bdy9527
commented
3 years ago
bdy9527
commented
3 years ago 感谢你指出我们代码里的问题。
首先说这个评价函数我也是用的别人的,但是我确实忘了源代码是从哪里看的了。我用的时候也没注意到这个问题,并不是我们为了效果好而刻意这么做的。
其次我们论文里所有的实验都是在y_pred和y_true是相同类别数的条件下做的实验,所以函数中 if numclass1 != numclass2 这个判断是不会触发的,也就是说我们并没有在评测过程中修改pred来得到更好的结果。
后续我会再确定一下之前的代码来源,然后修改源文件中的代码。再次感谢你的提醒。
 thirteenbird
thirteenbird mant-ux
mant-ux


在evaluation.py文件里面的评价函数eva,调用了自己写的acc/f1函数,里面存在很大的问题 代码中的acc函数如下 在两者类不匹配的时候,会去改写pred的结果,而且这是直接修改原始数据,会导致后续的nmi/ari计算使用被修改了的pred数据,使得acc/nmi/ari/f1这四个评估指标与真实存在差异
比如如下,使用sklearn.metrics提供的指标计算函数
在两者类不匹配的时候,会去改写pred的结果,而且这是直接修改原始数据,会导致后续的nmi/ari计算使用被修改了的pred数据,使得acc/nmi/ari/f1这四个评估指标与真实存在差异
比如如下,使用sklearn.metrics提供的指标计算函数
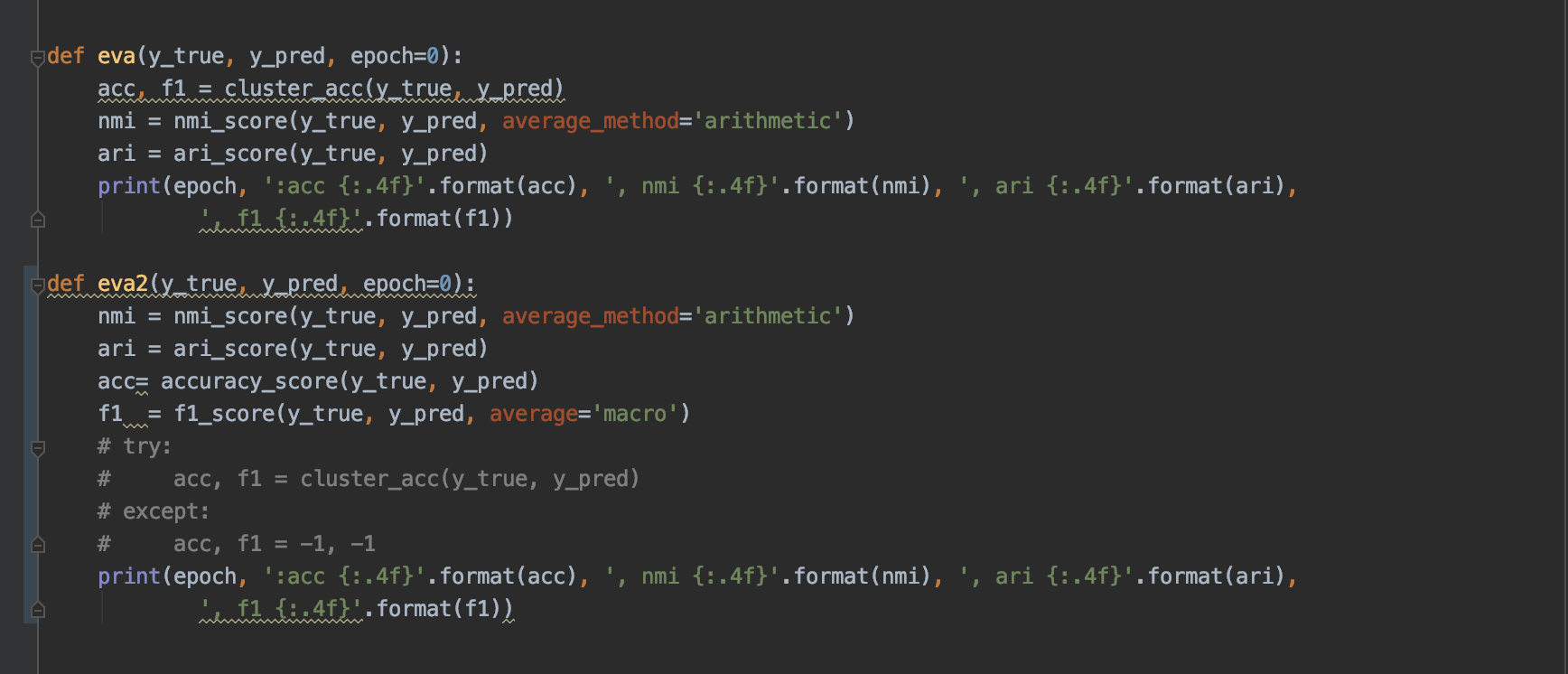 在自行构造的特殊场景下,有着很大的差别,假设存在100个点,并且类别都不一样,其原始分类为[0, ..., 100],现在假设全都预测为同一类,此时正常的eval应该是很差的,但是evaluation.py里的eva函数的数据结果却为极好
在自行构造的特殊场景下,有着很大的差别,假设存在100个点,并且类别都不一样,其原始分类为[0, ..., 100],现在假设全都预测为同一类,此时正常的eval应该是很差的,但是evaluation.py里的eva函数的数据结果却为极好