之后我们之前熟悉的赋值,取值甚至判断相等都会发生变化。
如果在老代码中混合使用 Immutable 容易造成混淆,写出一堆乱七八糟的东西(可以想想混用 jQuery 和 浏览器原生支持的 DOM 操作混淆使用);在新代码中的话可以强制使用 Immutable。
最后期待 ES Next 支持原生的 Immutable。
 ascoders
ascoders
 cisen
cisen BlackGanglion
BlackGanglion

 jasonslyvia
jasonslyvia TingGe
TingGe twobin
twobin


 camsong
camsong
文章地址:https://medium.com/@dtinth/immutable-js-persistent-data-structures-and-structural-sharing-6d163fbd73d2 鉴于 mobx-state-tree 的发布,完美融合了 redux 与 mobx,最大的特色是使用 mutable 数据,完成 immutable 的快照,这种机制是 structural sharing,让我们先夯实基础,聊聊结构共享吧。