 ayooshkathuria
commented
6 years ago
ayooshkathuria
commented
6 years ago I'm yet to test the code on PyTorch 0.4 now. The code works in PyTorch 0.3. So, perhaps you can make a python environment with 0.3. I won't have access to a GPU till monday, so you'll have to wait before I can test it myself. I suppose this has to do with the introduction of scalars in PyTorch 0.4. However, here's how you can try to debug the code.
Look, the line objs = [classes[int(x[-1])] for x in output if int(x[0]) == im_id] fetches the class of the detection. Here are a couple of things you can do.
First, in detect.py, go to this line, objs = [classes[int(x[-1])] for x in output if int(x[0]) == im_id], and put it in a try-catch block so you can see why the exception is happening. Precisely, type.
try:
objs = [classes[int(x[-1])] for x in output if int(x[0]) == im_id]
except IndexError:
print ("Troublesome index {}".format(int(x[-1])))
assert FalseThis will stop the program with the problematic index, which is causing trouble. Ideally, it should be between 0 and 79, since this is the index the COCO class which has been detected. What you can also do is print the variable output after line 210. output is a tensor that holds information about detections. Here's a sample. Inspect what is the the last column of the output, which is what int(x[-1]) is retrieving. For example,

The last column is basically the index of your COCO class. We cast it to int so we can index it.
Do let me know what you get, and maybe we can sort it out. Or just create an environment with PyTorch 0.3 (Last time I checked, the conda and pip channels offered that) and run the code in that.
 lukasbrchl
lukasbrchl
Hi, firstly, thank you for your work on this repo. I tried to run your code, but I get this exception:
I tried to debug what is happening in the code, but it is not very clear to me. I only noticed that in my case, one tensor's size is 7 and the other is (7,1). I am also adding a screen.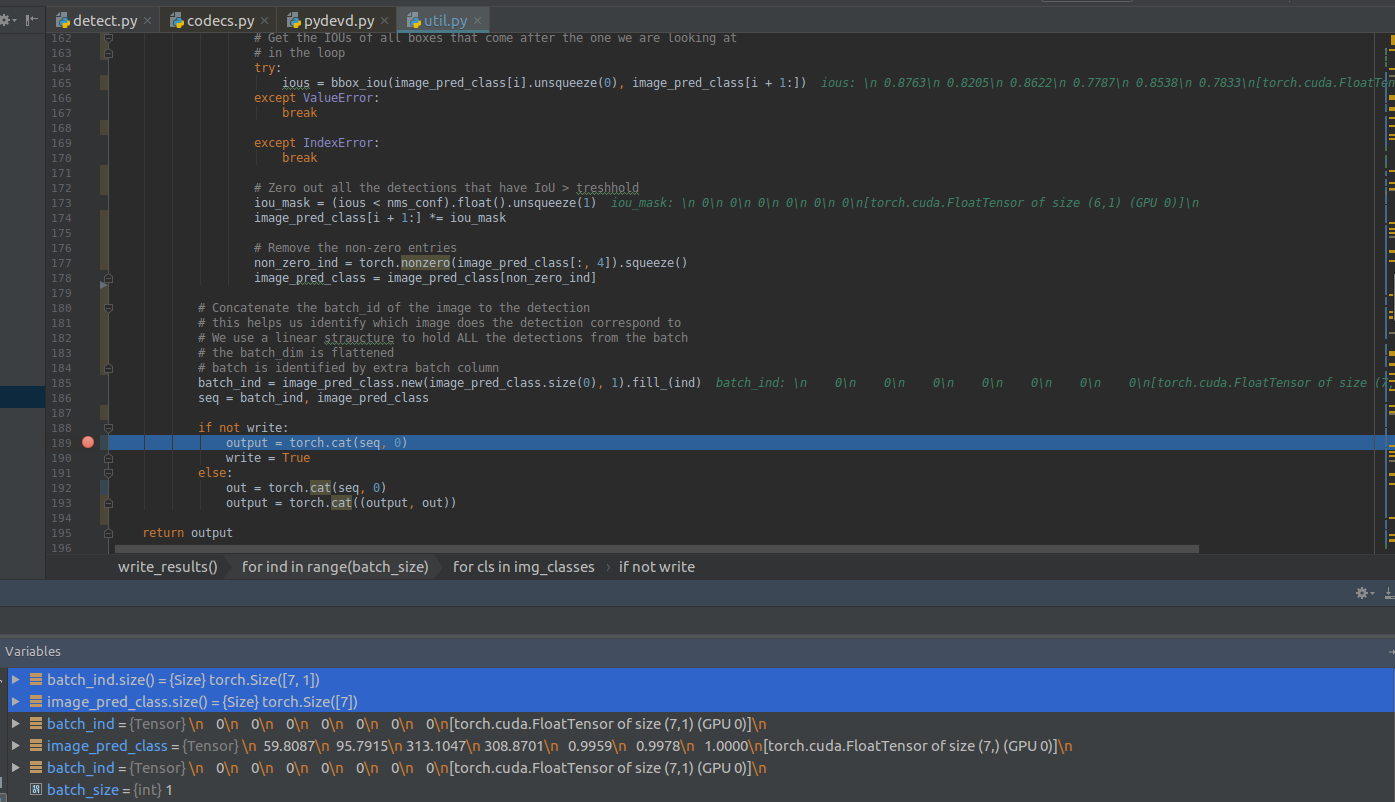
So I have modified the 7 sized tensor into (7,1) dimension but then I get another exception from further code.
Don't you please know what I am doing wrong? It is my first time working with PyTorch, so I am not very experienced and I don't know how to fix it myself.
Using Ubuntu 16.4, Python 3.6, CUDA 9.0, PyTorch 0.4. Thanks