 jchodera
commented
8 years ago
jchodera
commented
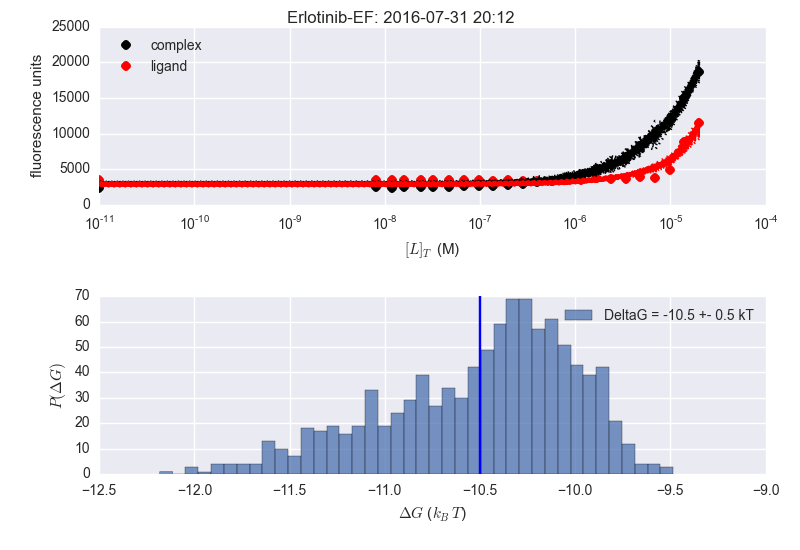
8 years ago I'm supre-confused as to why the results are inconsistent for erlotinib. There's no way the average DeltaG is -11.5 kT in that lower right panel---just look at the histogram!
I wonder if the maximum likelihood estimate---rather than the mean of the MCMC sampler history---is being reported as -11.5?
 sonyahanson
sonyahanson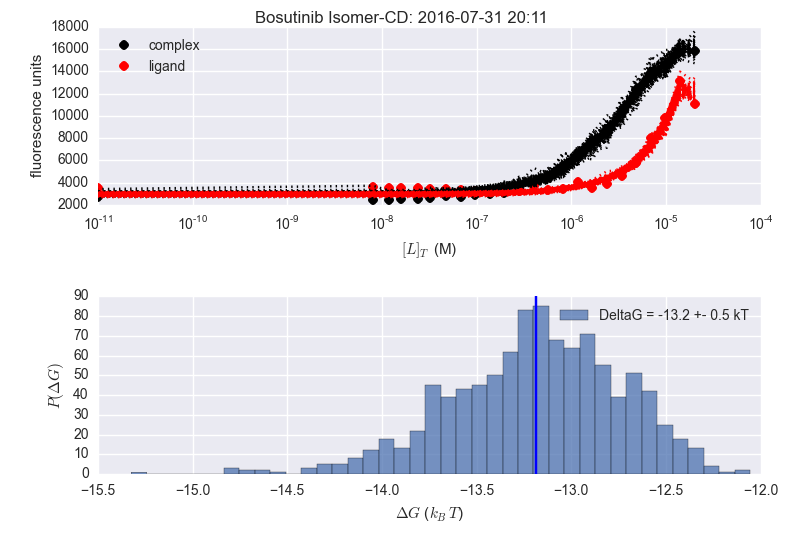


I'm currently writing a interface that quick analyses, stores, and makes a figure of results for bayesian analysis, and noticed that for our the simple pymc model function, we aren't getting consistent results when rerunning the analysis:
I mentioned these inconsistencies in my last labmeeting, and this is a big reason why I've started working on #56, but just thought I'd post it here as well, since it's coming up again.
In the image below the two adjacent plots are from the same dataset, but the analysis is done at different times (notice time stamp). The plotting is slightly different (delG in title vs. in legend) as this is what I was playing with when repeating the analysis. Seems to be fine for Bosutinib Isomer, but not for Erlotinib (sorry the image is a bit fuzzy...).
Currently parameters for MCMC sampling are: