 adamreisnz
commented
6 years ago
adamreisnz
commented
6 years ago Thanks I'll give it a go!
Closed 50Wliu closed 6 years ago
adamreisnz
commented
6 years ago Thanks I'll give it a go!
 jeancroy
commented
6 years ago
jeancroy
commented
6 years ago Hi @50Wliu Yes this was caused by a premature speed optimization that gave incorrect result. I disabled the optimization for now. I think performance should stay similar.
I know it's not the same repo but I would like to raise awareness of https://github.com/atom/autocomplete-plus/issues/767, https://github.com/atom/autocomplete-plus/issues/465 It affect sorting quality but I'm a bit powerless because sort quality does not traverse provider boundary. And there's some kind of design decision that need to be made by the team.
adamreisnz
commented
6 years ago @50Wliu I wanted to test this today, but realised it hasn't been merged yet. Any way to quickly update only this package? I don't want to spend too much time on it, nor mess up my Atom install. If not viable, I can wait till this is merged and then re-check #21.
 50Wliu
commented
6 years ago
50Wliu
commented
6 years ago git clone https://github.com/atom/fuzzy-finder.gitcd fuzzy-findergit checkout wl-update-fuzzaldrin-plusapm installapm linkWhen you want to revert to the bundled version: apm unlink fuzzy-finder (don't forget to do this!).
adamreisnz
commented
6 years ago Awesome thanks, will give it a go.
adamreisnz
commented
6 years ago I've done those steps, but unfortunately I still see the issues in #21 presenting themselves. Is there a way to double check the correct (linked) package is being used?
 Ben3eeE
commented
6 years ago
Ben3eeE
commented
6 years ago @adamreisnz
apm install by running it againapm links to verify that the correct local clone is linked. Check if it's linked as a dev mode package which requires dev mode or not.fuzzy-finder appears as a community package (and as a core package) in the settings-viewadamreisnz
commented
6 years ago Yep, double checked everything;

The issues from #21 are still present.
50Wliu
commented
6 years ago And can you confirm that the "Use Alternate Scoring" setting is checked?
adamreisnz
commented
6 years ago Yes it is, in both packages (core/community)
50Wliu
commented
6 years ago @adamreisnz Are any of the repositories you are testing in public?
adamreisnz
commented
6 years ago No they aren't, but the issues are very easy to reproduce;
mkdir test
cd test
mkdir sub
mkdir sub/booking
touch sub/bookings.js
touch sub/booking/booking.js
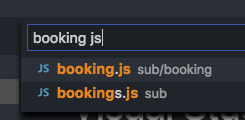
atom .Open fuzzy finder and type booking js. The result will be:

This is unexpected, the second result matches better than the first (e.g. has fewer "missing" characters in between).
VS code sorts it as expected;
It's worth nothing that some particular issues from #21 now do work correctly (even with the fuzzy finder version in Atom's master branch).
adamreisnz
commented
6 years ago This is another example of a case that is still failing;
mkdir sub/bazs
mkdir sub/booking/baz
touch sub/bazs/boo-details.js
touch sub/booking/baz/details.js
You expect the second result to appear on top, because it's a better match:

jeancroy
commented
6 years ago Thank you I'll investigate why this is happening.
Your boo-detail case is a bit complicated. There was lot of pressure to give result in filename extra importance. Also the filename is not an exact match because you enter a folder name.
adamreisnz
commented
6 years ago @jeancroy thanks for looking into it.
The second case might appear complicated, but it's not really, it's basically a case where you know in what folder your file is sitting and you have multiple files called the same way.
This is a very common situation to get in once you start to get larger apps to develop, as you'll have for example multiple different components which each might have a subcomponent with a common name like details.
So then when you want to target those files and type in the name of the component and then subcomponent, you expect the algorithm to prioritise those matches -- not something that has more different characters in the name.
In the boo/baz example, I think the problem is that Atom's fuzzy finder is trying to match the single letter b on boo, while the user typed baz. Moreover, baz already appeares in the folder name and is essentially already matched, so there is no reason for boo to be matched as well.
VS Code seems to do this well, where they don't even mark the letter b in boo, because the search term baz has already been accounted for in the folder name.
The idea being I think, that developers will know what they are searching for, and if they want baz/details.js they will type baz details, whereas if they want boo-details.js they will type boo details. So I don't think there's a valid use case where bazs/boo-details.js should be prioritzed over baz/details.js when typing baz details.
The fact that I type a folder name shouldn't demerit the use case. We're no longer encouraged to store a million files in sock drawers called routes or controllers (well, unless you're using Ember 😏 ), but instead group things together in sub folders for different components. As such, finding files by path names becomes a lot more important.
The other way of looking at it, is to see which search result has the fewest non-matching characters between the first and last match.
Going back to that example again, baz/details.js only has 2 non-matching characters, the / and the ., whereas bazs/boo-details.js has 7 non-matching characters. That makes the latter a worse match imo.
If you ignore symbols like path separators and dots, the example becomes even more clear with the first result essentially being a perfect match, and the second result having 4 non matching letters. The perfect match should "win" in this case.
There's a bunch of things that Atom does better than VS Code, but this is one example where the algorithms in VS Code make a lot more sense, so you might want to take a look at those and see how they prioritise the results.
Let me know if you need any other feedback! Keen to help you out with these issues.
jeancroy
commented
6 years ago Hi @adamreisnz, I have now updated the library based on your report.
I'll have this to say. a) I highly encourage you to use ".js" instead of " js" style of query. This enable extension aware optimizations.
b) Nevertheless there was a off-by-one bug in the handling of "multi word" query. Your "booking js" test now pass, and others like it should do better.
c) I've increased penalty for long filename. "bazs/book-details.js" now pass, while your original "bazs/boo-details.js" does not. This was done because I give precedence to real path over synthetic "foo/bar/bazz" ones. Feel free to update feedback with more realistic cases.
d) There's an online demo to play with latest version. I'll appreciate more feedback before I cut an updated version number. https://rawgit.com/jeancroy/fuzz-aldrin-plus/master/demo/demo.html
adamreisnz
commented
6 years ago @jeancroy thanks for your work on this! I'll check this tomorrow and have a look.
Note that while my example cases didn't appear realistic, they were modelled after real use cases, so their principles were the same. But I will look into it and post here if anything still looks off.
adamreisnz
commented
6 years ago I've had a play with your online demo. Here's the real-life data I used;
app/components/cards/bookings.js
app/components/booking/booking.js
app/components/booking/booking.ctrl.js
app/components/admin/settings/cards/booking.jsResults:

Looks like the case of booking js (without specifying the dot) still prioritises the bookings.js result over the booking.js one, except for the first one now because there booking is also matched in the path, so seemingly that result gets more points.
I stand by my idea that the 3rd result in the screenshot should be 2nd in the list, because it has fewer missing characters in the result, and as such is a closer match. Not sure how your algorithm prioritises bookings.js with the extra s here.
It works ok if I specify the dot though;

I think I just started using a space because I find that easier to type for a quick search. Can try to start using the dot for filenames, but I'd still recommend you to look into it some more because as mentioned VS Code's algorithm does pick up on it correctly as you can see here:

It put's the "shortest" results on top, clearly seen by the pyramid shape of results, and prioritises "file" names over "path" names.
I get the impression your search algorithm is quite generic, as indicated by the default example of movie names, but maybe it should be tailored more to file systems somehow if used inside a code editor.
This seems to be working as expected now:

This is working as expected now:

👍
adamreisnz
commented
6 years ago Another scenario that has always bothered me was the following;
app/components/admin/transaction/overview/overview.html
app/components/admin/transaction/overview/overview.jsLet's say I forgot whether I called the transaction folder singular or plural, transactions, and do a search for transactions overview.
This will yield no results, because there's one letter added that doesn't fit.
The algorithm handles missing letters reasonably well, but additional letters not at all. Not sure if there's anything that can be done about it, but thought I'd mention it.
jeancroy
commented
6 years ago I stand by my idea that the 3rd result in the screenshot should be 2nd in the list, because it has fewer missing characters in the result, and as such is a closer match. Not sure how your algorithm priorities bookings.js with the extra s here.
It put's the "shortest" results on top, clearly seen by the pyramid shape of results
Those are force that contradict each other, that's what you see here. The previous algorithm relied heavily on filename size for accuracy and thus I have collected a lot of counter examples. I'm happy to now collect counter-counter example that make again a case for shorter filename.
I've updated the weight for your 4 booking ordering.
The algorithm handles missing letters reasonably well, but additional letters not at all.
This is by design. Because every character of query must be in subject in proper order, the edit distance (and also the number of additional characters) is exactly the difference in length between both strings.
It's possible to have a more local definition of missing. Eg between the first and last character of match. But that tend to penalize someone that would like to match folder near the start of the path. (And I don't want to assume such an usage bias)
Anyways the task of computing important missing characters is a bit hard to define and expensive to compute. I chose to use those cpu cycle to assert quality of present characters instead of missing ones. In the context of autocomplete scenario. I find more useful to not apply much penalty to "not-yet-typed" candidate characters.
Things like size of filename, total path, directory depth are handled by "dumb" penalty multiplier that I try to adjust with real life path. They are however bound to interact with small match quality difference like a single "s"
jeancroy
commented
6 years ago The algorithm handles missing letters reasonably well, but additional letters not at all. Not sure if there's anything that can be done about it, but thought I'd mention it.
Oh you mean additional letter in the query. It can be done. The underlying algorithm has support for this. There's an allowError flag in the library that allow this, and some plan to do a pre-pass to count number of error that we allow (eg 1%). It's however significantly slower, and not the original spec of atom. If I have more time, I can resume my work on this and maybe have an optional checkbox. It can be much more friendly.
adamreisnz
commented
6 years ago Those are force that contradict each other, that's what you see here. The previous algorithm relied heavily on filename size for accuracy and thus I have collected a lot of counter examples. I'm happy to now collect counter-counter example that make again a case for shorter filename.
I don't think it's necessarily filename that needs to be short, but it's the number of extra characters in the results that aren't present in the search query.
For example, searching for booking js, the result booking.js has one extra character, the ., but the result bookings.js has two: s and .. As such, the first result is a better match.
This is not always the shortest filename – there might be longer filenames that are better match, for instance searching for booking js and the results some-long-booking.js (1 extra character, filename length 20), and booking-edit.js (6 extra characters, filename length 15).
Anyway, it can be argued which result should be the best match, and maybe this is a matter of preference.
We can leave it at this for now, if I see anything else coming up I'll let you know. Thanks!
jeancroy
commented
6 years ago Hi @50Wliu you may want to skip 0.5, I just published 0.6 as a result of above feedback
50Wliu
commented
6 years ago @jeancroy Thank you! @adamreisnz if you wouldn't mind testing this again, it would be much appreciated 🙇.
adamreisnz
commented
6 years ago Thanks, I'll give it a go next week or so once it lands in the latest Atom master!
Requirements
Description of the Change
Brings in updated fuzzy sorting logic.
/cc @jeancroy /cc @adamreisnz for testing. Please let me know if you need help. In addition, please tell me if you think #21 can be closed after this. Thanks!