 adrian-wozniak
commented
3 years ago
adrian-wozniak
commented
3 years ago @jordanholt Could I ask you to take a look on that?
Closed adrian-wozniak closed 3 years ago
adrian-wozniak
commented
3 years ago @jordanholt Could I ask you to take a look on that?
adrian-wozniak
commented
3 years ago Thank you @jordanholt! Are you planing to release it as a major version update?
 jordanholt
commented
3 years ago
jordanholt
commented
3 years ago Most likely. As far as I can tell there are no breaking API changes but since the internal data structure (navigation.tree/navigation.nodes) is exposed; a major version is safer. There are certainly consumers inspecting the structure directly rather than going via the API.
This PR improves LRUD performance and stability. It consists of several changes, that are dependent on each other thus are bundled as a single PR.
Description
Application where I'm using LRUD has a quite complex LRUD navigation tree and often there's a need to move node from one parent to another.
To deal with that, I called
unregisterNodeto pick node from the old parent and thenregisterNodeto attach it to the new parent. It turned out that this operation is not efficient (especially on low-spec set-top boxes). See Screenshots for more details.Furthermore, information about currently focused node was lost, along with overrides pointing to moved node and its direct and indirect children.
To speed up the process of moving node between the parents, I created dedicated
moveNodemethod...The
moveNodemethodThe
moveNodemethod allows to change the parent of a node, updating internal LRUD state. It maintains the currently focused node and all overrides related to moved node and its children. It is possible to define newindexposition, maintain the currentindexvalue or append the node to the end of new parent's children list. Despite the givenindexvalue, new parent's children indices are kept coherent and compact.LRUD started performing better, but performance was still far from perfect. While profiling CPU usage it turned out, that the most CPU is being consumed by methods related to finding the node:
isNodeIdInPath,endsWith, etc. All methods, that relates to searching node id in the path. See Screenshots for more details.To improve that I had to change the way how LRUD internally keeps nodes and queries them...
Internal data structure for nodes
Instead of nodes tree and corresponding list of node paths (and focusable node paths), the map-like object was introduced, that keeps node id as a key and a node itself as a value, with references to its children. To better understand the new structure, please check diagram below, that shows sample tree expressed with data structures before and after refactor:
This allows getting node directly by only accessing
nodesobject properties without expensive string path calculations. Finding focusable nodes also became easier and faster. See Screenshots for comparison.Moreover, I could get rid of inefficient
SetandGetsince nodes are now accessed direct fromnodesstructure. For stability reasons, the whole code was updated anyway withchildrenproperty check, whenever suchchildrenproperty is needed for computations.Indices recalculation is optimized and extracted to dedicated
insertChildNodeandremoveChildNodeutility methods.To have possibility to check if node is on another node’s branch (old
isNodeIdInPathorisNodeInTree), new method was introduced:isSameOrParentForChild. This allows checking if given "parent node" is a child's parent node (direct or indirect) or the child node itself.For quick iterations over node's children, the
flattenNodeTreeandflattenNodemethods were introduced. Those are equivalent forgetNodesFromTreeand iterating over paths that "contains" node id.This is quite a significant change, so to make sure it's done right, I had to define appropriate types and improve tests coverage...
New TypeScript types definitions
This change might be obscure to some extent, but because this solution was very prone to error without correctly defined types, it was badly needed. Having TS compiler as a guardian of the types cannot be overestimated. Types like
NodeIdorNodeIndexmay seems to be useless as an aliases tostringornumber, but those are not juststringornumber. Those types definitions adds the meaning to thestring/number, so we know exactly what is the purpose of the parameter.To do their job right, types had to be modified as a whole. That's why enums for
DirectionsandOrientationswere introduced. Together with them,toValidOrientationandtoValidDirectionutility methods were added, to keep computations stable. Their purpose is to adjust letter casing and filter out all unsupported values. It's fine that types are defined in LRUD, but library might be used in pure JavaScript where user may not be aware of that. Such methods allow also to keep backward compatibility with orientation/direction values that are already used by developers. To make devs lives easierDirectionsandOrientationsenums are exported.It turned out, that there's maintenance issue opened for that: https://github.com/bbc/lrud/issues/49.
To define types correctly I had to update TypeScript version. This forced me to update EsLint, its modules and Jest versions as well...
Tests coverage
Before I started changing LRUD internal structures, I had to make sure that I won't break current behaviour. Thus I had to improve test coverage to cover as many branches as possible.
I added some additional tests, because not all LRUD logic were covered by the tests. Current test coverage is impressive, but sometimes methods/branches were only visited without checking the results. This could give illusory feeling that we are covered pretty nicely, whereas some wrong behaviour could not be detected by tests. One of such "discovered" behaviour was: not defined
orientation...Undefined
orientation- a powerful undocumented featureIt turned out that leaving
orientationnot defined gives a very nice side effect. It allows defining "boxes" from which focus can not "jump out". It is very useful when there's a need of dealing with modal popups with Ok/Cancel buttons that are displayed on top of page. It allows locking focus within that popup leaving the rest of LRUD navigation tree untouched. I updated appropriate documentation and added Recipe 5 - Error Modal Popup.Other related stability improvements
Few minor additional stability improvements were introduced while registering new node:
Given node configuration object is copied. Previously given node config was taken as it is and as a result, external object was modified by internal LRUD computations. This might result with unexpected behaviour when re-registering a node with "the same initial" configuration that can be stored somewhere in the application's (that uses LRUD) code.
If node configuration contains
childrenproperty, then it is ignored. If node has children, then it should be registered viaregisterTree, or their children should be registered separately with appropriateparentproperty value. Otherwise, navigation tree may become corrupted.Forced using node
idgiven as a method parameter. When registering a node, itsidneeds to be passed direct as aregisterNodemethods parameter, but might be also defined in provided node configuration object. Those ids might be different and to keep navigation tree coherent, the id provided directly is used, as it's mandatory. The same applies to nodes registered byregisterTreeandinsertTreemethods.Fixed
registerNodeandunregisterNodeto always returnthiseven when node is rejected to allow tree chain building.All
undefined/nullvalues unified toundefined.Renamed utility methods to follow the same naming convention. Removed underscore and applying camelCase notation.
Minor Readme and JS docs typo fixes.
Motivation and Context
The main motivation was to make applications using LRUD working smoothly on low-spec devices. String computations are expensive, but on modern laptops, such computation cost is almost not noticeable.
Situation is changing dramatically when app is lunched on low-spec set-top boxes. Users are experiencing app freezes because of underlying JavaScript computations.
How Has This Been Tested?
Tested by unit tests and manually in an app using LRUD library where such issue was found.
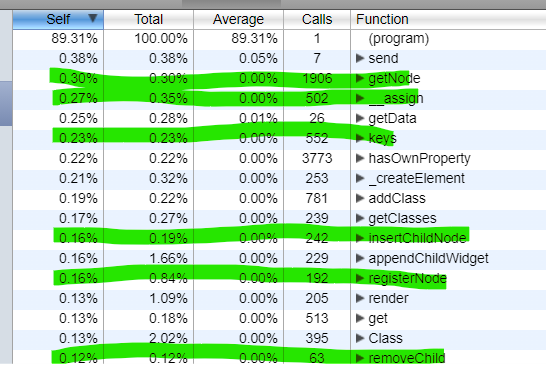
Screenshots (if appropriate):
Following screenshots shows the same CPU profiles of the same operation done on the same application state. With green LRUD's methods were highlighted. As you can see, we had over half million of operations on string.
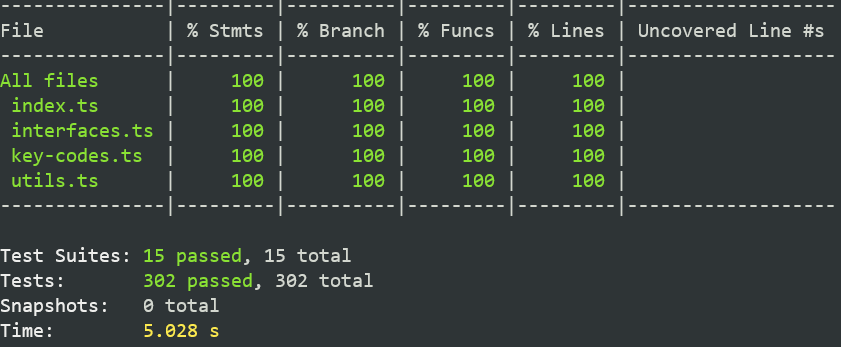
Refactor also improved tests execution time. On the following screenshots you may see, that the test execution time (average on on my PC) after refactor decreased for more than one second, where at the same time the number of tests increased.
Types of changes
Checklist: