 rapiz1
commented
4 years ago
rapiz1
commented
4 years ago As far as I am considered, it will be convenient if we can have this procedure.
Open raktim2015 opened 4 years ago
rapiz1
commented
4 years ago As far as I am considered, it will be convenient if we can have this procedure.
rapiz1
commented
4 years ago As you mentioned, using find() to implement this procedure is costly. But the reason why it's costly is that find() itself is now implemented by brute force. If it can be improved, then a efficient find_all will be easy to implement. So I think you can start from here:
https://github.com/chapel-lang/chapel/blob/eab0615591f9f40cbf495d5db1e50e43492a14f4/modules/internal/String.chpl#L1455-L1461
 raktim2015
commented
4 years ago
raktim2015
commented
4 years ago @Rapiz1 Hi. Thanks for your response. For finding single occurrence of the needle, the implementation of find will take O(n). I have implemented an efficient version of findAll using KMP search (the performance is plotted in blue line). Please take a look at the gist link for source code.
raktim2015
commented
4 years ago @Rapiz1 I will start implementing Boyer-Moore-Horspool as it is better than KMP search for pattern of longer length. But for finding single occurrence of a needle, I think the current implementation is better as there is no pre-computation and will perform faster consuming less space. Moreover, find() returns a single index but findAll() need to take care of more than one. Please suggest how can we achieve that if we are planning to integrate findAll() within search_helper() ?
rapiz1
commented
4 years ago @Rapiz1 I will start implementing Boyer-Moore-Horspool as it is better than KMP search for pattern of longer length. But for finding single occurrence of a needle, I think the current implementation is better as there is no pre-computation and will perform faster consuming less space. Moreover,
find()returns a single index butfindAll()need to take care of more than one. Please suggest how can we achieve that if we are planning to integratefindAll()withinsearch_helper()?
The time complexity of the brute-force string matching, which currently applied, is O(NM), where N,M are respectively the lengths of target and pattern. Consider the target aaaaaa...aaa and the pattern aaaaaa....b. Finding a single occurrence can also be very slow now.
As for integrating findAll() within _search_helper(), maybe we can change the param count to some enum to represent intent, for example, enum {find, count, count_idx}. In this way, with a little modification, the improved algorithm can also benefit count() and other procedures that may call _search_helper() in the future.
raktim2015
commented
4 years ago @Rapiz1 Thanks a lot! I will try to implement in the following fashion. I will get back to you soon.
rapiz1
commented
4 years ago You are welcome. I am just trying to be helpful : )
raktim2015
commented
4 years ago @Rapiz1 What should be the return type of search_helper if we were to integrate find(), findAll(), rfind() and count() together?
rapiz1
commented
4 years ago @raktim2015 I think a tuple including an int and an array can be used. If the array is not needed, just leave it empty. Or we can pass an additional argument to store all the positions. But I'm not sure if it is elegant. Maybe there is another way to do it.
raktim2015
commented
4 years ago @Rapiz1 How about returning only an array from the _search_helper() function? We can return what is needed based on from which function I am invoking the _search_helper(). For example :-
Using search helper() in count() will return array[0] which stores only the count of the elements.
rfind() will return array[array.size - 1] etc
rapiz1
commented
4 years ago @raktim2015 Sounds great :+1:
raktim2015
commented
4 years ago @Rapiz1
inline proc _search_helper(funct="find", needle: string, region: range(?), param count: bool, param fromLeft: bool = true)
This could be the function parameters where funct will take the operation to be performed. I believe there will be very less interference with the original functionality and almost no changes needed.
 ben-albrecht
commented
4 years ago
ben-albrecht
commented
4 years ago @raktim2015 - is there precedent for a library string method like this in other language standard libraries? If so, what do those interfaces look like? Thanks!
raktim2015
commented
4 years ago @ben-albrecht I have to check for other languages. As far as C++ is concerned, iterator and generic templates does the work. C++ uses optional parameters to deal with similar issues. For example, in case of sort sort(arr,arr+n) is for non-decreasing sort and sort(arr,arr+n, greater <type>()) for decreasing. The above mentioned structure is somewhat having same structure.
I think it's better to make necessary changes in internal structure only after deciding the design.
ben-albrecht
commented
4 years ago @raktim2015 - To clarify, I'm asking if other language standard libraries provide a string method similar to findAll(). If so, posting links to their documentation and/or snippet examples of them could help us determine:
1) If this something we want to add to Chapel standard library 2) What the interface should look like in Chapel standard library
raktim2015
commented
4 years ago @ben-albrecht Sorry for misinterpreting. It is present in Boost C++ library. https://www.boost.org/doc/libs/1_55_0/boost/algorithm/searching/knuth_morris_pratt.hpp Unfortunately, I didn't find it as a part of standard library in widely used programming languages.
rapiz1
commented
4 years ago @raktim2015 What about helping with improving _search_helper? It's brute-force now.
raktim2015
commented
4 years ago @Rapiz1 We need to decide a design before moving on with the implementation. I have already written a skeleton code for the same but need a few additions depending on the design decided by the community.
ben-albrecht
commented
4 years ago Unfortunately, I didn't find it as a part of standard library in widely used programming languages.
This makes me less certain that it should be a part of our standard library, rather than a mason package.
Check out the design guidelines for understanding the process of getting the design approved. @e-kayrakli may be a good person to give input, but they probably won't have much time until after the release code freezes (https://chapel-lang.org/events.html).
 e-kayrakli
commented
4 years ago
e-kayrakli
commented
4 years ago Sorry for being late to the party!
This makes me less certain that it should be a part of our standard library, rather than a mason package.
I agree with this. It would be interesting having a StringUtils or a StringAlgorithms package, for example, if we can find several such "advanced" tools that are used in common string operations. findAll would be a good start for that.
That being said, we have string.count and I believe other languages must have it, too. And string.count is basically a find-all operation, only that it doesn't return the indices of needles. So, we can have this algorithm (or any non-brute alternative) in our standard library, without exposing it through something like findAll. If that's the case, though, I'd want more time to stew on whether we want to break precedence and have it in our standard library, just because the implementation is already there. I'd look at how Python's str.count is implemented, and whether they use that algorithm elsewhere. Maybe they have a "find-all" functionality but it is named totally different?
Regardless, I rather discuss the design of the findAll interface, than how to implement it at this point. Once we have the design, the implementation could happen anywhere, really. _search_helper is an internal helper that is not user-facing, if we need to change it is signature, for example, we can do it with much less discussion. But whatever design choices we make here can also go to a mason package.
Below, I am copy/pasting an edited version of my list of design questions that I asked initially under your gist. (Since it is less public, the discussion veered off to implementation discussion, IMHO)
string.count and also a function in a mason package?param argument to string.find to control this behavior.string.find.bytes?
bytes.find implementation because of subtleties with handling codepoints vs bytes.string.count and a string.rfind that currently use the same helper with string.find. raktim2015
commented
4 years ago @e-kayrakli Sorry for late reply. It will be great if we can have such a Util package and I am excited to add new algorithms to it. I will be adding this in my task list for GSoC!
 parthsarthiprasad
commented
4 years ago
parthsarthiprasad
commented
4 years ago @raktim2015 @e-kayrakli I wanted your help in this regarding find all , I was also following the issue and two possible implementation algorithm that seems to mind are KMP and boyer moore horspool algorithm , Which quite work the same way in preprocessing , but horspool might result in faster result if we run benchmarking test for longer bytesequences .
KMP Algorithm :- prefix function with KMP. Time complexity O(n) where n = size of the given string.
Horspool Algorithm :- boyer bad character shift array with boyer moore horspool algorithm. preprocessing phase is O(m+k) time and O(k) space complexity where m = length of pattern , n = length of string k = numchar = 256 worst-case performance O(mn), average time is O(n) best case = sub-linear
 Source of Graph http://www.mathcs.emory.edu/~cheung/Courses/323/Syllabus/Text/Matching-Boyer-Moore2.html
Source of Graph http://www.mathcs.emory.edu/~cheung/Courses/323/Syllabus/Text/Matching-Boyer-Moore2.html
I've tried to work on same, using https://www.boost.org/doc/libs/1_59_0/libs/algorithm/doc/html/the_boost_algorithm_library/Searching/BoyerMooreHorspool.html
Here is the gist of horspool algorithm for findall : https://gist.github.com/parthsarthiprasad/48e8e22de534df24bd46fd8bea9c4971
I Will try benchmarking and comparing If we can consider these two algorithms for further working of findall() implementation, adding as @Rapiz1 said about brute force approach in find() needs to be optimized , and can be changed to be implemented as horspool algorithm
e-kayrakli
commented
4 years ago Just to record one more notion here: An efficient implementation of something like findAll can also help string.replace performance. The way I currently see it; we can have some efficient implementation internally first and use it in the existing routines. This would be a good way for correctness checking and making sure that the algorithm can really help the performance. Soon after we have the algorithm in the modules (and grow confident in it), we can discuss having it in the string/bytes API, too. I do not have a strong opinion as of now, but if we are maintaining the code, we can expose it with some interface, too.
Hello, I would like to add a procedure
findAll()which can find all occurrences of a needle within a target string. Implementing such procedure naively usingfind()is costly. The algorithm used here uses prefix function and KMP search which brings down the complexity to O(n) where n = length of target string.Procedure header :-
inline proc findAll(needle: string, region: range(?) = 1:byteIndex..): []Procedure can be invoked asvar x = target.findAll(needle,range);where range is an optional parameter. It returns an array ofinthaving all occurrences of needle sorted in increasing order (1 based indexing).Comparison between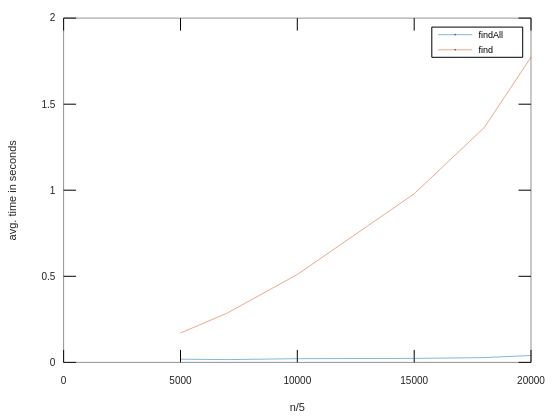
find()andfindAll():-Multibyte is not supported in its current implementation.
Source code along with benchmarks are listed in :- https://gist.github.com/raktim2015/bc35749a7fed96064aa33d89af4e63c0
Thanks, Raktim Malakar