 danabens
commented
4 years ago
danabens
commented
4 years ago What does Trial Mapping do?
"Trial Mapping", do you mean Trial Component mapping? When various jobs are created i.e. Training/Processing/Transform a Trial Component is also created with the job as the source, some data from the source job is mapped to the Trial Component for display in studio.
Tracker create chooses an identifier by adding a random sufffix to the display name, but tracker load needs exact name. If we create a tracker in the notebook when launching, what’s the best way to retrieve the trial component in the training process?
To retrieve the trial component created during the training process i.e. estimator.fit(... you would search for the trial component by the training job name.
# creates a TrainingJob
estimator.fit(
inputs={'training': inputs},
job_name=cnn_training_job_name,
experiment_config={
"TrialName": cnn_trial.trial_name,
"TrialComponentDisplayName": "Training",
},
wait=True,
)
# search for the Trial Component, alternatively list trial components filtering by trial name or source arn
search_filter = Filter(name="TrialComponentName", operator=Operator.CONTAINS, value=cnn_training_job_name)
search_expression = SearchExpression(filters=[search_filter])
# may take several seconds after training job creation and the trial component is returned from search
time.sleep(2)
results = TrialComponent.search(search_expression=search_expression, sagemaker_boto_client=sagemaker_boto_client):
trial_component_name = results["Results"][0]["TrialComponent"]["TrialComponentName"]
# load a Tracker for the trial component
tracker = Tracker.load(trial_component_name=trial_component_name)When launching a training job using the python SDK, there’s no studio support if a user doesn’t pass the experiment_config param to estimator.fit() , right?
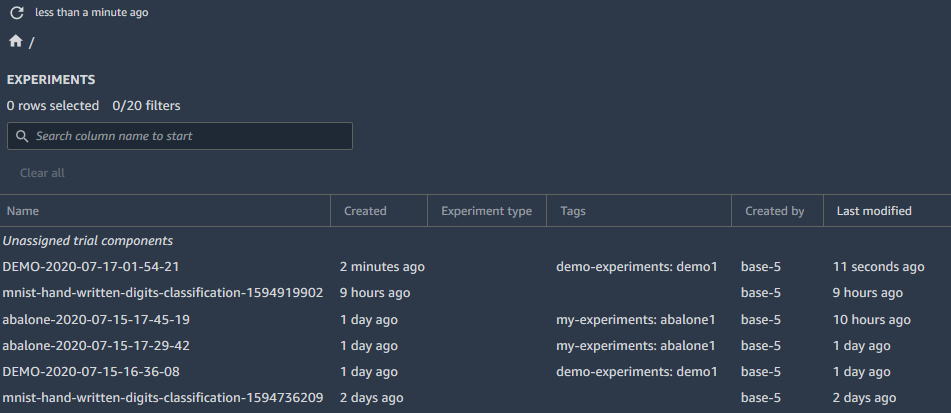
The experiment config causes the trial and experiment association to be created when the trial component is created. If the experiment config is not supplied the then trial component is still created and considered "unassigned". Unassigned trial components should still be visibile in Studio. This document mentions unassigned trial components: https://docs.aws.amazon.com/sagemaker/latest/dg/experiments.html Should look something like this: https://docs.aws.amazon.com/sagemaker/latest/dg/images/studio/studio-view-experiment-list.png
{kind=link}
What’s the best way to load the current trial from inside the training process?
If I understand correctlly, if you have the trial name you would call the DescribeTrial API to retrieve it.
Feel free to contact me internally to discuss further, answer more questions, and/or review your notebooks in more detail.
Hi, I have a few questions I want to request help on.