M系列的CPU的P model设计上都保持了一致性。例如,在寄存器方面R0-R15,PSR,CONTROL和PRIMASK都保持了一样的设计。但是也有一些不同的地方,例如,两个特殊寄存器,FAULTMASK和BASEPRI只在M3/M4/M7/M33存在,floating point bank寄存器和FPSCR(Floating Point Status and Control Register)只在Cortex-M4/M7/M33上存在。
在ARM的数据处理过程中,涉及数据处理就要频繁的访问寄存器,至少有一个原寄存器和目的寄存器。数据处理的过程通常是把数据从内存中加载到寄存器组的寄存器,数据处理完毕之后,需要把数据从寄存器中回写到内存中,这种架构通常称为“load-store”架构。这种情况也提高了运算的效率,因为数据在寄存器内进行运算不需要频繁的通过总线访问内存。但也需要注意,寄存器属于CPU内部的机制,在多核的SoC中,或者有DMA的存在,多个访问者挂载共用的内存中时候,这个时候如果两个CPU都在自己的寄存器中进行运算,那么就会发生数据错误。因此,我们需要用C语言的时候增加volatile关键字,告诉编译器,这个值访问的时候需要从memory中重新load。参考Compiler optimization and the volatile keyword.md
x = __get_BASEPRI(); // Read BASEPRI register
x = __get_PRIMARK(); // Read PRIMASK register
x = __get_FAULTMASK(); // Read FAULTMASK register
__set_BASEPRI(x); // Set new value for BASEPRI
__set_PRIMASK(x);
__set_FAULTMASK(x);
// Set new value for PRIMASK
// Set new value for FAULTMASK
__disable_irq(); // Set PRIMASK, disable IRQ
__enable_irq(); // Clear PRIMASK, enable IRQ
也可以使用汇编的方式来访问:
MRS r0, BASEPRI ; Read BASEPRI register into R0
MRS r0, PRIMASK ; Read PRIMASK register into R0
MRS r0, FAULTMASK ; Read FAULTMASK register into R0
MSR BASEPRI, r0 ; Write R0 into BASEPRI register
MSR PRIMASK, r0 ; Write R0 into PRIMASK register
MSR FAULTMASK, r0 ; Write R0 into FAULTMASK register
有个简单的方法是通过Change Processor State (CPS) 指令来配置这些特殊寄存器的值为1或者0
CPSIE i ; Enable interrupt (clear PRIMASK)
CPSID i ; Disable interrupt (set PRIMASK)
CPSIE f ; Enable interrupt (clear FAULTMASK)
CPSID f ; Disable interrupt (set FAULTMASK)
Note: The FAULTMASK and BASEPRI registers are not available in ARMv6-M
(e.g., Cortex-M0).
Coprocessor Access Control Register (CPACR)用于使能或者关闭FPU:
SCB->CPACR j= 0xF << 20; // Enable full access to the FPU
在通常状况下,如果不使用浮点运算的话,可以关闭FPU,这样对功耗有好处。
LDR R0,=0xE000ED88 ; R0 set to address of CPACR
LDR R1,=0x00F00000 ; R1 = 0xF << 20
LDR R2 [R0] ; Read current value of CPACR
ORRS R2, R2, R1 ; Set bit
STR R2,[R0] ; Write back modified value to CPACR
APSR(应用状态寄存器)
应用状态寄存器包括几组状态:
Status flags for integer operations (N-Z-C-V bits)
x = __get_MSP(); // Read the value of MSP
__set_MSP(x); // Set the value of MSP
x = __get_PSP(); // Read the value of PSP
__set_PSP(x); // Set the value of PSP
MRS R0, MSP ; Read Main Stack Pointer to R0
MSR MSP, R0 ; Write R0 to Main Stack Pointer
MRS R0, PSP ; Read Process Stack Pointer to R0
MSR PSP, R0 ; Write R0 to Process Stack Pointe
函数的主体部分通常负责执行某种特殊的和特定的任务。函数的这一部分可以包含多种指令、分支(跳转)到其他函数等。典型用法如下:
mov r0, #1 /* setting up local variables (a=1). This also serves as setting up the first parameter for the function max */_mov r1, #2 /_ setting up local variables (b=2). This also serves as setting up the second parameter for the function max */_bl max /_ Calling/branching to function max */
int add(int a, int b, int c, int d, int e); // 这里的a和b是parameters
int add(int a, int b, int c, int d, int e) {
return a+b+c+d+e;
}
int main() {
int sum = add(1,2,3,4,5);
}
Caller-saved and Callee-saved registers:
R0-R3 通用寄存器用于传递参数给一个函数,同是也从这个寄存器取返回值;
R4-R8, R10 and R11 用于保存一个函数内的本地变量;
举个例子,对于上述的add函数的汇编函数为:
xxxxxxx<main>:
8000266: 2305 movs r3, #5 ;
8000268: 9300 str r3, [sp, #0] ; save arg 5 to stack
800026a: 2304 movs r3, #4 ; save arg 4 to R3
800026c: 2203 movs r2, #3 ; save arg 3 to R2
800026e: 2102 movs r1, #2 ; save arg 2 to R1
8000270: 2001 movs r0, #1 ; save arg 1 to R0
8000272: f7ff ffb1 bl 80001d8 <add> ; call to function
...
080001d8 <add>:
80001d8: b480 push {r7} ; save frame pointer
80001da: b085 sub sp, #20 ; reserve 20 bytes on stack
80001dc: af00 add r7, sp, #0 ; set new frame pointer
80001de: 60f8 str r0, [r7, #12] ; save arg 1 to stack
80001e0: 60b9 str r1, [r7, #8] ; save arg 2 to stack
80001e2: 607a str r2, [r7, #4] ; save arg 3 to stack
80001e4: 603b str r3, [r7, #0] ; save arg 4 to stack
80001e6: 68fa ldr r2, [r7, #12] ; get arg 1 from stack
80001e8: 68bb ldr r3, [r7, #8] ; get arg 2 from stack
80001ea: 441a add r2, r3 ; sum += arg 1 + arg 2
80001ec: 687b ldr r3, [r7, #4] ; get arg 3 from stack
80001ee: 441a add r2, r3 ; sum += arg 3
80001f0: 683b ldr r3, [r7, #0] ; get arg 4 from stack
80001f2: 441a add r2, r3 ; sum += arg 4
80001f4: 69bb ldr r3, [r7, #24] ; get arg 5 from stack
80001f6: 4413 add r3, r2 ; sum += arg 5
80001f8: 4618 mov r0, r3 ; save sum to r0 as return value
80001fa: 3714 adds r7, #20 ; restore frame pointer
80001fc: 46bd mov sp, r7 ; restore stack pointer
80001fe: f85d 7b04 ldr.w r7, [sp], #4 ; get saved frame pointer, pop back stack pointer
8000202: 4770 bx lr ; return
...
02_ARMv7-M_编程模型与模式
ARM有个专业术语叫做Programmer's model,可能对这个概念很陌生,也无法解释,那么我们把它视为一个词根。一个model中包含:
我们对于ARM的控制,抛开C语言,最终都转换成汇编语言,汇编是ARM的指令,指令操作需要依赖寄存器,ARM从寄存器中得知需要有什么行为,例如我们的运算,拷贝。因此编程者模型更多的是站在汇编的层面来讲故事。而我们需要关注的是,我们直接操作的寄存器,会对ARM产生什么行为。ARM设计了什么寄存器?这些寄存器的使用条件是什么?
以下编程模型来自于arm的白皮书:
M系列的CPU的P model设计上都保持了一致性。例如,在寄存器方面
R0-R15,PSR,CONTROL和PRIMASK都保持了一样的设计。但是也有一些不同的地方,例如,两个特殊寄存器,FAULTMASK和BASEPRI只在M3/M4/M7/M33存在,floating point bank寄存器和FPSCR(Floating Point Status and Control Register)只在Cortex-M4/M7/M33上存在。在ARMv7-M架构中,中断非常多,通常都有相应的优先级配置,
BASEPRI寄存器主要用于阻塞某些特定优先级或者低优先级的中断和异常。而在ARMv6-M或者ARMv8-M中,中断的优先级被限制到了4个可配置的等级中。FAULTMASK用于处理复杂的handler。非特权模式这个概念在ARMv6-M架构上是可以存在或者不存在的,而在v7-m和v8-m上是一定会有这个概念。这种差异意味着CONTROL寄存器在不同的Cortex-M处理器之间可能有微小的差异。FPU的配置选项也影响CONTROL寄存器。
CONTROL寄存器如下:
可以看出,关于M核心的执行状态问题,都是使用CONTROL寄存器来进行配置的。
PSR(Program Status Register) 在M核之间也有不同。在所有的Cortex-M中,PSR能被分为:
1. Programmer's model
1.1 Model
1.1.1 Operation Mode 与 states
M3/M4处理器有两个执行状态,相应的有两种模式。除此之外,处理器有特权和非特权访问等级。特权访问level可以访问处理器上的所有的资源,非特权访问意味着一些内存区域,或者一些指令操作不能被执行。在一些文档中,unprivilege模式还被称为“user”模式,这个术语来源于classic ARM,例如ARM7TDMI。
Operation States
执行状态分为Debug State和Thumb state。
Operation Modes
注意:在Thread mode下,软件能够在特权模式切换到非特权模式(特权->非特权)。然而,无法从非特权升级为特权模式。如果要在Thread模式下申请升权,需要用到异常机制来完成这个操作。
ARM这样设计的初衷也是为了安全考虑,基于一个基本的安全模型,系统的设计者可以利用保护机制对于特殊的敏感的内存区域加上访问限制,以开发出健壮的嵌入式系统。怎么说呢?硬件的机制其实对标的是操作系统机制,操作系统中有kernel权限和user权限的区分。例如:0x21_LinuxKernel_内核活动(一)之系统调用 。 理所当然的,用户空间是用非特权模式,内核空间使用特权模式。同时,ARM上引入MPU机制来阻止应用程序访问内核空间的数据或者外设。当发生这种访问的时候MPU会抛出异常,我们可以设定异常处理来做一些补救措施,让其ARM恢复到正常的工作状态,而不是当一个应用层级的程序访问了内核空间就让整个处理器陷入不可恢复的异常状态。这就大大的提高了健壮性和安全性。
以上是从内存引发的一些思考。除此之外,对于特权和非特权模式,还有指令层级的划分。一些指令的设定只能是在特权模式执行,这个是为什么呢?上面谈到,指令的本质是依托寄存器进行一些操作。因此,一些寄存器只能是在特权模式进行访问。例如NVIC寄存器只能是特权模式才可以访问的。
借助于特权模式和非特权模式隔离的设计思想,同样的,thread模式和handler模式也有类似的编程模式。Thread模式能够切换使用一个独立的shadowed Stack Pointer(SP)。这样就有助于把kernel的执行现场和应用的执行现场分开。怎么说?比如,low-memory是user的,high-memory是kernel的,我们当前正在执行一个应用,此时SP栈指针指向的是user空间的内存,当异常发生的时候切换到kernel也就是handler模式,我们需要把SP的栈指针地址备份到Kernel空间,然后把SP内的内容放入kernel的高内存的地址。这个过程就增大了模式切换的开销。如果SP独立化,根本不需要做这个备份,直接回归到应用的SP的位置执行就好了。
默认状态,M核处理器上电就处于特权模式,这个和ARMv8设计一致,开始则为最大可访问权限然后逐步降级,这样也是为了初始化资源方便。在一些简单的应用场景(并非需要OS调度的)就不需要去降级到非特权模式,使用普通的SP指针即可。注意M0+没有特权模式。如图所示:
还需要注意debug state。这个状态进入的点在于被debugger控制和停止了ARM处理器的运行。这个状态开放了寄存器值的外部读取和修改。
1.1.2 Registers
在M3/M4中ARM执行数据处理和控制依托于寄存器。这些寄存器组合成一个单元叫做register bank。参考[^1],register bank里面包含很多register,
在ARM的数据处理过程中,涉及数据处理就要频繁的访问寄存器,至少有一个原寄存器和目的寄存器。数据处理的过程通常是把数据从内存中加载到寄存器组的寄存器,数据处理完毕之后,需要把数据从寄存器中回写到内存中,这种架构通常称为“load-store”架构。这种情况也提高了运算的效率,因为数据在寄存器内进行运算不需要频繁的通过总线访问内存。但也需要注意,寄存器属于CPU内部的机制,在多核的SoC中,或者有DMA的存在,多个访问者挂载共用的内存中时候,这个时候如果两个CPU都在自己的寄存器中进行运算,那么就会发生数据错误。因此,我们需要用C语言的时候增加volatile关键字,告诉编译器,这个值访问的时候需要从memory中重新load。参考Compiler optimization and the volatile keyword.md
M3和M4的寄存器组有16个寄存器,他们中的13个是通用寄存器(R0-R12),剩下的是特殊寄存器(R13-R15)。
R0-R12
R0-R12寄存器是32位的通用寄存器。R0-R7也叫做low registers。由于指令集对于空间的限制,很多16-bit指令是可以访问low register的; 后8个寄存器 high register(R8-R12)能够被32-bit的指令访问和部分16-bit执行访问,例如MOV。要有一个意识,R0-R12上电之后的默认值是没有定义的(随机)。
R13-SP
R13是栈指针寄存器。栈指针寄存器主要适用于访问stack内存的,和栈指针寄存器打交道的指令也是PUSH/POP指令。07_ELF文件_堆和栈调用惯例以ARMv8为例 在 1.2 不同架构出栈和入栈 中展了A32指令的PUSH和POP在函数调用过程中的作用。
在ARM核的设定中,有两个不同的SP指针,一个是MSP(Main Stack Pointer)主要用于handler模式的栈指针,是上电后默认的指针;还有一个是Process Stack Pointer,用于thread模式。ARM选择哪个栈指针,是用过配置CONTROL寄存器进行的。
两个SP指针都是32位的。SP的最低的2个比特位总是,如果对这两个位强行写入的话总是被置为0,换句话说,SP永远是4 bytes aligned。在M处理器中,PUSH和POP指令操作的永远都是32位的,传输数据也必须是32位对齐的。
在大多数的应用场景中,如果没有嵌入式操作系统的话,没有必要使用PSP。所有的操作全部在内核空间即可。PSP使用的场景经常是需要引入OS kernel和任务分开。PSP的初始值undfined,MSP的初始值通常是reset handler的地址。
R14-link register(LR)
R14也叫做LR寄存器。这个作用就是当调用一个函数的时候存储上一个函数的返回地址。一个函数在执行结束的时候,这个函数需要返回到调用这个函数的位置,此时就是从LR寄存器读取的地址,那么在进入调用函数之前,调用那一时刻,需要记录该位置PC指针到LR寄存器。在我们C语言中,常常是函数嵌套着函数,如果多层级的函数调用,那么返回地址会被压入栈(memory)中进行记录,否则会找不到回家的路。
以上是关于一般函数的调用。特殊的,对于异常处理的返回也是使用LR寄存器,这个值并不是从栈中还原,而是从
EXC_RETURN这个寄存器自动还原。参考 04_ARMv7-M_异常处理及中断处理R15-Program Counter (PC)
R15是著名的PC寄存器(可读可写的)。注意,PC读取返回和指令地址通常都是+4(这个设计是用于兼容ARM7TDMI需求)。写入PC的值会造成一个branch Operation。
注意,因为指令必须是半字对齐(16位)或者字对齐(32位),所以在二进制数值上的数学意义体现就是PC的最低LSB为0。但是也要注意,并非是SP寄存器一样,最低两位永远是0。PC值的最低为也可以是1,例如当你使用branch/memroy read指令更新PC的时候,首先要设定PC为的LSB为1来指示ARM的状态为Thumb state。否则,就会出现一个异常错误。这个feature已经被编译器自动的隐藏掉了,但是我们要知道PC上是这样处理的。
我们来看一下ARM的流水线结构下的PC指向问题:
上图所示,在执行
add r0, r1, #5指令时,第二条指令正在译码阶段,而第三条指令正在取指阶段。在执行第一条指令时,PC寄存器应指向第三条指令。也即,当处理器为三级流水线结构时,PC寄存器总是指向随后的第三条指令。关于PC寄存器需要注意的一点是:当使用指令STR或STM对R15进行保存时,保存的可能是当前指令地址加8或当前指令地址加12。具体是加8还是加12,取决于具体的处理器设计。但是,同一个芯片只能是其中一种的方案,即只能是加8或加12中的一种。
可以通过如下的代码确定处理器采用的那种方式:
在大多数情况下,PC更新(branch和call的发生)由一些专门的指令来处理例如b之类的,换句话说,只有专门的指令才涉及到PC的更新,数据处理指令更新PC的情况很少见。但是反过来就比较常见了,例如PC的值对于访问存储在程序memory中的文字数据(const char指针,例如.ro段)很有用。因此,在arm汇编中可以看到将PC作为基地址寄存器 + 偏移量形式进行内存读取操作,偏移量则用立即数表示。
关于多线程中如何共用一个PC,需要参考操作系统的设计:02_RTOS_任务之(一)任务调度机制
1.1.3 Special Registers
除了以上寄存器在寄存器组中,这里还有很多特殊的寄存器:
从特殊寄存器中可以读或者设定处理器的状态,还有interrupt异常的masking设定。在Baremental的开发中,可能不需要来去访问寄存器,而对于嵌入式操作系统的开发,为了迎合操作系统的一些功能,就需要来去处理这些寄存器。
特殊寄存器没有被内存映射,所以使用一般的操作指令无法访问。ARM提供了专门的指令来访问特殊寄存器,MSR和MRS,这部分和ARMv8是一致的。06_ARMv8_指令集_一些重要的指令 系统访问寄存器。
ARM还给软件工程师提供了访问接口。除此之外,还需要注意有个SFP寄存器(Special Function Register)这个是特定的寄存器的名字,而这一节中提到的是一类寄存器的名字。
程序状态寄存器(Program Status Register)
包含:
这三个寄存器,如图所示:
三个寄存器可以使用组合式的方式访问,在组合模式一些文档中称为寄存器xPSR。在ARM的汇编中,访问xPSR:
这些位的意义和ARMv8一致:
也可以访问单独的PSR,正如上面列举的三个寄存器:
PRIMASK, FAULTMASK, and BASEPRI registers
PRI-MASK、FAULT-MASK和BASE-PRI寄存器主要用于异常或者中断的屏蔽。每一个异常都有一个优先级的属性。
在优先级的配置上,请注意,数值越小优先级越高,数值越大,优先级越低。这些特殊的寄存器就基于优先级用于屏蔽异常。这些寄存器只能在特权模式下才能被写入,如果在非特权模式下写入这个操作会被忽略,如果是非特权模式读的话,就会读到全0的数据。默认情况,这些特殊寄存器的值都是0,这个0值也是有意义的,这就意味着所有的中断和异常都被屏蔽掉,没有被激活。
上图是这些寄存器的编程模型,PRIMASK寄存器只有1bit宽度。当设定的时候,一键block所有的异常(除了NMI不可屏蔽中断和HardFault异常)。实际上,ARM的处理方式是把当前的中断的优先级设定为最高。
PRIMASK最常用的场景就是针对与有时间敏感度的进程,可能不想要让中断打断这个进程,因此,一键屏蔽所有的中断。在这个进程执行完毕之后,PRIMASK就要被清除掉,并且重新使能中断。
FAULTMASK寄存器和PRIMASK寄存器非常类似。但是相比于PRIMASK,这个寄存器能屏蔽HardFault异常。当需要屏蔽这个异常的时候,FAULTMASK会升当前的异常优先级为1。FAULTMASK主要用于错误处理,在ARM进入到错误处理handler的时候,在handler中需要对FAULTMASK进行配置,这样做的好处是防止在handler中继续发生错误嵌套。
例如:FAULTMASK可以绕过MPU或者镇压BUS fault。这个带来的好处就是让错误处理更容易在handler中采取一些补救措施。FAULTMASK和PRIMASK在退出上也有区别,FAULTMASK在异常返回之后可以自动的被清除。
BASEPRI寄存器提供一种颗粒度更细致的异常屏蔽。换言之,异常组或者单个异常的屏蔽都可以在BASERRI中进行配置。到底管理多少中断还要看二级厂商如何设计的。M3/M4核的ARM有8个可编程的level或者16个。
在CMSIS-Core中,提供很多函数可以控制访问这三个特殊的寄存器:
也可以使用汇编的方式来访问:
有个简单的方法是通过Change Processor State (CPS) 指令来配置这些特殊寄存器的值为1或者0
Note: The FAULTMASK and BASEPRI registers are not available in ARMv6-M (e.g., Cortex-M0).
CONTROL register
下面介绍一个非常重要的寄存器,Control寄存器(为了方便打字,后面用CTL代替)。整个ARM的运行基调都被这个寄存器控制着:
注意:CTL只能控制Thread模式,Handler模式无法控制。
CTL寄存器只能在特权模式下进行修改,但是能在非特权和特权模式下进行读。bit位按照下表表示:
在复位之后,CTL寄存器的值全都是0。这就意味着,复位状态Thread mode使用MSP作为栈指针并且Thread Mode有特权访问。在特权模式下的Thread mode,能够自由选择栈指针,也可以切换特权和非特权模式。然而,一旦nPRIV被置位,ARM把当前状态切换到非特权模式下,注意,此时就没有办法在thread模式 + 非特权的情况下切回到特权模式,因此就无法再修改CTL寄存器,只能触发handler模式,进入handler模式的时候进行修改。这种变换关系如下图所示:
程序在非特权模式的时候十分受限,没有办法自己直接切回到特权模式。这种设计也是经过深思熟虑的,考虑到一些安全的问题。例如,在嵌入式系统中可能运行一些不可信的应用程序,此时让这个应用程序运行在非特权模式,这个应用程序就被限制读取和操作一些核心的系统资源,以防止整个系统崩溃于这个应用程序。
如果这个应用程序需要访问Core级的资源,也就是在Thread模式下进行特权访问,那么这个应用程序需要异常处理机制,让其自身进入到handler模式之后,在handler中对CTL寄存器进行修改,然后再从handler中返回thread。此时应用程序就有个特权的窗口期可以访问Core级的资源。
除了需要注意模式之外,还有栈指针与运行模式的关系。nPRIV和SPSEL是正交的,也就是有四个象限,造成四个状态(其中有三个在真实的使用场景会发生)
可以通过C语言来访问CTL寄存器:
使用C语言访问CTL寄存器需要注意:
__ISB()应该被使用来确保CTL寄存器真的写入到寄存器中。检测当前的执行特权模式可以使用:
浮点寄Float point寄存器
M4有一个可选的浮点单元。浮点单元可以控制的寄存器包含:Control Register和Floating Point Status。通过这两个寄存器,我们可以使用M4的浮点单元。
M4上有S0-S31,单精度的32位浮点运算寄存器用于浮点运算的临时值驻留,这些寄存器只能被浮点指令访问。除此之外,还有D0-D31双精度的寄存器。注意,M4是不支持双精度浮点运算的,但是可以使用D0-D31寄存器作为双精度数据的传输。
FPSCR中包含丰富的控制位信息,都是用来控制浮点运算和传输的行为:
默认状态下, 浮点的运算的标准被配置为IEEE 754 单精度浮点操作。正常状态下是不需要做任何的修改的。需要注意的是在FPSCR上面,exception bits用于编程者检测浮点运算的异常。
下面是程序员使用指令访问FPU的一些方法:
Coprocessor Access Control Register (CPACR)用于使能或者关闭FPU:
在通常状况下,如果不使用浮点运算的话,可以关闭FPU,这样对功耗有好处。
APSR(应用状态寄存器)
应用状态寄存器包括几组状态:
整数状态指示
在ARMv8架构里面也有,04_ARMv8_指令集_运算指令集 里面比较指令
CMP对NCZV标志位进行比较。一些例子:
Q stauts
Q用于指示在饱和运算或饱和度调整操作期间出现饱和。ARMv7-M支持但是ARMv6-M不支持。
这个部分知道有就行了。
GE bits
Greater-Equal,被Single Instruction Multiple Data (SIMD) operations更新。
1.1.4 Stack memory
Hardware
在Cortex-M的数据存储结构中,设计了栈结构(Last-In-First-Out)来cover内存结构。对于栈结构就需要有个栈顶指针来指向栈在哪里。在M核中,使用R13来做栈指针的存储。ARMv7-M有专门的指令出栈和入栈的指令,
PUSH和POP。在使用PUSH和POP的时候,不需要关心栈寄存器是什么(MSP或者PSP)。在ELF的时候,我们整理过关于ARM的栈调用规则:07_ELF文件_堆和栈调用惯例以ARMv8为例
栈在程序运行的时候作用非常大,但是我们都是从C语言的角度,栈的作用被C语言的设计理念和机制包装。从ARM处理器的角度,栈的作用:
M处理器使用的栈模型为,“full-descending stack”,如下所示,几种典型的栈空间模型[^2]:
这种栈模型,是随着push数据,栈指针向低地址方向靠拢。
PUSH和POP最常见的使用主要是在发生函数调用的时候来存储寄存器的上下文/函数调用路线。在函数调用之前,寄存器的上下文会被PUSH指令存储到栈空间里面,在函数返回之前,会把这些值还原到原始的寄存器中。例如下图所示,一个简单的函数调用操作,主程序调用function1。此时function1需要使用和修改R4和R5和R6寄存器进行数据处理,这些寄存器在function1结束之后main函数还需要用。所以调用之前,这些值会被压入栈中,在返回之后通过POP出栈之后还原。这种方法保证了函数在调用的时候不会发生数据丢失,而且可以按照原始的路径一路路返回。需要注意的是ARM的POP和PUSH是成对出现的。有POP就应该有PUSH。
POP和PUSH可以传输多个数据,如下图所示,可以把寄存器的值写在一起。由于寄存器是32位的,所以每次传输的时候需要数据32位对齐,地址也要对齐。
对于不同类的寄存器,也可以一起PUSH和POP,比如通用寄存器和LR寄存器一起操作。
M处理器上有两个栈指针,一个是MSP和PSP。
之前在CTL一节中也提到过MSP和PSP通过SPSEL来进行切换。除此之外,对于异常之后的返回地址是放在EXC_RETURN中的。所以在这种情况下,返回地址不一定是从栈中恢复过来的,那么就要根据SPSEL来找到返回地址。
在简单的baremental应用中,是没有嵌入式系统的,thread模式和handler模式都只使用MSP。下图就是表示这种情况,unstashing的时候也是从MSP恢复的。
当有嵌入式系统的的时候,OS和User空间使用不同的内存区域。因此,PSP在Thread的时候被使用,MSP在handler的时候被使用,这个时候就需要切换栈指针寄存器。
这种栈指针分开的操作有利于保护应用程序不会crash掉系统。而且通过CTL寄存器可以一键切换,使之在系统编程上就十分的便利和快速进行SP的切换。
尽管在同一时刻只能使用MSP或PSP其中一个栈指针,但是可以直接读写MSP/PSP。在特权模式下,能够访问MSP和PSP通过CMSIS接口:
通常状况下,是不建议直接修改SP指针的。因为stack memory存储着大量的本地变量和函数调用的参数/路线。修改指针之后很可能这些数据都被miss掉了。通过指令也是可以访问的:
应用层级也不需要去担心SP的事情,这些都是OS需要cover的。
在芯片上电之后,处理器硬件自动的初始化MSP,并把vector table的首地址放入MSP中。PSP不会被自动的初始化,都是使用之前进行初始化的。
Software
在ARM基于CMSIS的软件栈中,链接器会把stack放在RAM的底部。我们以STM32F4为例子:
STM32F411RETX_FLASH.ld:复位之后,处理器把0x0地址的值加载到MSP中,因此0地址必须存储的是vector table的内容。
在startup的程序中
startup_stm32f411retx.s定义了isr_vector:_estack就在0地址,可以从linker script中找到:下图是Stack placement for Full Descending Stack:
Example
创建一个bare-metal的工程,定义内存模型。
在 linker script
STM32F411RETX_FLASH.ld, 定义 2 new 符号:_msp_stackand_psp_stack写一个简单的C程序:
调试一下这个程序,在Reset Handler的函数中打一个断点,可以看到:
下图
_estackandReset_Handlerare loaded toMSPandPCat reset从MSP切换到PSP stack,必须写一个函数来作用PSP register,并且设定CTL寄存器。
__attribute__((naked))主要为了告诉编译器这是嵌入的汇编,不要产生prologue and epilogue (序言和结语)序列。需要注意的是:
_psp_stack符号定义在linker script中;Change to Process Stack:
Application is using PSP:
When CPU sees an
SVCcall, it automatically changes to MSP Stack by settingSPtoMSP.During an exception/ interrupt handler, MSP is used.
Procedure Call Standard for Arm Architecture (AAPCS)
ARM的每一个不同架构的AAPCS都定义了参数如何传递,使用了什么寄存器,caller和callee的一些准则,除此之外,还定义了应用的ABI( application binary interface)接口。
Parameters和Arguments:
Caller-saved and Callee-saved registers:
R0-R3通用寄存器用于传递参数给一个函数,同是也从这个寄存器取返回值;R4-R8,R10andR11用于保存一个函数内的本地变量;举个例子,对于上述的add函数的汇编函数为:
如果参数超越了R0-R3,4个寄存器,就需要把参数存入栈中:
Arguments on stack during function call: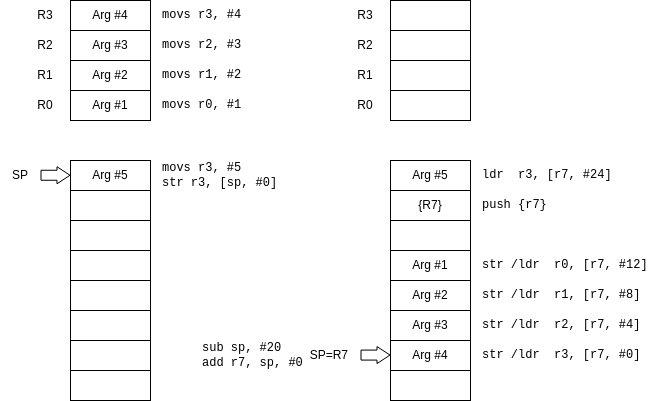
Context Saving on Stack
在AAPCS中还定义了上下文存储的规则。如果发生了中断/异常,处理器将会进行一个特殊的procesure,那就是
context saving上下文存储(保护现场)允许当前执行的程序流程和状态存储起来,当中断或者异常结束之后,再恢复。
当处理器takes an exception,除非这个异常是 tail-chained 或者 late-arriving 异常。处理器把信息会压入到当前的栈中。术语stashing。
如果使用了FPU,M4处理器自动的保存FPU的状态,在进入异常之前:
栈帧包含了返回地址。这个地址是被中断的指令的下一条指令。这个值在异常结束之后会恢复到PC。
Ref
[^1]:Chapter 2: Registers, Register Banks, Memory and Arithmetic-Logic Units [^2]:Stack Memory