 ben-manes
commented
6 months ago
ben-manes
commented
6 months ago For the compute_samekey benchmark case, it seems ConcurrentHashMap has much less ops/s compare to the Caffeine cache.... I had ran similar case and ... ConcurrentHashMap and Caffeine has similar performance.
The Java 8 implementation of ConcurrentHashMap was pessimistic by always locking the hashbin before doing the computation. This caused a lot of contention for popular items that were present, which the same-key benchmark highlights and explains why spreading the requests improved performance by reducing lock contention. These results were discussed with Doug Lea in 2014, but unfortunately those public archives are lost so my email's archive is below.
Doug's response to these benchmarks
> On 12/18/2014 02:33 PM, Benjamin Manes wrote: > > I'm starting down the long road of writing a JDK8-based cache - effectively a > > rewrite of Guava's to resolve performance issues and the unbounded memory > > growth problem that occurs in highly concurrent usages. In the process, I > > found out that ConcurrentHashMap's computeIfAbsent is slower then it should > > be and a live-lock failure was reintroduced. > > > > > > The live-lock occurs when a recursive computation is performed for the same > > key. This is a failure that has occurred in practice, as I fixed a similar > > deadlock scenario in Guava when we were triaging bug. When feedback was asked > > for CHMv8 back in 2011, I caught the issue then and it was fixed [1]. > > The follow-up story on this (at some point briefly mentioned > in some post) is that when we moved to relying on builtin (reentrant) > bin locks without tryLock support, then only a subset of cross-bin > deadlocks/livelocks become detectable (because of reentrancy) and even > then with false-positives. So the most defensible plan is to instead > rely on general-purpose JVM tools/debuggers to help developers with this > along with any other liveness problems possible under arbitrary ifAbsent > functions. On the other hand, we didn't want to rule out all > special-case detection: If an efficient internal tryLock > intrinsic became available, we might do more, because throwing here > helps diagnose unrelated-looking problems in other threads, > and performing checks only when lock is unavailable costs almost nothing. > The main undesirable byproduct is that because the method spec > still mentions the possibility of IllegalStateExceptions, some users > expect them in cases that are not currently handled. (There is an > openJDK bug report on this (JDK-8062841) that I'm not sure what > to do about.) > > > Performance-wise, computeIfAbsent pessimistically locks instead of > > optimistically trying to return an existing entry. > > There are lots of tradeoffs. With the current implementation, > if you are implementing a cache, it may be better to code cache.get > to itself do a pre-screen, as in: > V v = map.get(key); > return (v != null) ? v : map.computeIfAbsent(key, function); > > However, the exact benefit depends on access patterns. > For example, I reran your benchmark cases (urls below) on a > 32way x86, and got throughputs (ops/sec) that are dramatically > better with pre-screen for the case of a single key, > but worse with your Zipf-distributed keys. As an intermediate > test, I measured the impact of adding a single-node prescreen > ("1cif") before locking inside CHM.computeIfAbsent, that is similar > to what was done in some pre-release versions: > > Same key > > cif: 1402559 > get+cif: 3775886700 > 1cif: 1760916148 > > Zipf-distributed keys > > cif: 1414945003 > get+cif: 882477874 > 1cif: 618668961 > > One might think (I did until running similar experiments) > that the "1cif" version would be the best compromise. > But currently it isn't. > This is in part due to interactions with biased locking, > that in some cases basically provide "free" prescreens, but > in other cases add safepoint/GC pressure in addition > to lock contention. This is all up for re-consideration though. > > -Doug > > > > > > I did this (2008) in a JCiP-style map of futures, later Guava did the same on > > its CHM fork, and even Java does this in CSLM and ConcurrentMap's default > > method. When the entry's lock is not contended the impact is minor, but hot > > entries in a cache suffer unnecessarily. The results of a JMH benchmark [3] > > below shows a 10x gain when adding this check (Caffeine). Admittedly the > > impact is minor for applications as Guava's performance is not much better, > > but that is why infrastructure projects still use ConcurrentLinkedHashMap for > > performance sensitive code even though Guava was intended to be its > > successor. > > > > > > [1] > > http://cs.oswego.edu/pipermail/concurrency-interest/2011-August/008188.html > > > > [2] > > https://github.com/ben-manes/caffeine/blob/master/src/test/java/com/github/benmanes/caffeine/cache/ComputingTest.java > > > > [3] > > https://github.com/ben-manes/caffeine/blob/master/src/jmh/java/com/github/benmanes/caffeine/cache/ComputeBenchmark.java > > > > > > > > Benchmark (computingType) Mode > > Samples Score Error Units > > > > c.g.b.c.c.ComputeBenchmark.compute_sameKey ConcurrentHashMap thrpt > > 10 17729056.323 ± 557476.404 ops/s > > > > c.g.b.c.c.ComputeBenchmark.compute_sameKey Caffeine thrpt > > 10 347007236.316 ± 24370724.293 ops/s > > > > c.g.b.c.c.ComputeBenchmark.compute_sameKey Guava thrpt > > 10 29712031.905 ± 272916.744 ops/s > > > > c.g.b.c.c.ComputeBenchmark.compute_spread ConcurrentHashMap thrpt > > 10 104565034.688 ± 4207350.038 ops/s > > > > c.g.b.c.c.ComputeBenchmark.compute_spread Caffeine thrpt > > 10 132953599.579 ± 13705263.521 ops/s > > > > c.g.b.c.c.ComputeBenchmark.compute_spread Guava thrpt > > 10 61794001.850 ± 1864056.437 ops/s > > > >This was improved in Java 9 by adding a partial pre-screen (1cif) to optimistically avoid locking if the first entry in the hashbin is for that key, else fallback to the locking behavior. This means the results can vary quite broadly, as the github action benchmark run shows a similar bottleneck on modern JDKs. Caffeine always performs a full prescreen (get+cif) which ensures reliably good performance. Since it is built on top of ConcurrentHashMap, we generally assume it has equal or slightly worse performance except in rare edge cases like this one.
I also checked you benchmark class code and wonder why you not set the maximum size when setup the ConcurrentHashMap and Caffeine cache.
There is no maximum size bounding for ConcurrentHashMap, only an initial table capacity which assists in preallocating locks. Any bounding policy would incur additional work to penalize and deviate the two cases, as Caffeine would also need to track read access patterns. That was irrelevant for this benchmark which served to highlight the lock contention problem of a computing get and its workaround, which many later experienced and were guided by. The maximum size benchmarks were shown next so none of the overhead impact of a size bounding was hidden.
For read and write benchmarks, I wonder why you didn’t include the ConcurrentHashMap as the cacheType.
That was because the benchmarks were to show the overhead of a size bounding and the performance challenge is entails. An unbounded ConcurrentHashMap demonstrates the best case, which is shown in the server benchmarks section below. The consumer laptop section was an at a glance view, and I didn't want to imply users should use unbounded caches to achieve good performance. The server benchmarks are more detailed to provide a better perspective when running on production-like hardware. And of course this snapshot of performance results could be retested with other cache types, like you did, so it was meant only to start the discussion rather than end it. These were some of the first cache concurrency benchmarks that were correct, as most across industry and research were very wrong and misleading, so it gave a valid starting point to discuss from.
 fooltuboshu
fooltuboshu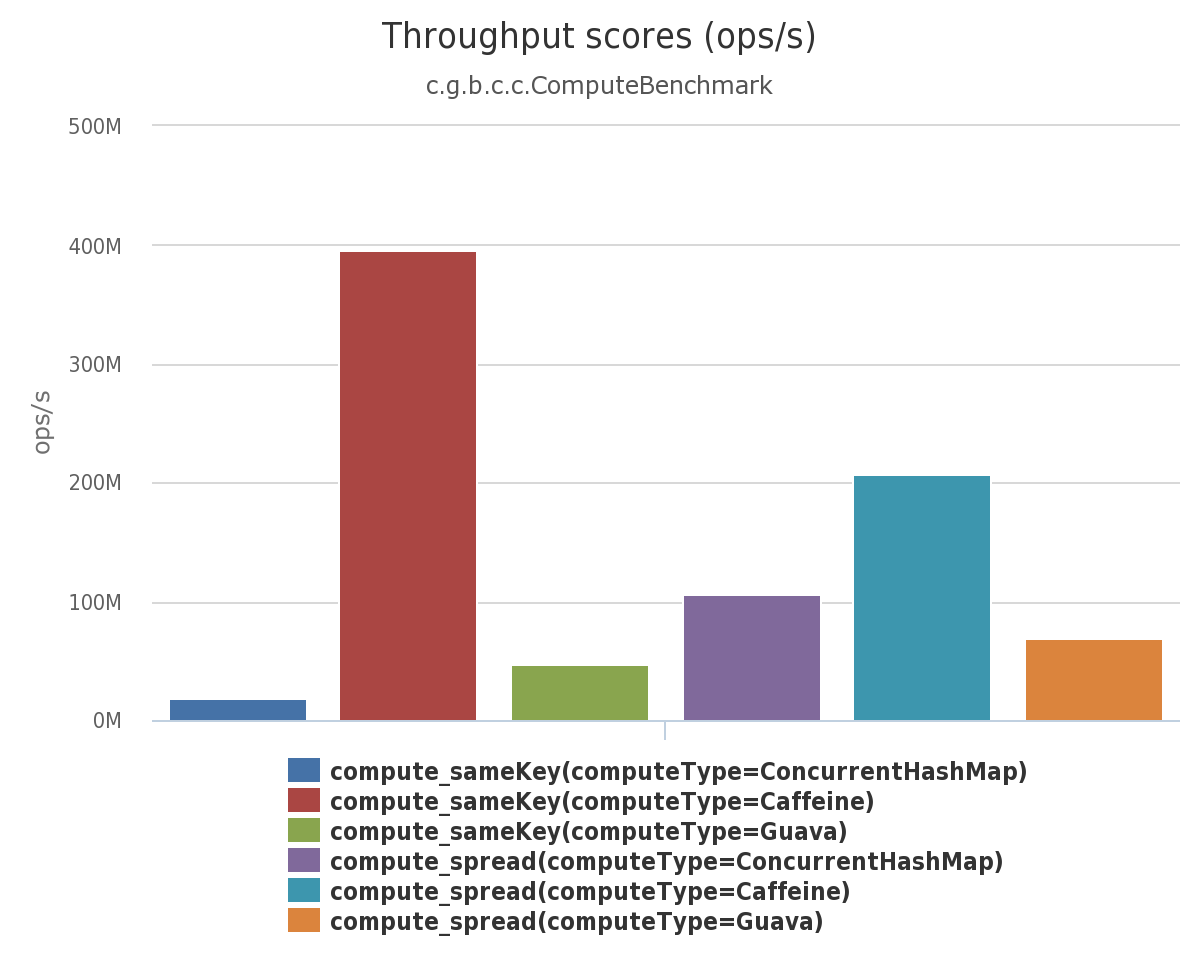{kind=link}
Hi I am reading the benchmark results https://github.com/ben-manes/caffeine/wiki/Benchmarks and have some questions around it.
cc: @HowellWang