 changun
commented
5 years ago
changun
commented
5 years ago Hi xuetf,
I realized that there is a bug in the dataset pre-processing step for CiteULike (see commit that fixed the bug: https://github.com/changun/CollMetric/commit/c127de45db182944e8c3062f76a05bacb46a4118 )
Unfortunately, with the bug fixed, while I still see improvement over other approaches, I were not able to achieved recall beyond 33%.
On Mon, Dec 3, 2018 at 6:46 PM xuetf notifications@github.com wrote:
Great Approach. Besides, I am wondering what parameters you use to achieve slightly better performance than the number reported in the paper. I change the learning rate to 0.00 and it achieve 29% recall in the citeulike dataset, which is lower than 33% recall reported in the paper. The parameters is as follows. Hope for your help soon.
model = CML(n_users, n_items, features=dense_features, embed_dim=200, margin=2.0, clip_norm=1.1, master_learning_rate=0.001, hidden_layer_dim=512, dropout_rate=0.3, feature_projection_scaling_factor=1, feature_l2_reg=0.1, use_rank_weight=True, use_cov_loss=True, cov_loss_weight=1 )
— You are receiving this because you are subscribed to this thread. Reply to this email directly, view it on GitHub https://github.com/changun/CollMetric/issues/15, or mute the thread https://github.com/notifications/unsubscribe-auth/AA1Ff5qRJNGyHgMwDZAVho_dxla-8rIEks5u1eIcgaJpZM4Y_z8w .
-- Cheng-Kang (Andy) Hsieh UCLA Computer Science Ph.D. Student M: (310) 990-4297
 xuetf
xuetf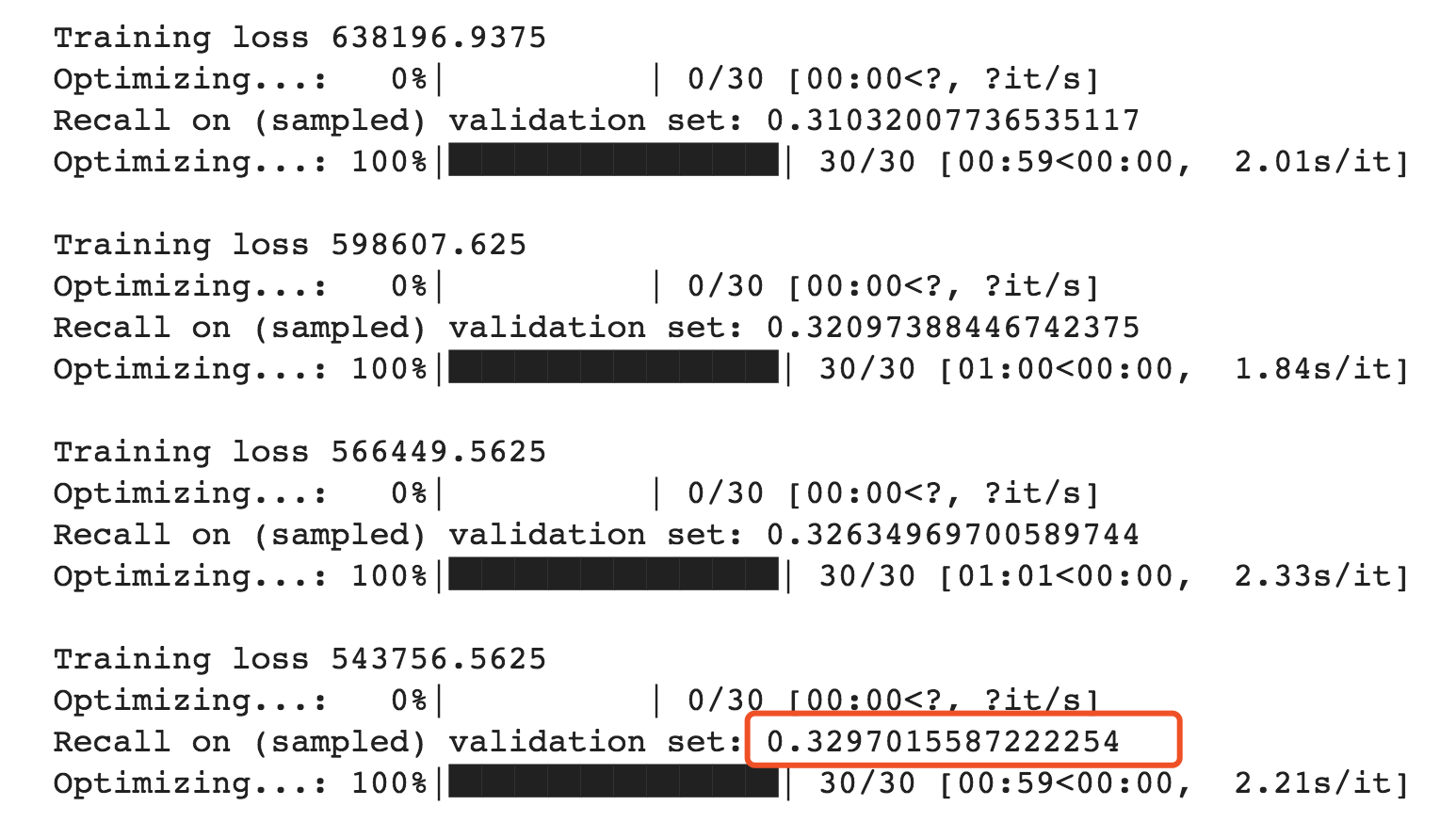 Thank you very much!
Thank you very much!
Great Approach. Besides, I am wondering what parameters you use to achieve slightly better performance than the number reported in the paper. I change the learning rate to 0.001 and it achieve 29% recall in the citeulike dataset, which is lower than 33% recall reported in the paper. The parameters is as follows. Hope for your help soon.
model = CML(n_users, n_items, features=dense_features, embed_dim=100, margin=2.0, clip_norm=1.1, master_learning_rate=0.001, hidden_layer_dim=512, dropout_rate=0.3, feature_projection_scaling_factor=1, feature_l2_reg=0.1, use_rank_weight=True, use_cov_loss=True, cov_loss_weight=1 )