 baixiaoji
commented
5 years ago
baixiaoji
commented
5 years ago 脑图(9h22min)




Closed baixiaoji closed 5 years ago
baixiaoji
commented
5 years ago 脑图(9h22min)
baixiaoji
commented
5 years ago 我们希望知道从在浏览器地址栏中输入 url 到页面展现的短短几秒内浏览器究竟做了什么
问题切入点
功能
架构
例子 chrome 多进程架构
Browser Process (main thread)
UI thread & network thread & storage thread 交互
文档交给 renderer process
目的
种类
流程
举例
目的
语法
需要的process
处理的组件
翻译
种类
功能
有没有工具能够生成?
例子: CSS 解析器
特例: HTML 解析器
是什么?由什么组成的?
目的?
有什么?怎么做?
特例?
心意
baixiaoji
commented
5 years ago In computing, a process is the instance of a computer program that is being executed. It contains the program code and its activity. Depending on the operating system (OS), a process may be made up of multiple threads of execution that execute instructions concurrently

因为安全性和可靠性,现代操作系统不允许独处进行之间直接通讯,采用了一种严格的通讯方法叫做 IPC (Inter-process communication)。
多任务的操作系统存在多个进程同时执行,单核CPU一次性只能执行一个进程,CPU进行切换任务,不必等待上一个任务执行结束。
通常,程序中的主程序只有单个进程和多个子进程。
In computer science, a thread of execution is the smallest sequence of programmed instructions that can be managed independently by a scheduler, which is typically a part of the operating system.[1] The implementation of threads and processes differs between operating systems, but in most cases a thread is a component of a process. Multiple threads can exist within one process, executing concurrently and sharing resources such as memory, while different processes do not share these resources. In particular, the threads of a process share its executable code and the values of its dynamically allocated variables and non-thread-local global variablesat any given time.
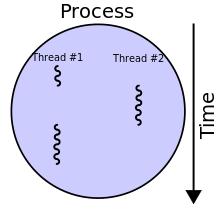
baixiaoji
commented
5 years ago 我们都知道浏览器的功能,就是向服务器发送请求,然后在浏览器窗口中展示对应请求回来的网络资源。
那一个经典的前端面试题来说:「在浏览器地址栏中输入 url 到页面展现的短短几秒内浏览器究竟做了什么?」
我的记忆点中,更多的是如何查询对应的 IP,然后发送请求到服务器,然后在渲染就结束了,不知你是不是这样?
可往往我们好像忽视了,当代浏览器那些细微的交互点,如 tab 上的 spinner 的展现。为了能慢慢的理解上述的问题,我们首先一起理一下浏览器这款软件中到底有有什么吧。
当代现有的浏览器主要由用户界面(The user interface)、浏览器引擎(The browser engine)、呈现引擎(The rendering engine)、网络(Networking)、JavasScript 解释器(JavaScript interpreter)、用户界面后端(UI backend)、数据存储组成(Data storage)。
而这些组件的功能如下:
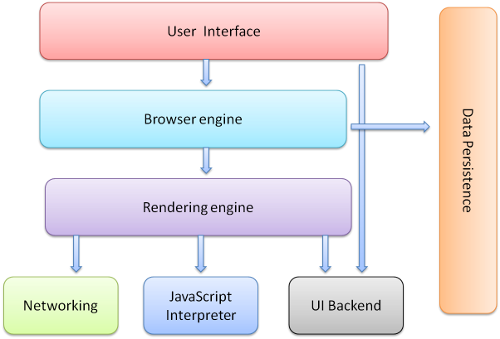
根据前置知识可知:软件是由其中进程可以运行的。那么如果想写一款浏览器的话,我们有两种实现思路,要么实现为单进程多线程模式,要么实现为多进程模式。
那我们常用的浏览器是属于哪种模式呢?
baixiaoji
commented
5 years ago 那么我们来来看看Chrome是对应的浏览器架构是怎样的呢?当我们打开任务管理器的时候,会看到看到浏览器开启会有多个进程(可以通过Chrome的更多工具 -> 任务管理器自行查看。)。
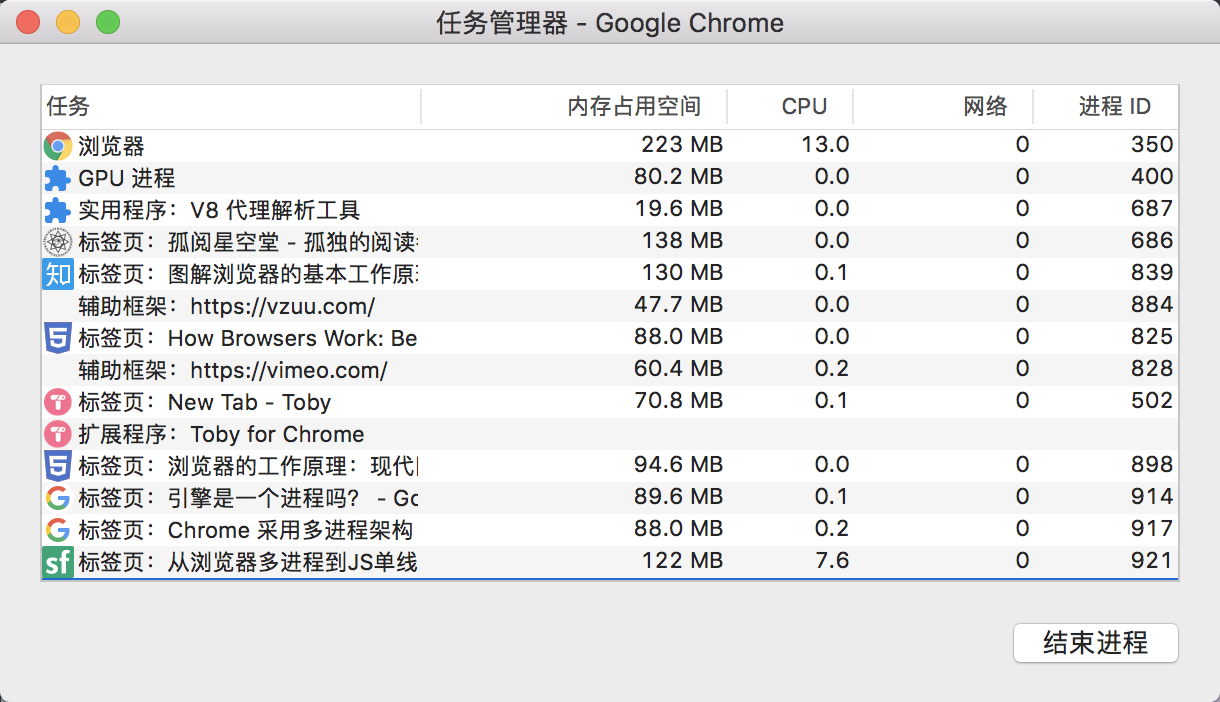
那我们来来看看chrome有哪些主要进程吧。
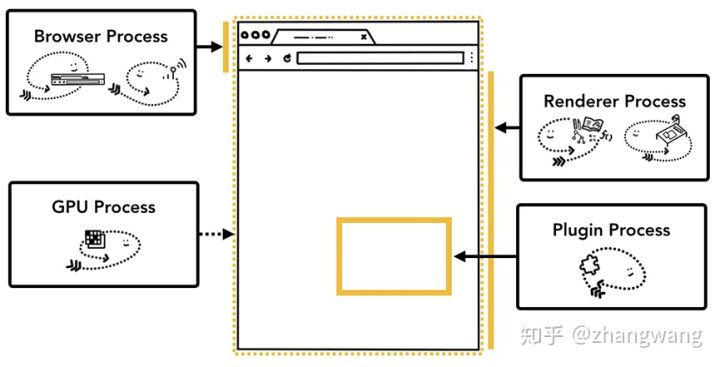
那多进程架构由那些优/劣势呢?
| 优势 | 劣势 |
|---|---|
| 单一页面的 crash 并不会影响浏览器 | 不同进程内存不能共享,导致不同进程内存中存有相同信息 |
| 插件的 crash 并不会影响浏览器 | |
| 多进程充分利用多核优势 | |
| 更为安全,在系统层面上限定了不同进程的权限 |
chrome 为了节省内存的使用,限制了最多的进程数,最大进程数量由设备的内存和 CPU 能力决定,当达到这一限制时,新打开的 Tab 会共用之前同一个站点的渲染进程。
Chrome 把浏览器不同程序的功能看做服务,这些服务可以方便的分割为不同的进程或者合并为一个进程。以 Broswer Process 为例,如果 Chrome 运行在强大的硬件上,它会分割不同的服务到不同的进程,这样 Chrome 整体的运行会更加稳定,但是如果 Chrome 运行在资源贫瘠的设备上,这些服务又会合并到同一个进程中运行,这样可以节省内存。
以上介绍完了浏览器的基本架构,但是我们最开始的问题还没开始解决呢!回顾一下问题:
「在浏览器地址栏中输入 url 到页面展现的短短几秒内浏览器究竟做了什么?」
baixiaoji
commented
5 years ago 首先回顾一下我们的问题:
「在浏览器地址栏中输入 url 到页面展现的短短几秒内浏览器究竟做了什么?」
我们根据前文的两篇文章,可以知道整个浏览器中的主进程是Browser Process,而进程中会有不同的线程,所以该进程将不同的任务交给不同的线程处理:
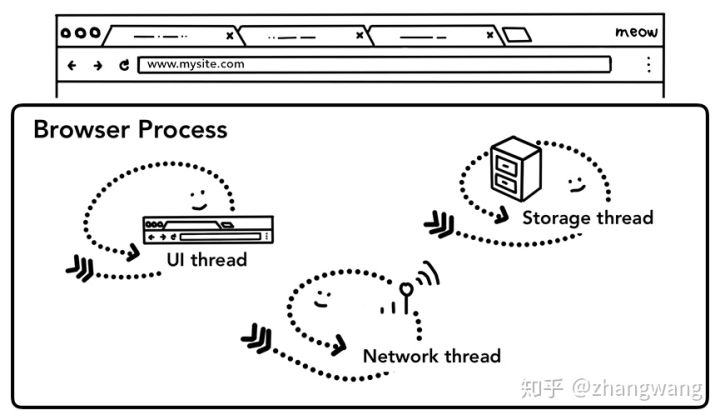
回到问题本身,这样的操作在浏览器看来可以分为以下几步:
UI thread 需要判断用户输入的是 URL 还是 query。
当用户点击回车,UI thread 通知 Network thread 获取网页内容,同时控制 tab 上的 spinner 展示(逆时针),表示正在请求页面。
Network thread 会按照顺序查询 DNS,随后为请求简历 TLS (傳輸層安全性協定:Transport Layer Security)连接。
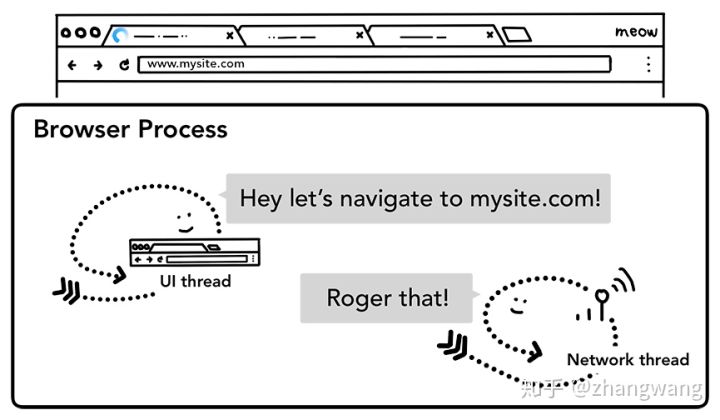
如果 Network thread 接收到了重定向的请求头如 301,Network thread 会通知 UI thread: 服务器要求重定向了,随后,另一个 URL 请求会被触发。
当请求响应回来,Network thread 会依据文档的 Content-type 及 MIME Type sniffing 判断响应内容的格式。
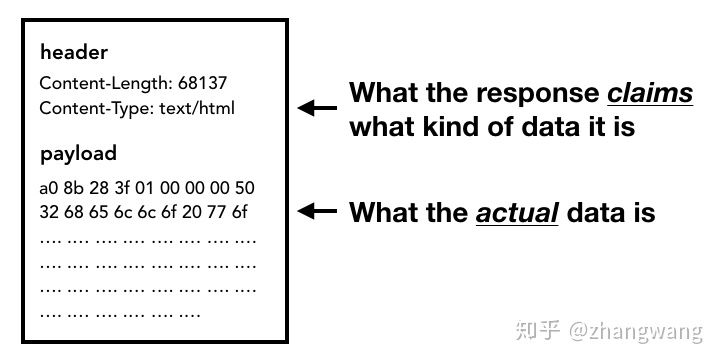
如果响应内容的格式是 HTML,下一步将会把对应的文档交给 Renderer process,如果是 zip文件或是其它文件,会把相关数据传输给下载管理器。
Safe Browsing 检查也会在此时触发,如果域名或是请求内容匹配到已知的恶意站点,Network thread 会展示一个警告页。此外 CORB 检测也会触发确保敏感数据不会被传递 Renderer process。
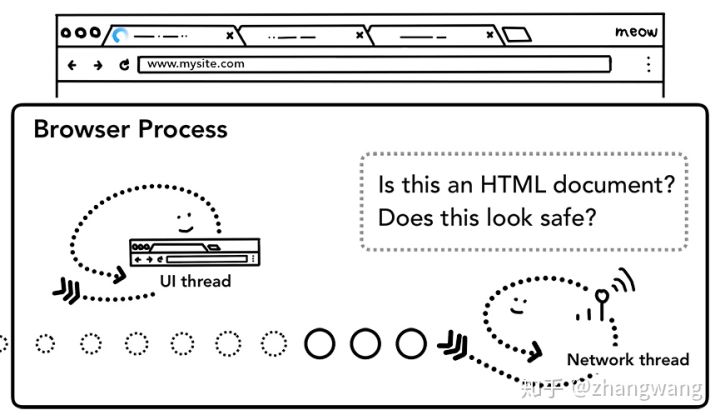
当上述检查完成,Network thread 确信浏览器可以导航到请求的网页,Network thread 会通知 UI thread 数据已经准备好了,UI thread 会查找到一个 Renderer process进行网页的渲染。
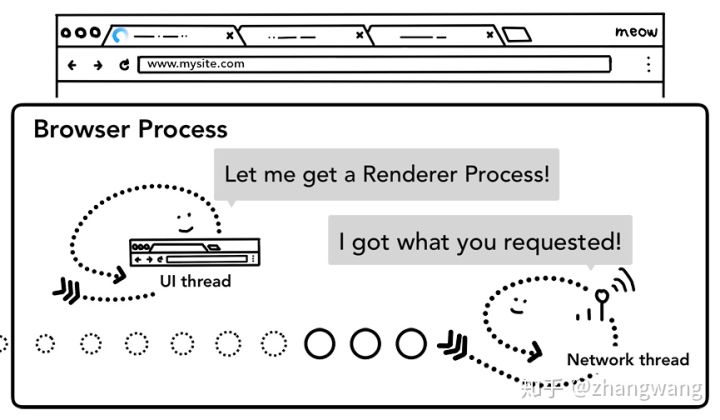
由于网络请求获取响应需要时间,这里其实还存在着一个加速方案。当 UI thread 发送 URL 请求给 network thread 时,浏览器其实已经知道了将要导航到那个站点。UI thread 会并行的预先查找和启动一个渲染进程,如果一切正常,当 network thread 接收到数据时,渲染进程已经准备就绪了,但是如果遇到重定向,准备好的渲染进程也许就不可用了,这时候就需要重启一个新的渲染进程。
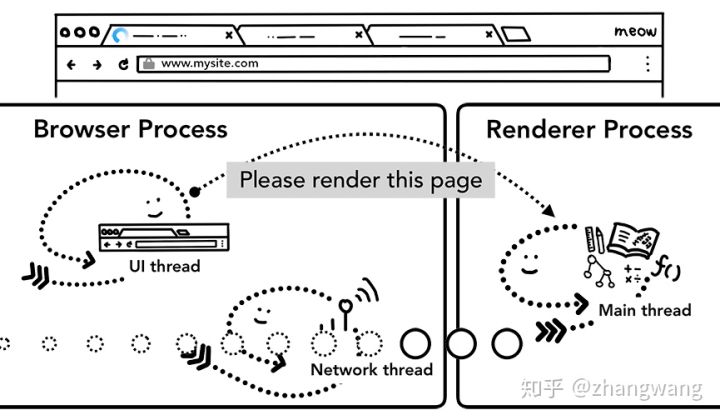
完成了上述过程,数据和渲染进行都是准备状态,Browser Process 会给 Renderer Process 发送 IPC 消息来确认导航,一旦 Browser Process 收到 renderer process 的渲染确认消息,导航过程结束,页面加载过程开始( UI thread 通知 tab 的 spinner 展示(顺时针))。
此时,地址栏会更新,展示出新页面的网页信息。history tab 会更新,可通过返回键返回导航来的页面,为了让关闭 tab 或者窗口后便于恢复,这些信息会存放在硬盘中。
导航被确认,Renderer Processs 会使用相关的资源将页面渲染出来。当 Renderer Process 渲染结束(即触发所以页面的onload事件),会发送 IPC 消息到 Browser Process,然后 UI thread 停止展示 tab 中的 spinner。
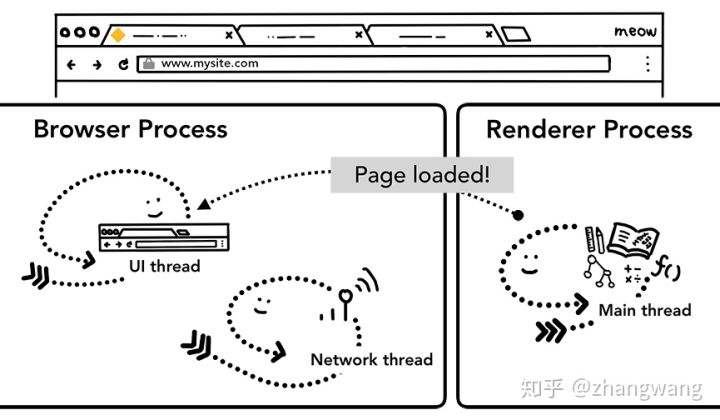
当然上面的流程只是网页首帧渲染完成,在此之后,客户端依旧可下载额外的资源渲染出新的视图。
以上就是浏览器对应我们问题的处理步骤了,是不是从以往回答更多侧重如何查询 DNS 的维度看到了自己的不足哩。
其实系列文章可以在这里结束咯,可总感觉还是将知识仅仅涉及表层(当然面试管够啦~)。所以问了自己一个问题:
Renderer Process 是如何将文档渲染出来的呢?
随便说一下:让我们前端工程师曾经头疼的不就是浏览器内核吗? (毕竟我做的第一个网站就是用 window XP系统运行的)而浏览器内核就是 Renderer Process!
baixiaoji
commented
5 years ago 前文中我们将「面试题」的解决方案已经全部交代了一遍,同时留下了一个进一步思考的问题:
Renderer Process 是如何将文档渲染出来的呢?
在介绍如何渲染的问题之前,我们还是需要了解一下什么是 Renderer Process,即浏览器内核。
浏览器内核是由各大浏览器厂商依照 W3C 标准自行研发。因为由各大厂商自主研发,必定产生不同的种类,我们先来看看市面上主流浏览器内核:
Trident:俗称 IE 内核,也被叫做 MSHTML 引擎,目前在使用的浏览器有 IE11 -,以及各种国产多核浏览器中的IE兼容模块。另外微软的 Edge 浏览器不再使用 MSHTML 引擎,而是使用类全新的引擎 EdgeHTML。
Gecko:俗称 Firefox 内核,Netscape6 开始采用的内核,后来的 Mozilla FireFox(火狐浏览器)也采用了该内核,Gecko 的特点是代码完全公开,因此,其可开发程度很高,全世界的程序员都可以为其编写代码,增加功能。因为这是个开源内核,因此受到许多人的青睐,Gecko 内核的浏览器也很多,这也是 Gecko 内核虽然年轻但市场占有率能够迅速提高的重要原因。
Presto:Opera 前内核,为啥说是前内核呢?因为 Opera12.17 以后便拥抱了 Google Chrome 的 Blink 内核,此内核就没了寄托。
Webkit:Safari 内核,也是 Chrome 内核原型,主要是 Safari 浏览器在使用的内核,也是特性上表现较好的浏览器内核。也被大量使用在移动端浏览器上。
Blink: 由 Google 和 Opera Software 开发,在Chrome(28及往后版本)、Opera(15及往后版本)和Yandex浏览器中使用。Blink 其实是 Webkit 的一个分支,添加了一些优化的新特性,例如跨进程的 iframe,将 DOM 移入 JavaScript 中来提高 JavaScript 对 DOM 的访问速度等,目前较多的移动端应用内嵌的浏览器内核也渐渐开始采用 Blink。
在浏览器架构-原理篇的部分,我们已经给出来渲染引擎相关的定义。
负责显示请求的内容。如果请求的内容是 HTML,它就负责解析 HTML 和 CSS 内容,并将解析后的内容显示在屏幕上。
从定义中得出,其主要核心作用是将请求内容显示在浏览器的窗口中。而我们知道请求内容的种类较多,但是渲染引擎默认展示是 HTML 文档、XML 文档和图片,再有插件支持的情况下方可支持其他的资源,如 pdf等类。
起先将请求的内容转化为 8Kb 的 chunks,之后开始解析 HTML 文档构建 DOM 树 ->解析样式结合DOM 树构建 render tree -> 布局(layout) -> 绘制(painting)。

render tree:每一个节点都是一个带有可视化样式和尺寸信息的矩形,节点按照正确的顺序去排列展示的。
layout:该部分目的就是计算出每一个节点的在屏幕上正确的位置。
painting:遍历 render tree,在用户界面后端(UI Backend layer)的帮助下绘制每一个节点。
整个流程是一个逐渐的过程,为了更好的用户体验,需要尽快的展示内容,所以在浏览器不会等所有的HTML解析完,才开始构建和布局 render tree,这是同步线性进行的流程。这就说明内容会在解析和展示的同时,有其余内容还在网络处理中。
因浏览器内核不同,所以在整个流程会有写不同,我们分别看看 Webkit 和 Gecko流程:
Webkit 主要流程:

Gecko 主要流程:

以上便是渲染引擎的主流程介绍,但回到主流程的第一步,「解析 HTML 为 DOM 树」,解析是一个动词,那这个动作背后的逻辑是什么呢?
baixiaoji
commented
5 years ago 其实我们很明白「解析」到底做了什么,说白了就一句话咯:「将源代码转化机器码」。难道不好奇转化这一流程中到底涉及到什么环节吗?
首先,我们展上述的那句话——「将源代码转化机器码」。
在浏览器中,大多数解析是文档,整个过程就是努力将文档转化为代码可以理解和使用的结构,对应输出的结果是对应文档结构的节点树,我们通常叫它为解析树或语法树。
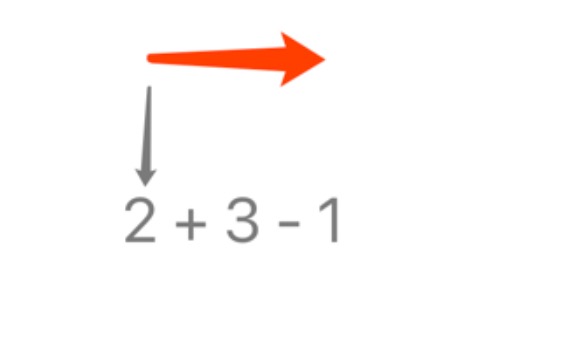
感觉理解上可能还会有点问题,我们举个例子,解析 2 + 3 -1 这个表达式,通过解析会输出这样的语法树:

整个解析过程都是基于文档的语法规则去处理的,而每种可以解析的格式都有确定的语法,又由连续的单词和语法规则组成,这样的语法我们叫做 context free grammer,而人类语言不属于此类范畴(所以不不能用常规的解析技术)。这样看来对应的解析还是比较刻板的过程,只是匹配语法然后转化的过程。
那解析过程可以分几个阶段呢?
解析过程分为两个阶段 lexical analysis 和 syntax analysis 。
lexical analysis 阶段:整个过程是将输入的文档,转化有效的 tokens。这里想将 tokens 理解为人类语言中单词。
syntax analysis阶段:该阶段就是将上阶段的产物应用语法规则,产出语法树。
上述的过程是基于对应的载体作用的分别是词法分析器(lexer)和解析器(parse)。
词法分析器:将输入文档转化为有效的标记,能识别和剔除无效的字符。
解析器:将有效的标记转化解析树。

整个解析过程是循环的,parse 会不断向 lexer 索要 token,然后尝试去寻找对应的语法规则去击中,如击中则将 token 对应的 node 节点添加到 parse tree 上;若没有击中,先保存到内部;然后继续索要 token 去击中语法,直到将所有的 token 全部与语法规则击中为止,如果没有就引发异常,这说明文档存在异常,因存在语法错误。
而解析为语法树并没有完成将源代码转化为机器码的步骤,还差最后一步就是翻译。而翻译过程也是同时解析过程进行,可以理解为下面的流程图:

详细讲一下开始的例子: 2 + 3 -1 表达式。该表达式包含整数、加号和减号。
而对应数学计算语法如下:
那解析一下表达式咯:匹配语法规则的第一个子串是 2,而根据第 5 条语法规则,这是一个项。匹配语法规则的第二个子串是 2 + 3,而根据第 3 条规则(一个项接一个运算符,然后再接一个项),这是一个表达式。下一个匹配项已经到了输入的结束。2 + 3 - 1 是一个表达式,因为我们已经知道 2 + 3 是一个项,这样就符合「一个项接一个运算符,然后再接一个项」的规则。2 + + 不与任何规则匹配,因此是无效的输入。
而在计算机中对应词汇都是有正则表示,所以上述表达式的词汇用正则表达为:
INTEGER: 0|[1-9][0-9]*
PLUS: +
MINUS: -因为大多数解析的语法符合 context free grammer ,所以采用 BNF (巴科斯范式)规则。BNF 是由约翰·巴科斯(John Backus)和彼得·诺尔(Peter Naur)首先引入的用来描述计算机语言语法的符号集。语法规则为
<符号> ::= <使用符号的表达式>上述例子可定义为:
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression上述仅仅是解析的整个理论过程,而其载体便是解析器,那解析器有哪些种类呢?
baixiaoji
commented
5 years ago 解析器根据解析语法的顺序不同可分为两类。
自上而下解析器:从语法高层结构开始出发,尝试从中找到匹配的结构。用点人话说就是解析器先匹配高级的语法部分,然后慢慢降级匹配。
还是我们上述的例子(2+3-1),解析器将 2 + 3 标记为表达式,2 + 3 - 1标记为表达式,而不是先标记为项。
自下而上解析器:又名移位归约解析器,从语法的底层规则触发,将输入内容逐步转化为语法规则,直至满足高层语法规则。
同样的例子,解析器将输入的内容,找到对应的匹配规则,将匹配的内容替换成对应的底层规则(term、operation),again again 直到输入内容的结尾(This will go on until the end of the input)。
虽说解析的过程还是比较死板的,无非就是规则的匹配,但是如果自己手写一个解析不仅要求自己对应解析过程要有这深刻理解,同时还要将第一版写好的解析器优化好整个处理流程,这样还是有些难度的,那么有一种可以仅仅需要我们输入对应语言的语法(词汇和语法规则)的工具就能生成对应解析器,这一定是一种神器吧~(注:留意手写和生成的前置条件)。
据说 webkit 渲染引擎就使用两种非常著名的解析器生成器( Flex 和 Bison )。
Flex: 并不是前端的 CSS噢。该生成器创建的就是词法分析器(lexer),对应输入就是一个包含正则表达式定义的 token 文件。
Bison:创建的自下而上的解析器(parse),其需要的输入则是使用 NBF 格式的语法规则。
因为需要使用 BNF格式去书写语法,则证明适用于 context free grammer的语言。而 webkit 中 CSS 解析器就是由 Bison 生成;而 firefox 中CSS解析器是由人工手写,其主要的逻辑是将CSS 文件转化为 StyleSheet 对象,而对象中包含对应的 CSS 规则。
那能不能 Bison 创建一个 HTML 解析器呢?没有可能,因为 HTML 语法规则并不是 context free grammer 类型,所以无法使用 BNF 格式书写语法,严格的说常规解析 CSS 和 JavaScript的解析器并不能解析 HTML文档。
HTML 格式可以由DTD (Document Type Definition) 定义,让我想起来 XML 和 HTML 很像语言层面都是标记语言,XML 也是有 DTD 和 XML Schema 定义的,而且 XML 中有一个 HTML 的变体: XHTML。那么 HTML 解析器能不能解析 HTML呢?
还是不行,为什么呢?想必 XML 而言,HTML 语法规则更加包容,容许开发者省略某些隐式添加的标记,有时还能省略一些起起始或是结束标签等等。这一方面让 HTML 流行的原因之一,同时导致了 HTML 语法较难定义,所以无法使用常规解析器去解析。
那 HTML 解析器到底是什么样子哩~
baixiaoji
commented
5 years ago 因为 HTML 语言在语法层面并有那么严格的语法规则,导致常规的解析器并不能解析HTML文档,对应的解决方案让浏览器厂商自定义 HTML 解析器。那么,让我们一起梳理一下 HTML 解析器到底是什么吧~
因为 HTML 语法是由 W3C 组织创建的规范中进行定义的,而且语法格式是由 DTD (Document Type Definition)定义的,该格式中定义了语言中允许的元素、属性和层次结构,适用一切的 SGML (Standard Gerneralized Markup Languge)族的语言。为了在发展的进程中向后兼容老版本的内容,DTD 存在两种模式,严格模式完全遵守 HTML 规范,其他模式支持老的浏览器使用的编辑。
因为 HTML 文档语法特性(包容性),以及在解析过程中存在脚本会改变 HTML 文档(如: document.write),导致无法使用自上而下或是自下而上的解析器进行解析。

解析过程前半段是词法分析,也就是标记化(tokenization),整体算法的核心就是状态机的改变(就是解析过程中有一个标识当前状态应是解析到哪一个阶段了)。

同时构建 DOM 树,也就是树构建(tree construction)过程,该过程就是我们在「解析-理论剖析」讲述的一样,将对应的标记去击中语法,然后添加到 DOM 树上。此过程中也有一个状态机去维护对应的阶段。

最后 DOM 树是 HTML 文档的映射关系和存留 HTML 元素对外的接口(如: 对JS),每一个节点是由 DOM 元素和节点属性组成。看一个例子:
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>
解析完,进入交互阶段开始解析处于 'deferred mode' (that should be executed after the document is parsed)的脚本,执行完这些脚本后,文档状态为 complete,触发 load 事件。
因为解析器是浏览器厂商的自定义,而 HTML语法特性比较特殊,所以解析器要有相关的容错机制,而这机制并不是 HTML 规范中强制规定,而是浏览器发展过程中的产品(友商之间互抄好的地方呗),但是后期的 HTML 5 规范中有部分容错机制的要求(webkit 的 HTML 解析器就有这样的注释)。
上述只是描述到 HTML 文档的解析,那脚本和样式的解析顺序呢?
因为 web 的模型式同步的原因,如果遇见内部 <script> 标签,就会中断 HTML 解析,开始执行脚本,直到脚本执行完毕,而遇到外部的脚本,解析同样中断直到请求脚本回来。这些解析模式在 HTML 4 5规范中有所描述。
毕竟突然中断 HTML 解析还是会影响页面展示的时间,那样我们需要规避不必要的因脚本而中断解析,那就是给 <script>添加 defer 属性,这是 HTML 5中给脚本标记为异步的标识,这样脚本通过不同的线程解析和执行。
当有脚本在执行的过程中,会触发「预解析」,此时是其他线程继续解析文档,找到需要请求加载的资源,加载这部分资源(并行加载,提高整体速度)。预解析只解析外部文件(外部脚本、样式或图片),此过程不修改 DOM 树。
样式方面,因为解析样式并不会影响 DOM 树,所以不需要中断文档解析。但同时存在一个问题,当脚本获取样式信息时,但此时样式并没有加载就会报错。对应的解决手段就是阻塞脚本,但不用浏览器阻塞的阶段不同,firefox是当样式加载或解析的时候,会阻塞所有的脚本;而 webkit 是当脚本去访问那些确定会被为加载样式影响到的属性时,阻塞脚本。
以上是刚刚完成了 DOM 树的构建,那我们马上进入后续阶段咯~
baixiaoji
commented
5 years ago renderer 节点刚刚创建,插入 render tree 中并没有 position 和 size 信息,而 layout 阶段就是计算元素几何信息的地方。因为浏览器采用的是流式布局,计算元素的几何信息是一次性的,而且后面元素几乎不影响前面元素的几何信息,除 table 元素例外。
每一个 renderer 都要一个 layout 方法,而整个过程是从 render 树的底层节点开始,递归的计算每一个节点的几何信息,root renderer 的位置是浏览器窗口的左上角,而对应的大小就是浏览器窗口的大小。
布局也有不同的种类:全局布局和增量布局。
全部的样式改变,影响到所有的 renderer (如 font-size)或是调整了窗口的大小(resize),会触发全局布局。而如果仅仅是 renderer 的位置改变的时候,整个解析器并不会再次渲染 renderer 大小而是去缓存中取。
而有 renderer 标记为 dirty 时,会触发增量布局,该过程是异步的。标记 dirty 是作用就是标记自身,告诉解析器说:「我需要重新layout了。」
计算完对应的布局之后,开始就是 painting 阶段,同样遍历 render tree,让每一个节点触发自身的 paint 函数,然后使用 UI infrastructure component 去绘制整个页面。每一个元素绘制的顺序是背景颜色、背景图片、边框、children、outline。而我们知道一般在后续的解析脚本中,可能会触发重绘,而绘制遵行的原则是:当样式发生变化时,浏览器会尽可能做出最小的响应。
绘制的过程有所讲究的:很早之前(chrome最开始的版本),绘制过程是将 render tree 的信息转化为窗口上的每一个像素点,这个过程叫做光栅化(rasterizing),其实叫做栅格化比较好理解。但这样仅仅绘制的是当前窗口的图像,当窗口移动的时候,才会将尚未绘制的部分进行删格化。
但现今浏览器更多采用的是 复合层(compositing)方式,而改方式其实就是将一个页面分为不同的 layer,顺便删格化这些 layer,而展示方式变为将不同的 layer 合并为一个新的画面,这样呈现给 web 动画创造了良好的基础。
通过以上这么多的流程,最后就是让你我看到了,设计师和工程师们辛苦的杰作咯~
baixiaoji
commented
5 years ago How Browsers Work: Behind the scenes of modern web browsers 浏览器的工作原理:新式网络浏览器幕后揭秘
虽说文章还是比较老的,但浏览器发展也会变成一步历史,从有记录的历史的源头去了解当初的浏览器,进而更好的理解当代的浏览器。
进程 线程 浏览器进程?线程?傻傻分不清楚! 从浏览器多进程到JS单线程,JS运行机制最全面的一次梳理
这些基础的计算机概念还是要弄不清楚的。
图解浏览器的基本工作原理 Inside look at modern web browser (part 1) Inside look at modern web browser (part 2)
知乎上这篇文章,更多就是 Inside look at modern web browser 的译文,发现这位小姐姐写文章写的蛮简炼的,所以才打算将文章篇幅写的比较少。(当然这是后续才发现的事情)
主流浏览器内核介绍(前端开发值得了解的浏览器内核历史) 浏览器「内核」都做了些什么?
这里查看更多浏览器内核的历史。
Inside look at modern web browser (part 3) Inside look at modern web browser (part 4)
当然词系列文章第四部分读的还是比较吃力的,但是第三部分彻底让我明白了什么 rasterizing 和 compositing。以及在布局和绘制中间过程的细节,蛮受用的。
baixiaoji
commented
5 years ago 整个浏览器原理系列文章正式完结了。因非科班出身,所以增加了对应的前置知识。整体的文章的思路还是不断的去问自己为什么,从而激发自己更有兴趣继续去思考下去。
这系列文章,只是用自己的语言重述了一遍 How Browsers Work: Behind the scenes of modern web browsers 文章,读着的时候发现真像论文呀,整体的严谨性和逻辑性蛮强的,读的时候发现浏览器是美的,所以即使在写第二篇文章发现网上好像也有类似的文章的时候,还是坚定的写完了整个系列。
因为工作差不多也有半年左右,发现公司会有很多分享呀,当然分享是一件好事情。但是分享的过程中,分享者会说出超多的概念或是术语去点缀自己演讲。这对像自己一样的新人而言,无疑是一种折磨吧,或是这些东西在工作多年的人脑中的已经是共识的东西吧。当然也在这么一瞬间,知识就被诅咒了。更忧伤的就是查找内部资料的时候,也并没有对应的文档沉淀下来。
而这一系列文章的核心就是去讲解超多的概念,我不清楚我到底有没有说明白,为了避免知识的诅咒发生,我会在参考文献部分将所有的文章罗列清楚,方便后续你的查看。记得有一位老头子说了这样的一句话:
Focus on concepts, not syntax.
当然「浏览器原理」作为自己的一个项目,因为明年更多会接触到 PBL 的学习方式,所以自身提早实践了一下。总共花费 14 h 15 min ,其中花了9 h 22 min 精度核心文章和周边文献,输出对应的文档结构以及方便后续回顾的脑图;从上周一开始整理文章系列,总用时4 h 53 min。原本计 30 号之前完成,也算给自己一份年终小礼物咯。
你就把该系列文章,当做对应核心文章的解读吧。其实更希望读者自己将参考文献部分文章全部读一遍,加油咯~
最后也是送一句话给自己:『你必须有耐心……直到你学会完完全全地把手放开,不再视图抓住一点自己的东西。』
这是什么东西?(明白该想project的定义)
为什么要做这个东西?(想想做这个东西的动机)
如何做这个东西?(拆解细节)
阅读: https://zhuanlan.zhihu.com/p/47407398 https://insights.thoughtworks.cn/critical-rendering-path-and-optimization-strategy/
脑图
输出
回顾(项目过程中的执行、以及心态的变化)