 benbernard
commented
8 years ago
benbernard
commented
8 years ago Some additional investigation by @amling and me has yielded this:
use open (':std', ':utf8');
(also maybe use utf8;).
That first one will make the input streams be read as utf8, which should fix the ellipsis encoding issue (still need to handle new lines)
 tsibley
tsibley bokutin
bokutin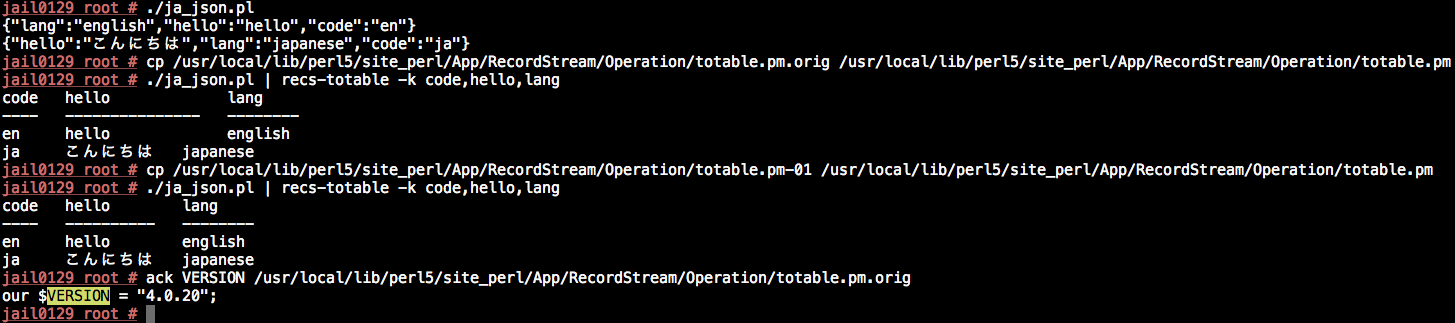

When characters like '…' and newlines are in an outputted column, the columns no longer line up. Should probably transform the output or something an also leave a --no-escape option or similar...
Probably also affects toptable. I think those are the only two that require text alignment...
copy from irc discussion: