 zc12345
commented
1 year ago
zc12345
commented
1 year ago Google Pathways系列模型
- T5
- 1910.10683
- 不是pathway系列,对标的是GPT-2
- Text-To-Text Transfer Transformer (T5),将NLP的范式统一为text2text的transfer learning,使用的是类BERT的encoder-decoder结构
- 使用的数据集是Colossal Clean Crawled Corpus (C4)
- PaLM
- 2204.02311
- Pathways Language Model (PaLM)
- Scaling to 540 Billion Parameters for Breakthrough Performance
- 对标GPT-3,使用Pathways系统训练
- PaLI
- 2209.06794
- PaLI: A Jointly-Scaled Multilingual Language-Image Model
- 最大模型17B(ViT-e@4B+Transformer@13B)
- 使用了100+种语言的text-image数据集WebLI
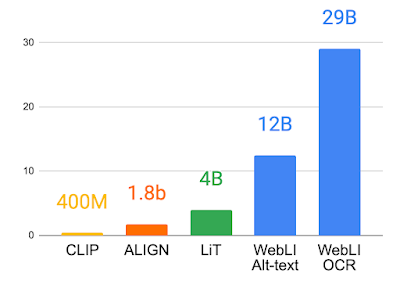
- 对标多语言版本的CLIP
- Parti
- 2206.10789
- Pathways Autoregressive Text-to-Image model(Parti)
- 对标DALL-E,用Autoregressive的方式做text2img
Pathways Autoregressive Text-to-Image model (Parti)
Method
inspiration
contribution
limitations
思考